Python抖音热搜爬取
Python丁小杰 人气:0大家好,我是丁小杰。
上次和大家分享了Python定时爬取微博热搜示例介绍,堪称摸鱼神器,一个热榜不够看?今天我们再来爬取一下抖音热搜榜,感兴趣的小伙伴可以自己动手尝试一下哦。
抖音热搜榜
链接:https://tophub.today/n/K7GdaMgdQy
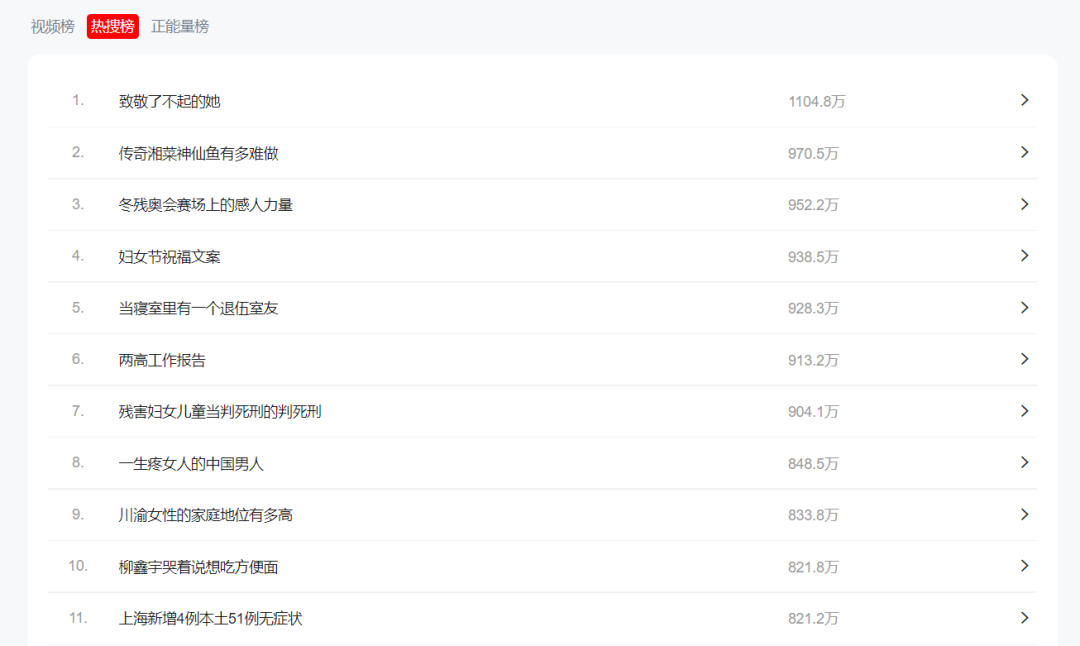
整个热榜共50条数据,本次爬取的内容:排名、热度、标题、链接。
requests 爬取
requests 是一种非常简单的方法,由于该页面没有反爬措施,所以直接get 请求页面即可。
import requests
import pandas as pd
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.54 Safari/537.36'
}
url = 'https://tophub.today/n/K7GdaMgdQy'
page_text = requests.get(url=url, headers=headers).text
page_text

可以看到,只需要几行代码,数据就很轻松地获取到了。
selenium 爬取
将selenium设置为无头浏览器,打开指定url获取页面数据。
