python内存泄漏排查技巧
lutianfei 人气:0首先搞清楚了本次问题的现象:
- 1. 服务在13号上线过一次,而从23号开始,出现内存不断攀升问题,达到预警值重启实例后,攀升速度反而更快。
- 2. 服务分别部署在了A、B 2种芯片上,但除模型推理外,几乎所有的预处理、后处理共享一套代码。而B芯片出现内存泄漏警告,A芯片未出现任何异常。
思路一:研究新旧源码及二方库依赖差异
根据以上两个条件,首先想到的是13号的更新引入的问题,而更新可能来自两个方面:
- 自研代码
- 二方依赖代码
从上述两个角度出发:
- 一方面,分别用
Git历史信息和BeyondCompare工具对比了两个版本的源码,并重点走读了下A、B两款芯片代码单独处理的部分,均未发现任何异常。 - 另一方面,通过pip list命令对比两个镜像包中的二方包,发现仅有pytz时区工具依赖的版本有变化。
经过研究分析,认为此包导致的内存泄漏的可能性不大,因此暂且放下

至此,通过研究新旧版本源码变化找出内存泄漏问题这条路,似乎有点走不下去了。
思路二:监测新旧版本内存变化差异
目前python常用的内存检测工具有pympler、objgraph、tracemalloc 等。
首先,通过objgraph工具,对新旧服务中的TOP50变量类型进行了观察统计
objraph常用命令如下:
# 全局类型数量 objgraph.show_most_common_types(limit=50) # 增量变化 objgraph.show_growth(limit=30)
这里为了更好的观测变化曲线,我简单做了个封装,使数据直接输出到了csv文件以便观察。
stats = objgraph.most_common_types(limit=50)
stats_path = "./types_stats.csv"
tmp_dict = dict(stats)
req_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
tmp_dict['req_time'] = req_time
df = pd.DataFrame.from_dict(tmp_dict, orient='index').T
if os.path.exists(stats_path):
df.to_csv(stats_path, mode='a', header=True, index=False)
else:
df.to_csv(stats_path, index=False)
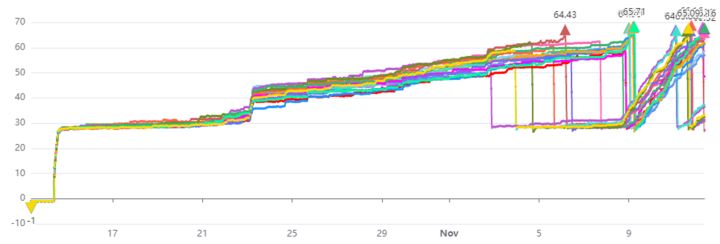
如下图所示,用一批图片在新旧两个版本上跑了1个小时,一切稳如老狗,各类型的数量没有一丝波澜。
此时,想到自己一般在转测或上线前都会将一批异常格式的图片拿来做个边界验证。
虽然这些异常,测试同学上线前肯定都已经验证过了,但死马当成活马医就顺手拿来测了一下。
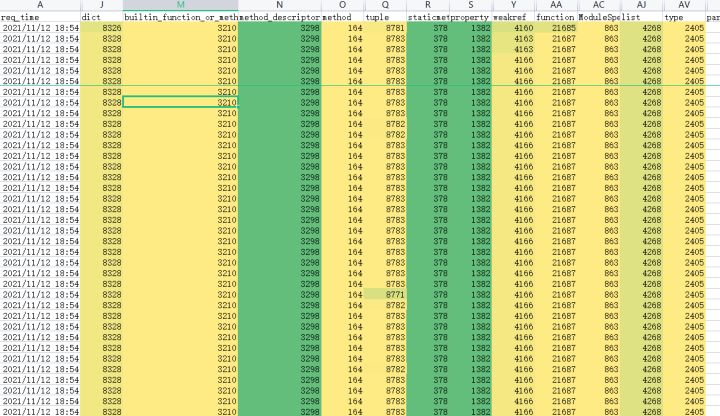
平静数据就此被打破了,如下图红框所示:dict、function、method、tuple、traceback等重要类型的数量开始不断攀升。
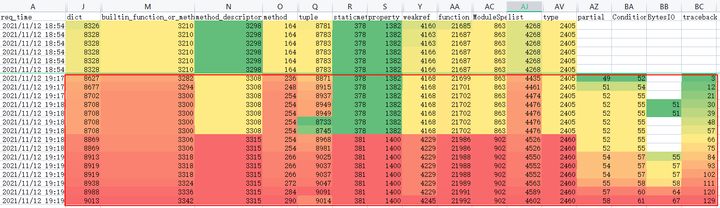
而此时镜像内存亦不断增加且毫无收敛迹象。

