Mysql索引最左前缀原则
码农研究僧 人气:0前言
之所以有这个最左前缀索引
归根结底是mysql的数据库结构 B+树
在实际问题中 比如
索引index (a,b,c)有三个字段,
使用查询语句select * from table where c = '1' ,sql语句不会走index索引的
select * from table where b =‘1’ and c ='2' 这个语句也不会走index索引
1. 定义
最左前缀匹配原则:在MySQL建立联合索引时会遵守最左前缀匹配原则,即最左优先,在检索数据时从联合索引的最左边开始匹配
为了更好辨别这种情况,通过建立表格以及索引的情况进行分析
2. 全索引顺序
建立一张表,建立一个联合索引,如果顺序颠倒,其实还是可以识别的,但是一定要有它的全部部分
建立表
CREATE TABLE staffs(
id INT PRIMARY KEY AUTO_INCREMENT,
`name` VARCHAR(24) NOT NULL DEFAULT'' COMMENT'姓名',
`age` INT NOT NULL DEFAULT 0 COMMENT'年龄',
`pos` VARCHAR(20) NOT NULL DEFAULT'' COMMENT'职位',
`add_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT'入职时间'
)CHARSET utf8 COMMENT'员工记录表';
INSERT INTO staffs(`name`,`age`,`pos`,`add_time`) VALUES('z3',22,'manager',NOW());
INSERT INTO staffs(`name`,`age`,`pos`,`add_time`) VALUES('July',23,'dev',NOW());
INSERT INTO staffs(`name`,`age`,`pos`,`add_time`) VALUES('2000',23,'dev',NOW());
建立索引ALTER TABLE staffs ADD INDEX index_staffs_nameAgePos(name,age,pos);
索引的顺序位name-age-pos
显示其索引有没有show index from staffs;

通过颠倒其左右顺序,其执行都是一样的
主要的语句是这三句
explain select *from staffs where name='z3'and age=22 and pos='manager';explain select *from staffs where pos='manager' and name='z3'and age=22;explain select *from staffs where age=22 and pos='manager' and name='z3';
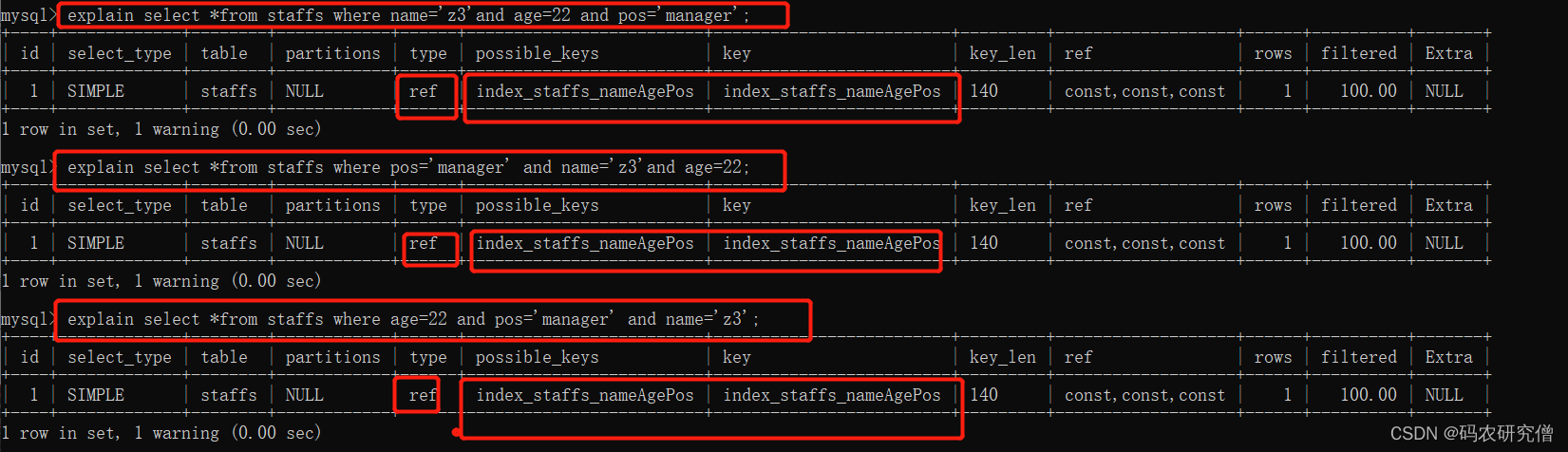
以上三者的顺序颠倒,都使用到了联合索引
最主要是因为MySQL中有查询优化器explain,所以sql语句中字段的顺序不需要和联合索引定义的字段顺序相同,查询优化器会判断纠正这条SQL语句以什么样的顺序执行效率高,最后才能生成真正的执行计划
不论以何种顺序都可使用到联合索引
3. 部分索引顺序
3.1 正序
如果是按照顺序(缺胳膊断腿的),都是一样的
explain select *from staffs where name=‘z3’;explain select *from staffs where name='z3’and age=22;explain select *from staffs where name='z3’and age=22;

