C语言 双向循环链表
李逢溪 人气:0一、本章重点
- 带头双向循环链表介绍
- 带头双向循环链表常用接口实现
- 实现接口总结
- 在线oj训练与详解
二、带头双向循环链表介绍
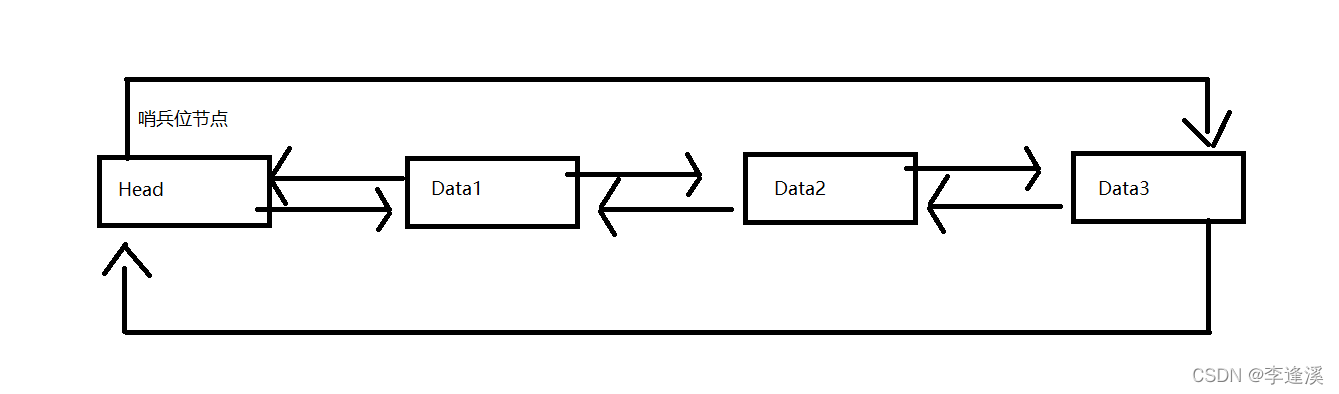
2.1什么是带头双向循环链表?
- 带头:存在一个哨兵位的头节点,该节点是个无效节点,不存储任何有效信息,但使用它可以方便我们头尾插和头尾删时不用判断头节点指向NULL的情况,同时也不需要改变头指针的指向,也就不需要传二级指针了。
- 双向:每个结构体有两个指针,分别指向前一个结构体和后一个结构体。
- 循环:最后一个结构体的指针不再指向NULL,而是指向第一个结构体。(单向)
- 第一个结构体的前指针指向最后一个结构体,最后一个结构体的后指针指向第一个结构体(双向)。
图解
2.2最常用的两种链表结构
- 更具有无头,单双向,是否循环组合起来有8种结构,但最长用的还是无头单向非循环链表和带头双向循环链表
- 无头单向非循环链表:结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结构的子结构,如哈希桶、图的邻接表等等。另外这种结构在笔试面试中出现很多。
- 带头双向循环链表:结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构,都是带头双向循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带来很多优势,实现反而简单了,后面我们代码实现了就知道了。
三、带头双向循环链表常用接口实现
3.1结构体创建
typedef int DataType;
typedef struct DListNode
{
DataType data;
DListNode* prev;
DListNode* next;
}DListNode;
3.2带头双向循环链表的初始化
void DListInint(DListNode** pphead)
{
*pphead = (DListNode*)malloc(sizeof(DListNode));
(*pphead)->next = (*pphead);
(*pphead)->prev = (*pphead);
}
或者使用返回节点的方法也能实现初始化
DListNode* DListInit()
{
DListNode* phead = (DListNode*)malloc(sizeof(DListNode));
phead->next = phead;
phead->prev = phead;
return phead;
}
3.3创建新节点
DListNode* BuyDListNode(DataType x)
{
DListNode* temp = (DListNode*)malloc(sizeof(DListNode));
if (temp == NULL)
{
printf("malloc fail\n");
exit(-1);
}
temp->prev = NULL;
temp->next = NULL;
temp->data = x;
return temp;
}
3.4尾插
void DListPushBack(DListNode* phead,DataType x)
{
DListNode* newnode = BuyDListNode(x);
DListNode* tail = phead->prev;
tail->next = newnode;
newnode->prev = tail;
newnode->next = phead;
phead->prev = newnode;
}
3.5打印链表
void DListNodePrint(DListNode* phead)
{
DListNode* cur = phead->next;
while (cur != phead)
{
printf("%d->", cur->data);
cur = cur->next;
}
printf("NULL\n");
}
3.6头插
void DListNodePushFront(DListNode* phead, DataType x)
{
DListNode* next = phead->next;
DListNode* newnode = BuyDListNode(x);
next->prev = newnode;
newnode->next = next;
newnode->prev = phead;
