Python正则表达式练习
渴望力量的哈士奇 人气:0匹配网址 url 的小练习
定义一个函数,判断 url 是否是一个正常的地址。
定义一个函数,只获取 url 的域名部分
import re
url_ture = "https://www.csdn.net/"
url_false = "ftp://110.110.110.110:8080"
def check_url(url):
result = re.findall('[a-zA-z]{4,5}://\w*\.*\w+\.\w+', url)
if not len(result) == 0:
return 'url 是一个合法的网站地址'
else:
return 'url 是一个不合法的网站地址'
def get_url(url):
result = re.findall('https://(\w*\.*\w+\.\w+)', url)
if not len(result) == 0:
return result[0]
else:
return []
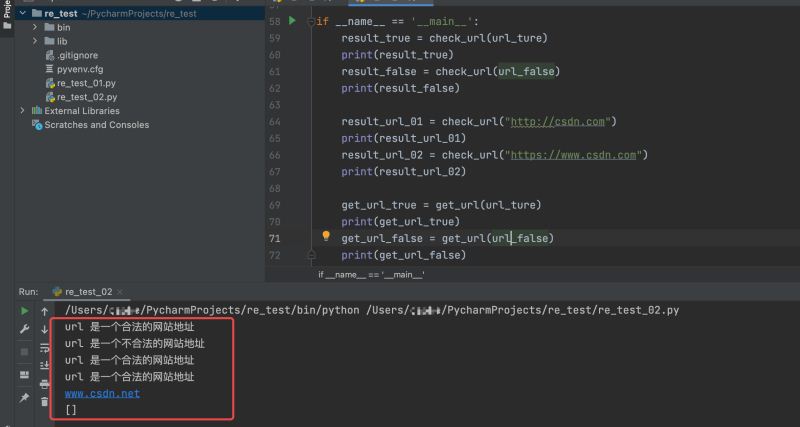
if __name__ == '__main__':
result_true = check_url(url_ture)
print(result_true)
result_false = check_url(url_false)
print(result_false)
result_url_01 = check_url("http://csdn.com")
print(result_url_01)
result_url_02 = check_url("https://www.csdn.com")
print(result_url_02)
get_url_true = get_url(url_ture)
print(get_url_true)
get_url_false = get_url(url_false)
print(get_url_false)
执行结果如下:
匹配邮箱地址的小练习
定义一个函数,获取邮箱的地址。
import re
email = "Neo@protonmail.com"
def get_email(email):
# result = re.findall('[0-9a-zA-Z]+@[0-9a-zA-Z]+\.[a-zA-Z]+', email) # 这样写比较复杂,可以使用通配符
result = re.findall('.+@.+\.[a-zA-Z]', email)
return result
if __name__ == '__main__':
get_email = get_email(email)
print(get_email)
# >>> 执行结果如下:
# >>> ['Neo@protonmail.com']
获取前端代码内容的练习
接下来做一个稍微复杂一些的练习:
定义一个函数,获取一段前端代码中双引号包裹的内容。
定义一个函数,获取该段前端代码中所有的双引号包裹的内容
import re
html = ('<div class="s-top-nav" style="display:none;">'
'</div><div class="s-center-box"></div>') # 这是前端代码,暂时不用理解是什么意思
def get_html_data(html):
re_g = re.compile('style="(.*?)"') # 非贪婪模式获取 style 标签的内容
result = re_g.findall(html)
return result
def get_all_data_html(html):
re_g = re.compile('="(.+?)"')
result = re_g.findall(html)
return result
if __name__ == '__main__':
get_html_data = get_html_data(html)
print(get_html_data)
get_all_data_html = get_all_data_html(html)
print(get_all_data_html)
# >>> 执行结果如下:
# >>> ['display:none;']
# >>> ['s-top-nav', 'display:none;', 's-center-box']
通过获取前端代码标签内容的例子,我们可以看出,只要找到字符串的规律,通过这些规律去定义正则匹配的规则就可以拿到想要的信息。
OK,今天的练习就到这里了。正则表达式最最核心最最重要的就是匹配的相关操作, findall 与 search 函数就是常用的两个函数,以及其它函数的匹配规律都是完全相同的,只不过它们返回的值会存在着不同,或者说这些函数的使用场景存在着一定的区别,但是返回的结果几乎都是相同的。
加载全部内容