Python数据清洗
Mr数据杨 人气:0许多数据科学家认为获取和清理数据的初始步骤占工作的 80%,花费大量时间来清理数据集并将它们归结为可以使用的形式。
因此如果你是刚刚踏入这个领域或计划踏入这个领域,重要的是能够处理杂乱的数据,无论数据是否包含缺失值、不一致的格式、格式错误的记录还是无意义的异常值。
将利用 Python 的 Pandas和 NumPy 库来清理数据。
准备工作
导入模块后就开始正式的数据预处理吧。
import pandas as pd import numpy as np
DataFrame 列的删除
通常会发现并非数据集中的所有数据类别都有用。例如可能有一个包含学生信息(姓名、年级、标准、父母姓名和地址)的数据集,但希望专注于分析学生成绩。在这种情况下地址或父母的姓名并不重要。保留这些不需要的数据将占用不必要的空间。
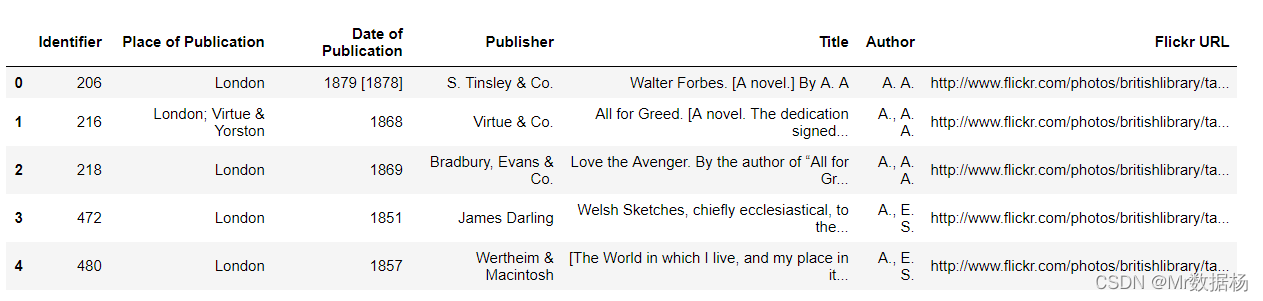
BL-Flickr-Images-Book.csv 数据操作。
df = pd.read_csv('数据科学必备Pandas、NumPy进行数据清洗/BL-Flickr-Images-Book.csv')
df.head()

可以看到这些列是对 Edition Statement, Corporate Author, Corporate Contributors, Former owner, Engraver, Issuance type and Shelfmarks 没有任何信息帮助的,因此可以进行批量删除处理。
to_drop_column = [ 'Edition Statement', 'Corporate Author', 'Corporate Contributors', 'Former owner', 'Engraver', 'Contributors', 'Issuance type', 'Shelfmarks'] df.drop(to_drop_column , inplace=True, axis=1) df.head()
DataFrame 索引更改
Pandas 索引扩展了 NumPy 数组的功能,以允许更通用的切片和标记。 在许多情况下,使用数据的唯一值标识字段作为其索引是有帮助的。
获取唯一标识符。
df['Identifier'].is_unique True
Identifier列替换索引列。
df = df.set_index('Identifier')
df.head()