phead->next = newnode;
}
3.7尾删
void DListNodePopBack(DListNode* phead)
{
if (phead->next == phead)
{
return;
}
DListNode* tail = phead->prev;
DListNode* prev = tail->prev;
prev->next = phead;
phead->prev = prev;
free(tail);
tail = NULL;
}
3.8头删
void DListNodePopFront(DListNode* phead)
{
if (phead->next == phead)
{
return;
}
DListNode* firstnode = phead->next;
DListNode* secondnode = firstnode->next;
secondnode->prev = phead;
phead->next = secondnode;
free(firstnode);
firstnode = NULL;
}
3.9查找data(返回data的节点地址)
DListNode* DListNodeFind(DListNode* phead, DataType x)
{
DListNode* firstnode = phead->next;
while (firstnode != phead)
{
if (firstnode->data == x)
{
return firstnode;
}
firstnode = firstnode->next;
}
return NULL;
}
3.10在pos位置之前插入节点
void DListNodeInsert(DListNode* pos, DataType x)
{
DListNode* prev = pos->prev;
DListNode* newnode = BuyDListNode(x);
newnode->next = pos;
newnode->prev = prev;
prev->next = newnode;
pos->prev = newnode;
}
3.11删除pos位置的节点
void DListNodeErase(DListNode* pos)
{
DListNode* prev = pos->prev;
DListNode* next = pos->next;
prev->next = next;
next->prev = prev;
free(pos);
pos = NULL;
}
四、实现接口总结
- 多画图:能给清晰展示变化的过程,有利于实现编程。
- 小知识:head->next既可表示前一个结构体的成员变量,有可表示后一个结构体的地址。当head->next作为左值时代表的是成员变量,作右值时代表的是后一个结构体的地址。对于链表来说理解这一点非常重要。
- 实践:实践出真知
- 带头双向循环链表:相比于单链表,它实现起来更简单,不用向单链表一样分情况讨论链表的长度。虽然结构较复杂,但使用起来更简单,更方便。
五、在线oj训练与详解
链表的中间节点(力扣)
给定一个头结点为 head 的非空单链表,返回链表的中间结点。
如果有两个中间结点,则返回第二个中间结点。
输入:[1,2,3,4,5]
输出:此列表中的结点 3 (序列化形式:[3,4,5])
返回的结点值为 3 。 (测评系统对该结点序列化表述是 [3,4,5])。
注意,我们返回了一个 ListNode 类型的对象 ans,
这样:
ans.val = 3, ans.next.val = 4, ans.next.next.val = 5, 以及 ans.next.next.next = NULL.
来源:力扣(LeetCode)
思路:快慢指针
取两个指针,初始时均指向head,一个为快指针(fast)一次走两步,另一个为慢指针(slow)一次走一步,当快指针满足fast==NULL(偶数个节点)或者fast->next==NULL(奇数个节点)时,slow指向中间节点,返回slow即可。
struct ListNode* middleNode(struct ListNode* head)
{
struct ListNode* fast=head;
struct ListNode* slow=head;
while(fast&&fast->next)
{
fast=fast->next->next;
slow=slow->next;
}
return slow;
}
加载全部内容