from selenium import webdriver
option = webdriver.ChromeOptions()
option.add_argument('--headless')
driver = webdriver.Chrome(options=option)
url = 'https://tophub.today/n/K7GdaMgdQy'
driver.get(url)
page_text = driver.page_source
两种爬取方法都能够成功获取到数据,但requests相对简洁,整个代码运行速度也更快,如果页面数据不是动态加载的话,用requests相对方便。
数据解析
现在用lxml库解析我们爬取的数据,并保存到excel中。
tree = etree.HTML(page_text)
tr_list = tree.xpath(
'//*[@id="page"]/div[2]/div[2]/div[1]/div[2]/div/div[1]/table/tbody/tr')
df = pd.DataFrame(columns=['排名', '热度', '标题', '链接'])
for index, tr in enumerate(tr_list):
hot = tr.xpath('./td[3]/text()')[0]
title = tr.xpath('./td[2]/a/text()')[0]
article_url = tr.xpath('./td[2]/a/@href')[0]
df = df.append({
'排名': index + 1,
'热度': hot,
'标题': title,
'链接': article_url}, ignore_index=True)
df['链接'] = 'https://tophub.today' + df['链接']
df
运行结果

设置定时运行
至此,爬取代码已经完成,想要实现每小时自动运行代码,可以使用任务计划程序。
打开任务计划程序,【创建任务】
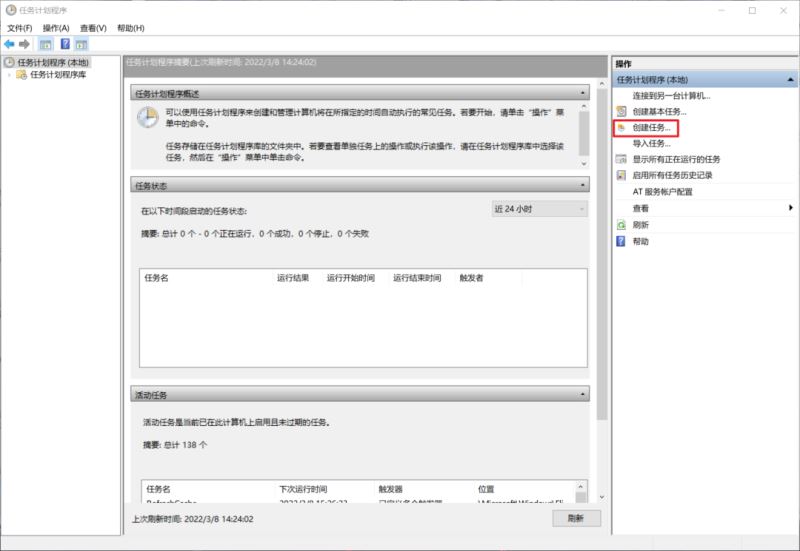
输入名称,名称随便起就好。
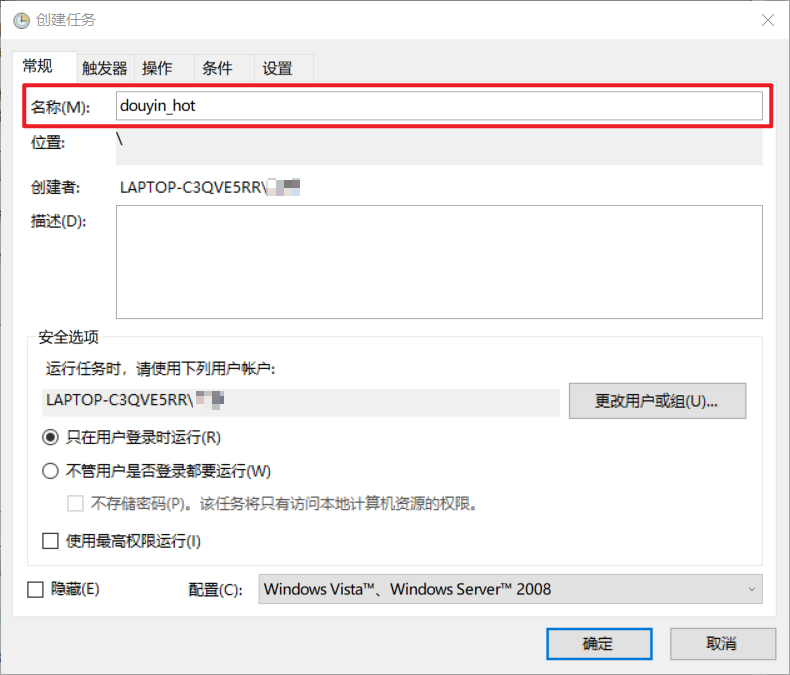
选择【触发器】>>【新建】>>【设置触发时间】
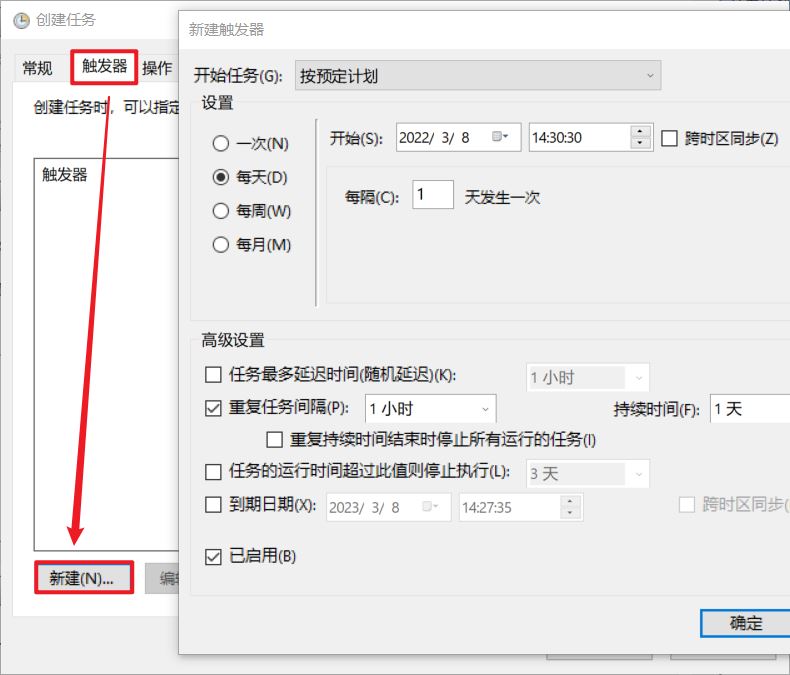
选择【操作】>>【新建】>>【选择程序】
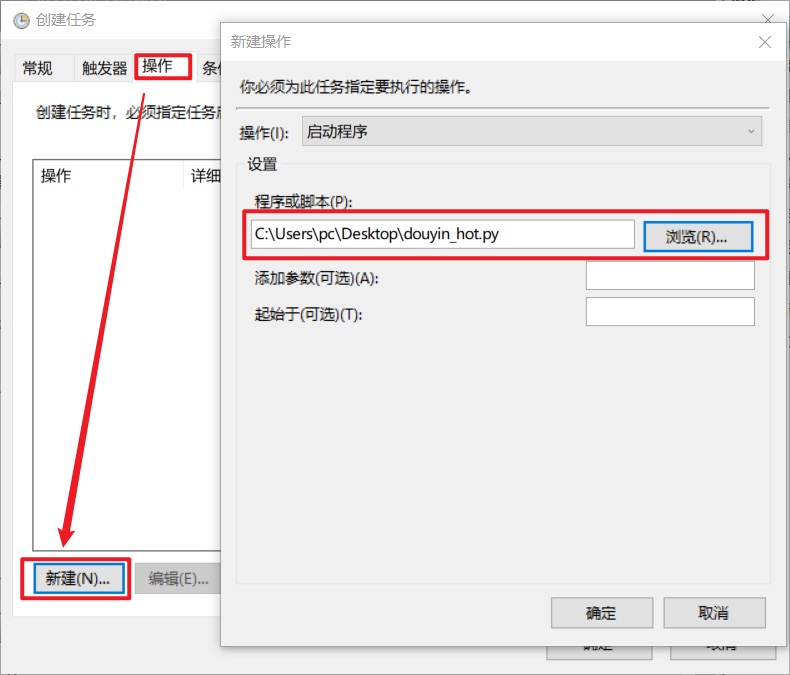
最后确认即可。到时间就会自动运行,或者右键任务手动运行。
这就是今天要分享的内容,整体难度不大,希望大家能够有所收获,文章中的代码拼接起来就可以运行!
加载全部内容