206 是索引的第一个标签,可以使用 df.iloc[0] 基于位置的索引访问。
DataFrame 数据字段整理
清理特定列并将它们转换为统一格式,以更好地理解数据集并强制保持一致性。
处理 Date of Publication 出版日期 列,发现该数据列格式并不统一。
df.loc[1905:, 'Date of Publication'].head(10)
Identifier 1905 1888 1929 1839, 38-54 2836 1897 2854 1865 2956 1860-63 2957 1873 3017 1866 3131 1899 4598 1814 4884 1820 Name: Date of Publication, dtype: object
我们可以使用正则表达式的方式直接提取连续的4个数字即可。
extr = df['Date of Publication'].str.extract(r'^(\d{4})', expand=False)
extr.head()
Identifier
206 1879
216 1868
218 1869
472 1851
480 1857
Name: Date of Publication, dtype: object最后获取数字字段列。
df['Date of Publication'] = pd.to_numeric(extr)
str 方法与 NumPy 结合清理列
df[‘Date of Publication’].str 。 此属性是一种在 Pandas 中访问快速字符串操作的方法,这些操作在很大程度上模仿了对原生 Python 字符串或编译的正则表达式的操作,例如 .split()、.replace() 和 .capitalize()。
要清理 Place of Publication 字段,我们可以将 Pandas 的 str 方法与 NumPy 的 np.where 函数结合起来,该函数基本上是 Excel 的 IF() 宏的矢量化形式。
np.where(condition, then, else)
在这里 condition 要么是一个类似数组的对象,要么是一个布尔掩码。 then 是如果条件评估为 True 时使用的值,否则是要使用的值。
本质上 .where() 获取用于条件的对象中的每个元素,检查该特定元素在条件上下文中的计算结果是否为 True,并返回一个包含 then 或 else 的 ndarray,具体取决于哪个适用。可以嵌套在复合 if-then 语句中,允许根据多个条件计算值.
处理 Place of Publication 出版地 数据。
df['Place of Publication'].head(10) Identifier 206 London 216 London; Virtue & Yorston 218 London 472 London 480 London 481 London 519 London 667 pp. 40. G. Bryan & Co: Oxford, 1898 874 London] 1143 London Name: Place of Publication, dtype: object
使用包含的方式提取需要的数据信息。
pub = df['Place of Publication']
london = pub.str.contains('London')
london[:5]
Identifier
206 True
216 True
218 True
472 True
480 True
Name: Place of Publication, dtype: bool也可以使用 np.where 处理。
df['Place of Publication'] = np.where(london, 'London',
pub.str.replace('-', ' ')))
Identifier
206 London
216 London
218 London
472 London
480 London
...
4158088 London
4158128 Derby
4159563 London
4159587 Newcastle upon Tyne
4160339 London
Name: Place of Publication, Length: 8287, dtype: objectapply 函数清理整个数据集
在某些情况下,将自定义函数应用于 DataFrame 的每个单元格或元素。 Pandas.apply() 方法类似于内置的 map() 函数,只是将函数应用于 DataFrame 中的所有元素。
例如将数据的发布日期进行处理成 xxxx 年的格式,就可以使用apply。
def clean_date(text):
try:
return str(int(text)) + "年"
except:
return text
df["new_date"] = df["Date of Publication"].apply(clean_date)
df["new_date"]
Identifier
206 1879年
216 1868年
218 1869年
472 1851年
480 1857年
...
4158088 1838年
4158128 1831年
4159563 NaN
4159587 1834年
4160339 1834年
Name: new_date, Length: 8287, dtype: object
DataFrame 跳过行
olympics_df = pd.read_csv('数据科学必备Pandas、NumPy进行数据清洗/olympics.csv')
olympics_df.head()
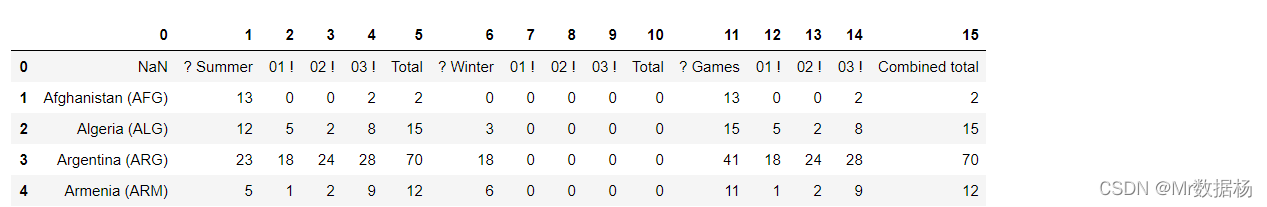
可以在读取数据时候添加参数跳过某些不要的行,比如索引 0 行。
olympics_df = pd.read_csv('数据科学必备Pandas、NumPy进行数据清洗/olympics.csv',header=1)
olympics_df.head()

DataFrame 重命名列
new_names = {'Unnamed: 0': 'Country',
'? Summer': 'Summer Olympics',
'01 !': 'Gold',
'02 !': 'Silver',
'03 !': 'Bronze',
'? Winter': 'Winter Olympics',
'01 !.1': 'Gold.1',
'02 !.1': 'Silver.1',
'03 !.1': 'Bronze.1',
'? Games': '# Games',
'01 !.2': 'Gold.2',
'02 !.2': 'Silver.2',
'03 !.2': 'Bronze.2'}
olympics_df.rename(columns=new_names, inplace=True)
olympics_df.head()

加载全部内容