其type都是ref类型,但是其字段长度会有微小变化,也就是它定义的字长长度变化而已
3.2 乱序
如果部分索引的顺序打乱
- 只查第一个索引
explain select *from staffs where name='z3'; - 跳过中间的索引
explain select *from staffs where name='z3' and pos='manager'; - 只查最后的索引
explain select *from staffs where pos='manager';

可以发现正序的时候
如果缺胳膊少腿,也是按照正常的索引
即使跳过了中间的索引,也是可以使用到索引去查询
但是如果只查最后的索引
type就是all类型,直接整个表的查询了(这是因为没有从name一开始匹配,直接匹配pos的话,会显示无序,)
有些时候type就是index类型,这是因为还是可以通过索引进行查询
index是对所有索引树进行扫描,而all是对整个磁盘的数据进行全表扫描
4. 模糊索引
类似模糊索引就会使用到like的语句
所以下面的三条语句
如果复合最左前缀的话,会使用到range或者是index的类型进行索引
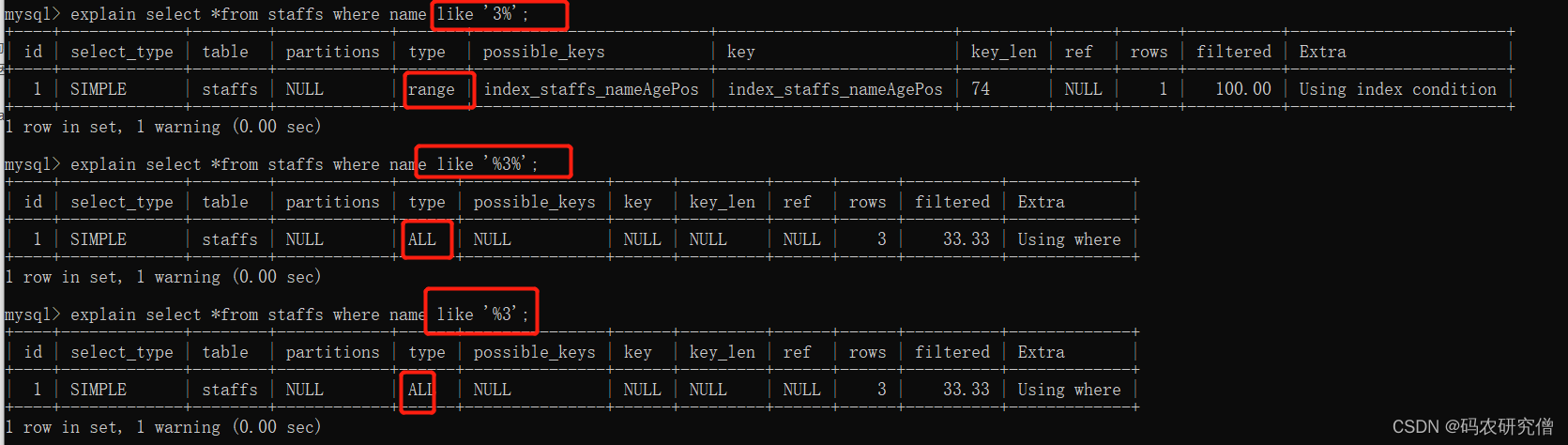
explain select *from staffs where name like '3%';最左前缀索引,类型为index或者rangeexplain select *from staffs where name like '%3%';类型为all,全表查询explain select *from staffs where name like '%3%';,类型为all,全表查询
5. 范围索引
如果查询多个字段的时候,出现了中间是范围的话,建议删除该索引,剔除中间索引即可
具体思路如下
建立一张单表
CREATE TABLE IF NOT EXISTS article( id INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT, author_id INT(10) UNSIGNED NOT NULL, category_id INT(10) UNSIGNED NOT NULL, views INT(10) UNSIGNED NOT NULL, comments INT(10) UNSIGNED NOT NULL, title VARCHAR(255) NOT NULL, content TEXT NOT NULL ); INSERT INTO article(author_id,category_id,views,comments,title,content) VALUES (1,1,1,1,'1','1'), (2,2,2,2,'2','2'), (1,1,3,3,'3','3');
经过如下查询:
explain SELECT id, author_id FROM article WHERE category_id = 1 AND comments > 1 ORDER BY views DESC LIMIT 1;

