pandas列转行及行转列
theskylife 人气:0一、列转行
1、背景描述
在日常处理数据过程中,你们可能会经常遇到这种类型的数据:
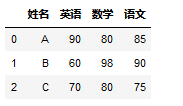
而我们用pandas进行统计分析时,往往需要将结果转换成以下类型的数据:
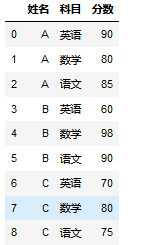
2.方法描述
准备数据
df = pd.DataFrame({'姓名': ['A','B','C'],
'英语':[90,60,70],
'数学':[80,98,80],
'语文':[85,90,75]})
这个实现的方法有多种形式,这里集中进行展示
2.1 方法1
tmp=df.set_index(['姓名']).stack() tmp2=tmp.rename_axis(index=['姓名','科目']) tmp2.name='分数' tmp2.reset_index()
2.2 方法2
tmp=df.set_index(['姓名']).stack() tmp.index.names=['姓名','科目'] tmp.reset_index(name='分数')
2.3 方法3
tmp=df.set_index(['姓名']).stack().reset_index() tmp.columns=['姓名','科目','分数']
2.4 方法4
tmp=pd.melt(df,id_vars='姓名',var_name='科目',value_name='分数')
3 思考与总结
通过上述的对比,相信各位已经明白其中的厉害之处了,下面就来重点讲解一下melt这个函数。melt函数共有以下几个:
frame: 需要处理的数据帧id_vars: 不需要做列转行处理的字段,如果不设置该字段则默认会对所有列进行处理value_vars: 需要做列转行的字段,不指定则不处理var_name: 列转行处理后,生成字段列,对列转行之前的字段名称进行重命名value_name: 列转行处理后,生成数值列,对列转行之前的数值进行命名col_level: 指定具体的列名等级,通常在有多级列名时使用。
4 思维延伸
4.1 例子1
转换前:

转换后:
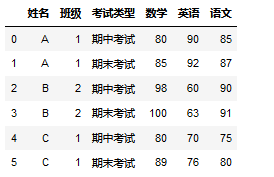
实现的1种方法:
#准备数据
df2 = pd.DataFrame({'姓名': ['A', 'B', 'C'],
'班级':[1,2,1],
'期中考试-英语': [90, 60, 70],
'期中考试-数学': [80, 98, 80],
'期中考试-语文': [85, 90, 75],
'期末考试-英语': [92, 63, 76],
'期末考试-数学': [85,100, 89],
'期末考试-语文': [87, 91, 80]})
#实现部分
t1=pd.melt(df2, id_vars=['姓名','班级'], var_name='科目', value_name='分数')
t2=t1.set_index(['姓名','班级','分数'])['科目'].str.split('-',expand=True).reset_index()
t2.set_index(['姓名','班级',0,1]).unstack().reset_index().rename_axis()
t3=t2.set_index(['姓名','班级',0,1]).unstack()
t3.columns=t3.columns.droplevel(0)
result=t3.rename_axis(columns=None).reset_index().rename(columns={0:'考试类型'})
result
4.2 例子2
转换前:

转换后:
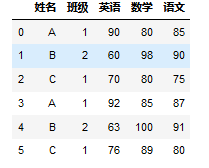
实现方法举例:
pd.lreshape(df2,{'英语':['期中考试-英语','期末考试-英语'],
'数学':['期中考试-数学','期末考试-数学'],
'语文':['期中考试-语文','期末考试-语文']})
二、行转列
在一中,我们已经完成了对于列转行的任务,即将本文一中的多列df转为tmp,那现在假如需要进行列转行又该如何操作呢?
1.准备数据
tmp=pd.DataFrame({'姓名':['A', 'B', 'C', 'A', 'B', 'C', 'A', 'B', 'C'],
'科目':['英语', '英语', '英语', '数学', '数学', '数学', '语文', '语文', '语文'],
'分数':[90, 60, 70, 80, 98, 80, 85, 90, 75]})
tmp
2.行转列实现
2.1 方法1
tmp2=tmp.set_index(['姓名','科目'])['分数'].unstack() df=tmp2.rename_axis(columns=None).reset_index()
2.2 方法2
tmp2=tmp.set_index(['姓名','科目'])['分数'].unstack() df=tmp2.rename_axis(columns=None).reset_index()
2.3 方法3
df=tmp.pivot(index='姓名',columns='科目',values='分数').rename_axis(columns=None).reset_index()
3.思考与总结
从行转列的例子中,我们可以发现核心的函数是unstack。unstack是将多重索引形式的数据,转换为标准表格形式的数据,unstack主要由两个参数组成:
level :要取消堆叠的索引级别,可以传递级别名称 。默认参数为-1,例子中为科目,即最后一个索引fill_value :如果取消堆叠后有缺失数据,会以固定字符进行填充。
三、行列转换(长宽互换)
(1) stack和unstack
California 2000 33871648
2010 37253956
New York 2000 18976457
2010 19378102
Texas 2000 20851820
2010 25145561
以上述数据为例
new_df = pop.unstack() new_df
unstack() 方法可以快速将一个多级索引的 Series 转化为普通索引的 DataFrame,stack则可以实现将列转化为索引。

来看个实际的行列互换的例子
列转行
import pandas as pd
df = pd.read_csv('data/pew.csv')
df.head(10)

df = df.set_index('religion') #先把religion设为索引
df = df.stack() #将列转化为二级索引
df.index = df.index.rename('income', level=1) #二级索引命命
df.name = 'frequency'
df = df.reset_index() #将索引转化为Series
df.head(10)

上述转化,可以看作是宽表转长表,很好记忆,将一组具有相同特征的列,转化成一列,自然就变窄了,同时为了一一对应,需要和其他列做组合,就会变长。
总结
加载全部内容