Pandas保存csv
AI浩 人气:0方法一
import os
import pandas as pd
path = 'data/train/'
img_label_list=[]
testList = os.listdir(path)
for file in testList:
label='aa'
img_label_list.append([file, label])
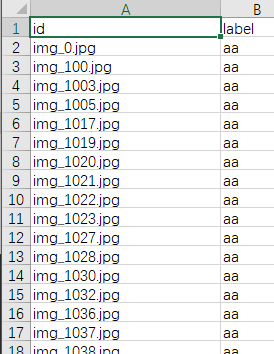
df1 = pd.DataFrame(data=img_label_list,
columns=['id', 'label'])
df1.to_csv('result.csv',index=False)
方法二
import os
import pandas as pd
path = 'data/train/'
img_list=[]
lable_list=[]
testList = os.listdir(path)
for file in testList:
img_list.append(file)
label='aa'
lable_list.append(label)
img_label_list2 = list(zip(img_list, lable_list))
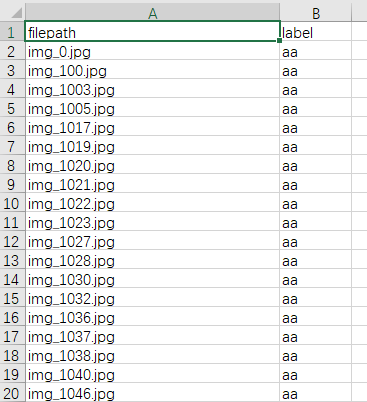
df3 = pd.DataFrame(data=img_label_list2,
columns=['filepath', 'label'])
df3.to_csv('result.csv',index=False)
方法三
import os
import pandas as pd
path = 'data/train/'
img_list=[]
lable_list=[]
testList = os.listdir(path)
for file in testList:
img_list.append(file)
label='aa'
lable_list.append(label)
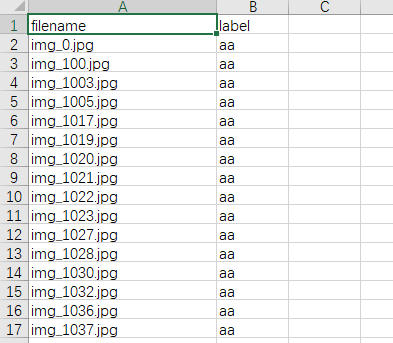
df = pd.DataFrame({"filename": img_list, "label": lable_list})
df.to_csv('result.csv',index=False)
补充
当然Pandas不仅可以实现CSV文件数据的保存,还能读写CSV文件,下面是实现的核心代码
使用pandas读取CSV
import pandas as pd
import csv
if name == '__main__':
# header=0——表示csv文件的第一行默认为dataframe数据的行名称,
# index_col=0——表示使用第0列作为dataframe的行索引,
# squeeze=True——表示如果文件只包含一列,则返回一个序列。
file_dataframe = pd.read_csv('../datasets/data_new_2/csv_file_name.csv', header=0, index_col=0, squeeze=True)
# 结果: 写CSV
stu1 = [lid, k, pre_count_data[k]]
# 打开文件,写模式为追加'a'
out = open('../results/write_file.csv', 'a', newline='')
# 设定写入模式
csv_write = csv.writer(out, dialect='excel')
# 写入具体内容
csv_write.writerow(stu1)加载全部内容