Pandas Dataframe操作
tigeriaf 人气:0一、查询操作
可以使用Dataframe的index属性和columns属性获取行、列索引。
import pandas as pd
data = {"name": ["Alice", "Bob", "Cindy", "David"], "age": [25, 23, 28, 24], "gender": ["woman", "man", "woman", "man"]}
df = pd.DataFrame(data)
print(df.index)
print(df.columns)
df
结果输出如下:

元素的查询
DataFrame 元素查询有一下几种查询方式:使用[]切片、loc方法、iloc方法、at方法、iat方法等,下面分别介绍一下。
使用[]切片:
和Series数据结果一样,Dataframe也支持使用[]进行切片,使用方式也类似,通过行、列的下标或名称进行指定位置元素的查询。
例如:
# 获取第0行数据 df[0:1] # 获取第2-4行数据(不包括4) df[2:4] # 获取某一列 df.name # df["name"] # 获取某几列 df[["name", "gender"]] # 获取指定行指定列 df[2:4][["name", "gender"]]
通过loc方法和iloc方法:
其中loc方法是以行索引的名称和列索引的名称作为参数使用,iloc方法是以行索引的位置和列索引的位置作为参数使用,具体使用方式如下:
# 获取某行 df.loc[1] df.iloc[1] # 获取多行 df.loc[1:3] df.iloc[1:3] # 获取某列 df.loc[:, "name"] df.iloc[:, 0] # 获取多列 df.loc[:, ["name","gender"]] df.iloc[:, [0,2]]
除了上面这些, 这里有一点需要注意一下,就是使用loc方法行索引参数为区间时,区间前后都为闭区间;而iloc为前闭后开区间。
通过at方法和iat方法:
at和iat的使用方法与loc和iloc类似,不同的是,at和iat只能访问单个元素,不能访问多个元素,但是查询速度比loc和iloc更快一些,具体使用如下:
# 查询index为0列名为name的元素 df.at[0, "name"] # 查询第2行第1列的元素 df.iat[2,1]
说完Dataframe的查询操作,这篇文章就来介绍一下Dataframe数据的修改及删除操作。
二、修改操作
行列索引的修改
Dataframe对象提供了rename()方法修改行索引、列索引,默认修改行索引,可以指定columns参数修改列索引,
具体使用方法如下:
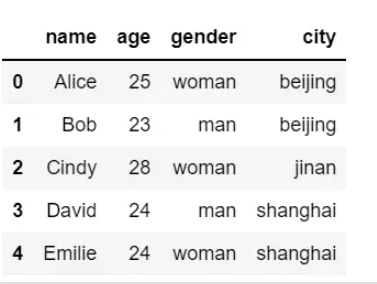
# 修改指定行索引
df.rename({1:"one", 2:"two"}, inplace=True)
# 修改指定列索引
df.rename(columns={"city": "address"}, inplace=True)
df结果输出如下:
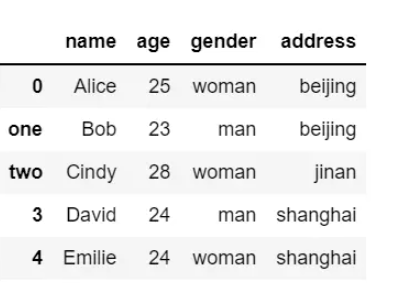
参数inplace=True表示在原来的 DataFrame 上进行修改。
元素值的修改
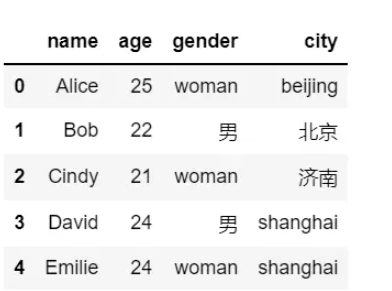
上面查询操作说到说到可以通过loc、iloc、at、iat等方法获取指定位置的值,修改其实也是通过这些方法先指定某个位置,然后进行赋值即可修改,例如:
# 修改1-2行age和city列的数据 df.loc[1:2, ["age","city"]] = [["22", "北京"],["21", "济南"]] # 修改gender列 man-->男 df.loc[df["gender"]=="man", "gender"] = "男" df
输出结果如下:
三、行和列的删除操作
DataFrame提供了drop()方法进行行和列的删除操作。
具体用法和参数如下:
df.drop(labels=None, axis=0, index=None, columns=None, inplace=False)
- labels:指定要删除的行或列,可以使用列表指定多个行/列索引
- axis:取值为0和1,代表行和列,默认为0,表示要删除的是行,设置为1表示删除列
- index:指定要删除的行,可以使用列表指定多个行索引
- columns:指定要删除的列,同样可以使用列表指定多个列索引
- inplace:默认为False,设置为True表示在原 DataFrame 上进行修改
具体通过代码看下:
# 删除单行 df.drop(4, inplace=True) # 删除多行 df.drop([1,3], inplace=True) # 删除多列 df.drop(["gender","city"], axis=1, inplace=True) # 或 df.drop(columns=["genger","city"], inplace=True) df
加载全部内容