由此,虽无法确认是否为线上问题,但至少定位出了一个bug。而此时回头检查日志,发现了一个奇怪的现象:
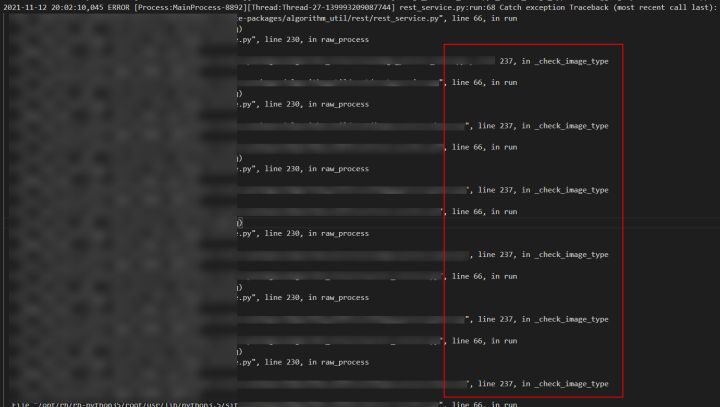
正常情况下特殊图片导致的异常,日志应该输出如下信息,即check_image_type方法在异常栈中只会打印一次。

但现状是check_image_type方法循环重复打印了多次,且重复次数随着测试次数在一起变多。
重新研究了这块儿的异常处理代码。
异常声明如下:

抛异常代码如下:

