python爬虫之request模块
xiaochuhe. 人气:2一、概述
在后期渗透测试中,经常会遇到需要向第三方发送http请求的场景,python中的requests库可以很好的满足这一要求,Requests模块是一个用于网络请求的模块,主要用来模拟浏览器发请求。其实类似的模块有很多,比如urllib,urllib2,httplib,httplib2,他们基本都提供相似的功能。但是这些模块都复杂而且差不多过时了,requests模块简单强大高效,使得其在众多网络请求模块中脱引而出。
二、安装和基本步骤使用
环境安装:pip install requests
基本步骤:.
1.导入模块:import requests
2.指定url:url = "........"
3.基于requests模块发送请求:res = requests.get(url)
4.获取响应对象中的数据值:print(res.'...')
5.持久化存储(不是必须的)
三、http知识复习
(一)八种请求方式:GET、 POST、 HEAD、OPTIONS、 PUT、 DELETE、 TRACE、 CONNECT。
这里我只详细介绍get和post:
1.GET
用于获取资源,当采用 GET 方式请求指定资源时, 被访问的资源经服务器解析后立即返回响应内容。通常以 GET 方式请求特定资源时, 请求中不应该包含请求体,所有需要向被请求资源传递的数据都应该通过 URL 向服务器传递。
2. POST
POST 动作:用于提交数据, 当采用 POST 方式向指定位置提交数据时,数据被包含在请求体中,服务器接收到这些数据后可能会建立新的资源、也可能会更新已有的资源。同时 POST 方式的请求体可以包含非常多的数据,而且格式不限。因此 POST 方式用途较为广泛,几乎所有的提交操作都可以使用 POST 方式来完成。
注:虽然用 GET 方式也可以提交数据,但一般不用 GET 方式而是用 POST 方式。在 HTTP协议中,建议 GET 方式只用来获取数据,而 POST 方式则用来提交数据(而不是获取数据)。
get方式和post方式区别:
简单来说,本质上区别:
- GET产生 一个 TCP数据包
- POST产生 两个 TCP数据包
对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据);
而对于POST,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok(返回数据)。
(二)http常见请求参数
url:请求url地址
headers:请求头
data:发送编码为表单形式的数据
params:查询字符串
host:请求web服务器的域名地址
User-Agent:HTTP客户端运行的浏览器类型的详细信息。通过该头部信息,web服务器可以判断到当前HTTP请求的客户端浏览器类别。
Accept:指定客户端能够接收的内容类型,内容类型中的先后次序表示客户端接收的先后次序。
Accept-Encoding:指定客户端浏览器可以支持的web服务器返回内容压缩编码类型。
Accept-Language:指定HTTP客户端浏览器用来展示返回信息所优先选择的语言
Connection:表示是否需要持久连接。如果web服务器端看到这里的值为“Keep-Alive”,或者看到请求使用的是HTTP 1.1(HTTP 1.1默认进行持久连接),表示连接持久有效,是不会断开的
cookie:HTTP请求发送时,会把保存在该请求域名下的所有cookie值一起发送给web服务器。
Refer:包含一个URL,用户从该URL代表的页面出发访问当前请求的页面
四、request请求模块的方法使用
举例说明:爬取我个人网站的数据
import requests #导入request模块
url = "http://42.192.212.170/" #指定url为我个人的网站
r = requests.get(url) #基于request模块给我个人url网站发送请求
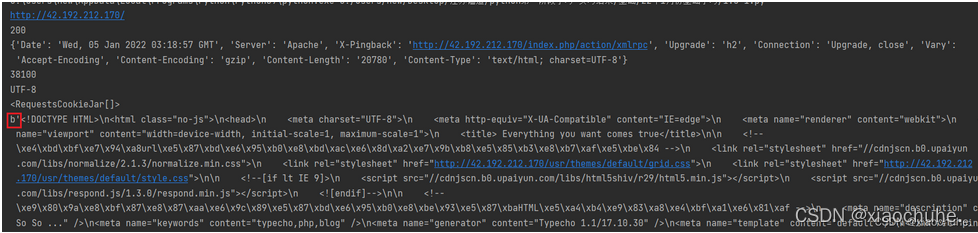
print (r.url) #获取响应包地址
print (r.status_code) #获取响应包的状态码
print (r.headers) #获取响应包的头部信息
print (len(r.text)) #获取以文本形式下响应包的长度
print (r.encoding) #获取网页编码方式
print (r.cookies) #获取响应包的cookie值
print (r.content) #以字节形式返回响应体,会自动解码成gzip和deflate压缩输出结果:
当然也可以用下面几种请求方法:
1.requests.post(“http://httpbin.org/post”) # POST请求
2.requests.put(“http://httpbin.org/put”) # PUT请求
3.requests.delete(“http://httpbin.org/delete”) # DELETE请求
4.requests.head(“http://httpbin.org/get”) # HEAD请求
5.requests.options(“http://httpbin.org/get” ) # OPTIONS请求
requests响应参数说明:
r.encoding #获取当前的编码
r.encoding = 'utf-8' #设置编码
r.text #以encoding解析返回内容。字符串方式的响应体,会自动根据响应头部的字符编码进行解码。
r.content #以字节形式(二进制)返回。字节方式的响应体,会自动为你解码 gzip 和 deflate 压缩。
r.headers #以字典对象存储服务器响应头,但是这个字典比较特殊,字典键不区分大小写,若键不存在则返回
r.status_code #响应状态码五,params和payload参数使用说明
举例说明:
import requests #导入request模块
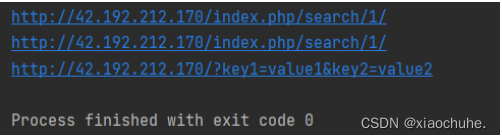
r1 = requests.get("http://42.192.212.170/",params={'s':'1'} ) #params字符串传参变量s为1
print (r1.url)
payload1 = {'s':'1'} #设置payload参变量s为1
r2 = requests.get("http://42.192.212.170/",params=payload1) #将params设为payload1
print (r2.url)
payload2 = {'key1':"value1",'key2':'value2'} #设置payload参变量key1为value1并且变量key2为value2
r3 = requests.get("http://42.192.212.170/",params=payload2) #params设为payload2
print (r3.url)输出结果:
总结
加载全部内容