java Stream管道流状态与并行操作
字母哥哥 人气:0一、回顾Stream管道流操作

通过前面章节的学习,我们应该明白了Stream管道流的基本操作。我们来回顾一下:
- 源操作:可以将数组、集合类、行文本文件转换成管道流Stream进行数据处理
- 中间操作:对Stream流中的数据进行处理,比如:过滤、数据转换等等
- 终端操作:作用就是将Stream管道流转换为其他的数据类型。这部分我们还没有讲,我们后面章节再介绍。
看下面的脑图,可以有更清晰的理解:
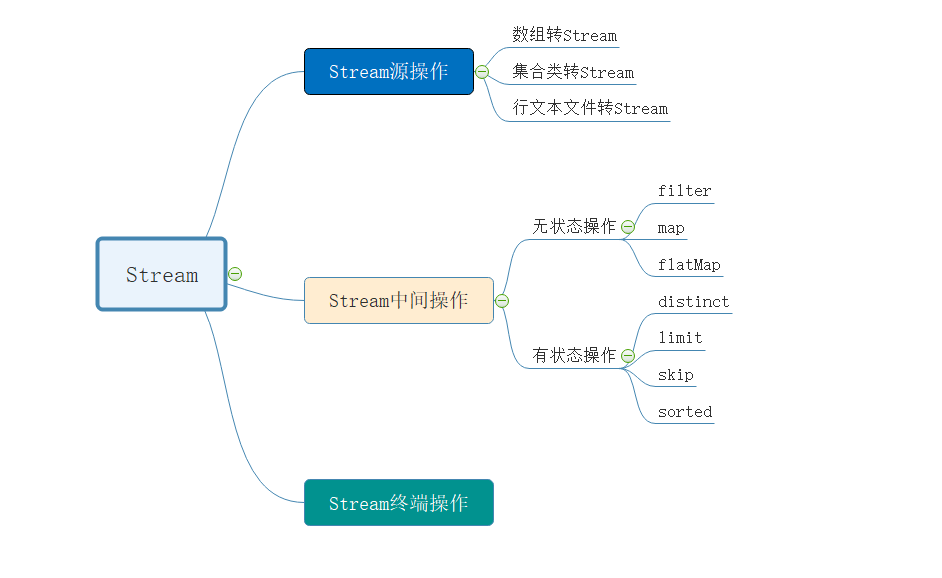
二、中间操作:有状态与无状态
其实在程序员编程中,经常会接触到“有状态”,“无状态”,绝大部分的人都比较蒙。而且在不同的场景下,“状态”这个词的含义似乎有所不同。但是“万变不离其宗”,理解“状态”这个词在编程领域的含义,笔者教给大家几个关键点:
- 状态通常代表公用数据,有状态就是有“公用数据”
- 因为有公用的数据,状态通常需要额外的存储。
- 状态通常被多人、多用户、多线程、多次操作,这就涉及到状态的管理及变更操作。
是不是更蒙了?举个例子,你就明白了
web开发session就是一种状态,访问者的多次请求关联同一个session,这个session需要存储到内存或者redis。多次请求使用同一个公用的session,这个session就是状态数据。
vue的vuex的store就是一种状态,首先它是多组件公用的,其次是不同的组件都可以修改它,最后它需要独立于组件单独存储。所以store就是一种状态。
回到我们的Stream管道流
filter与map操作,不需要管道流的前面后面元素相关,所以不需要额外的记录元素之间的关系。输入一个元素,获得一个结果。
sorted是排序操作、distinct是去重操作。像这种操作都是和别的元素相关的操作,我自己无法完成整体操作。就像班级点名就是无状态的,喊到你你就答到就可以了。如果是班级同学按大小个排序,那就不是你自己的事了,你得和周围的同学比一下身高并记住,你记住的这个身高比较结果就是一种“状态”。所以这种操作就是有状态操作。
三、Limit与Skip管道数据截取
List<String> limitN = Stream.of("Monkey", "Lion", "Giraffe", "Lemur")
.limit(2)
.collect(Collectors.toList());
List<String> skipN = Stream.of("Monkey", "Lion", "Giraffe", "Lemur")
.skip(2)
.collect(Collectors.toList());limt方法传入一个整数n,用于截取管道中的前n个元素。经过管道处理之后的数据是:[Monkey, Lion]。skip方法与limit方法的使用相反,用于跳过前n个元素,截取从n到末尾的元素。经过管道处理之后的数据是: [Giraffe, Lemur]
四、Distinct元素去重
我们还可以使用distinct方法对管道中的元素去重,涉及到去重就一定涉及到元素之间的比较,distinct方法时调用Object的equals方法进行对象的比较的,如果你有自己的比较规则,可以重写equals方法。