发现其上面的单表查询,不是索引的话,他是进行了全表查询,而且在extra还出现了Using filesort等问题
所以思路可以有建立其复合索引
具体建立复合索引有两种方式:
create index idx_article_ccv on article(category_id,comments,views);ALTER TABLE 'article' ADD INDEX idx_article_ccv ( 'category_id , 'comments', 'views' );
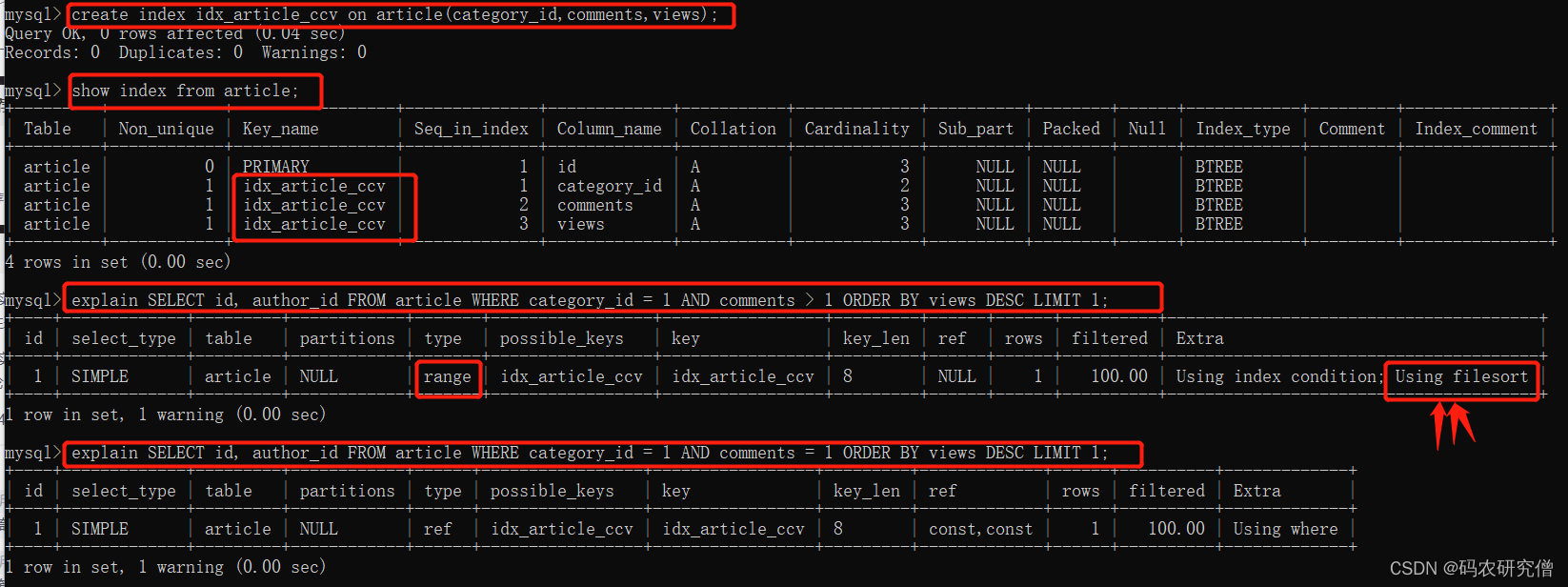
但这只是去除了它的范围,如果要去除Using filesort问题的话,还要将其中间的条件范围改为等于号才可满足
发现其思路不行,所以删除其索引 DROP INDEX idx_article_ccv ON article;

主要的原因是:
这是因为按照BTree索引的工作原理,先排序category_id,如果遇到相同的category_id则再排序comments,如果遇到相同的comments 则再排序views。
当comments字段在联合索引里处于中间位置时,因comments > 1条件是一个范围值(所谓range),MySQL无法利用索引再对后面的views部分进行检索,即range类型查询字段后面的索引无效。
所以建立复合索引是对的
但是其思路要避开中间那个范围的索引进去
只加入另外两个索引即可create index idx_article_cv on article(category_id, views);

总结
加载全部内容