List<String> uniqueAnimals = Stream.of("Monkey", "Lion", "Giraffe", "Lemur", "Lion")
.distinct()
.collect(Collectors.toList());上面代码去重之后的结果是: ["Monkey", "Lion", "Giraffe", "Lemur"]
五、Sorted排序
默认的情况下,sorted是按照字母的自然顺序进行排序。如下代码的排序结果是:[Giraffe, Lemur, Lion, Monkey],字数按顺序G在L前面,L在M前面。第一位无法区分顺序,就比较第二位字母。
List<String> alphabeticOrder = Stream.of("Monkey", "Lion", "Giraffe", "Lemur")
.sorted()
.collect(Collectors.toList());排序我们后面还会给大家详细的讲一讲,所以这里暂时只做一个了解。
六、串行、并行与顺序
通常情况下,有状态和无状态操作不需要我们去关心。除非?:你使用了并行操作。
还是用班级按身高排队为例:班级有一个人负责排序,这个排序结果最后就会是正确的。那如果有2个、3个人负责按大小个排队呢?最后可能就乱套了。一个人只能保证自己排序的人的顺序,他无法保证其他人的排队顺序。
- 串行的好处是可以保证顺序,但是通常情况下处理速度慢一些
- 并行的好处是对于元素的处理速度快一些(通常情况下),但是顺序无法保证。这可能会导致进行一些有状态操作的时候,最后得到的不是你想要的结果。
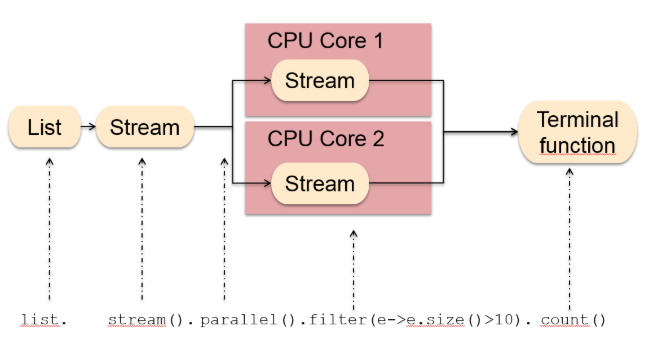
Stream.of("Monkey", "Lion", "Giraffe", "Lemur", "Lion")
.parallel()
.forEach(System.out::println);parallel()函数表示对管道中的元素进行并行处理,而不是串行处理。但是这样就有可能导致管道流中后面的元素先处理,前面的元素后处理,也就是元素的顺序无法保证。
如果数据量比较小的情况下,不太能观察到,数据量大的话,就能观察到数据顺序是无法保证的。
Monkey
Lion
Lemur
Giraffe
Lion
通常情况下,parallel()能够很好的利用CPU的多核处理器,达到更好的执行效率和性能,建议使用。但是有些特殊的情况下,parallel并不适合:深入了解请看这篇文章: https://blog.oio.de/2016/01/22/parallel-stream-processing-in-java-8-performance-of-sequential-vs-parallel-stream-processing/
该文章中几个观点,说明并行操作的适用场景:
数据源易拆分:从处理性能的角度,parallel()更适合处理ArrayList,而不是LinkedList。因为ArrayList从数据结构上讲是基于数组的,可以根据索引很容易的拆分为多个。
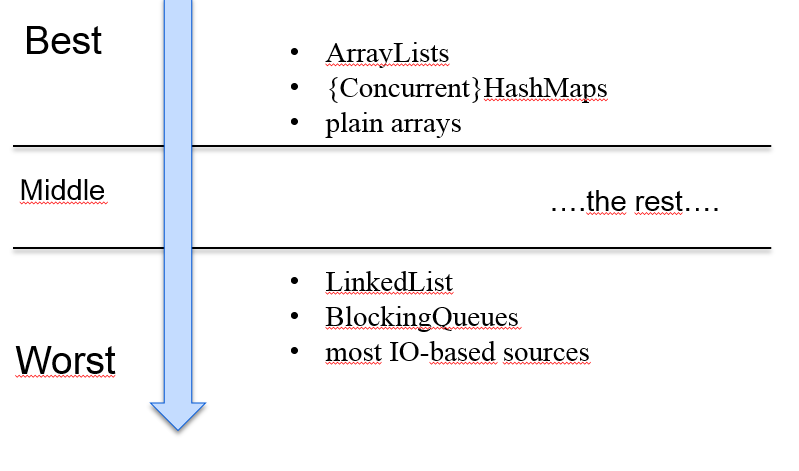
适用于无状态操作:每个元素的计算都不得依赖或影响任何其他元素的计算,的运算场景。基础数据源无变化:从文本文件里面边读边处理的场景,不适合parallel()并行处理。parallel()一开始就容量固定的集合,这样能够平均的拆分、同步处理。
加载全部内容