问题所在
思考后大概想清楚了问题根源:
这里每个异常实例相当于被定义成了一个全局变量,而在抛异常的时候,抛出的也正是这个全局变量。当此全局变量被压入异常栈处理完成之后,也并不会被回收。
因此随着错误格式图片调用的不断增多,异常栈中的信息也会不断增多。而且由于异常中还包含着请求图片信息,因此内存会呈MB级别的增加。
但这部分代码上线已久,线上如果真的也是这里导致的问题,为何之前没有任何问题,而且为何在A芯片上也没有出现任何问题?
带着以上两个疑问,我们做了两个验证:
首先,确认了之前的版本以及A芯片上同样会出现此问题。
其次,我们查看了线上的调用记录,发现最近刚好新接入了一个客户,而且出现了大量使用类似问题的图片调用某局点(该局点大部分为B芯片)服务的现象。我们找了些线上实例,从日志中也观测到了同样的现象。
由此,以上疑问基本得到了解释,修复此bug后,内存溢出问题不再出现。
进阶思路
讲道理,问题解决到这个地步似乎可以收工了。但我问了自己一个问题,如果当初没有打印这一行日志,或者开发人员偷懒没有把异常栈全部打出来,那应该如何去定位?
带着这样的问题我继续研究了下objgraph、pympler 工具。
前文已经定位到了在异常图片情况下会出现内存泄漏,因此重点来看下此时有哪些异样情况:
通过如下命令,我们可以看到每次异常出现时,内存中都增加了哪些变量以及增加的内存情况。
1.使用objgraph工具
objgraph.show_growth(limit=20)
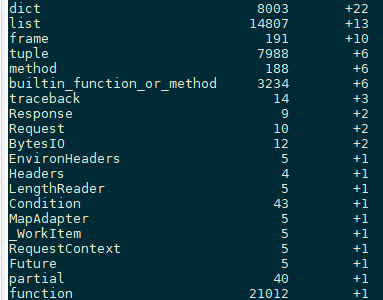
2.使用pympler工具
from pympler import tracker tr = tracker.SummaryTracker() tr.print_diff()
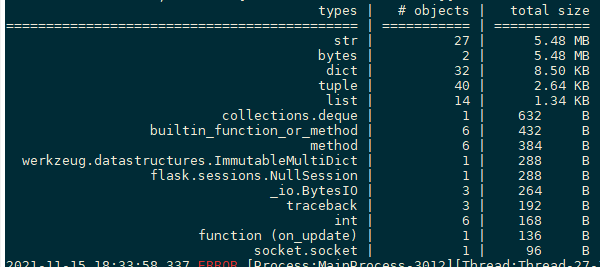
通过如下代码,可以打印出这些新增变量来自哪些引用,以便进一步分析。
gth = objgraph.growth(limit=20)
for gt in gth:
logger.info("growth type:%s, count:%s, growth:%s" % (gt[0], gt[1], gt[2]))
if gt[2] > 100 or gt[1] > 300:
continue
objgraph.show_backrefs(objgraph.by_type(gt[0])[0], max_depth=10, too_many=5,
filename="./dots/%s_backrefs.dot" % gt[0])
objgraph.show_refs(objgraph.by_type(gt[0])[0], max_depth=10, too_many=5,
filename="./dots/%s_refs.dot" % gt[0])
objgraph.show_chain(
objgraph.find_backref_chain(objgraph.by_type(gt[0])[0], objgraph.is_proper_module),
filename="./dots/%s_chain.dot" % gt[0]
)
通过graphviz的dot工具,对上面生产的graph格式数据转换成如下图片:
dot -Tpng xxx.dot -o xxx.png
这里,由于dict、list、frame、tuple、method等基本类型数量太多,观测较难,因此这里先做了过滤。
内存新增的ImageReqWrapper的调用链
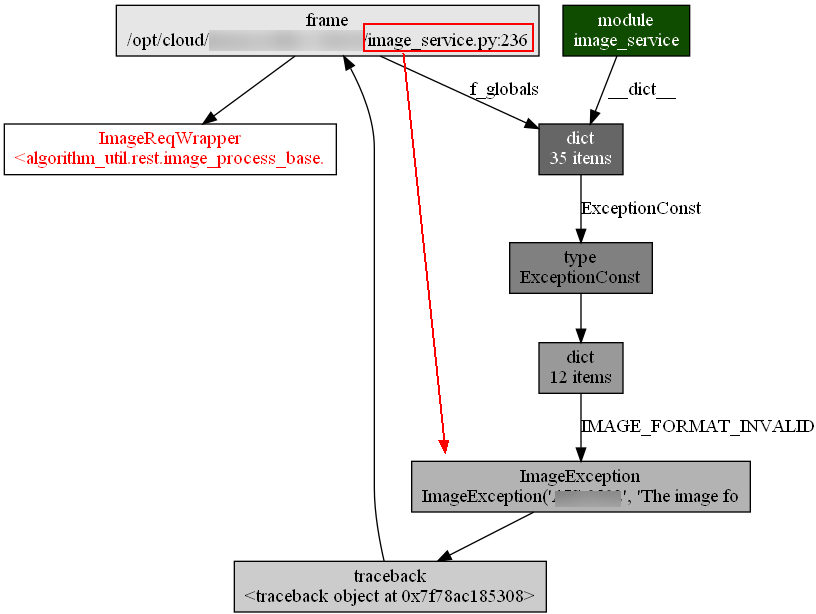
内存新增的traceback的调用链:
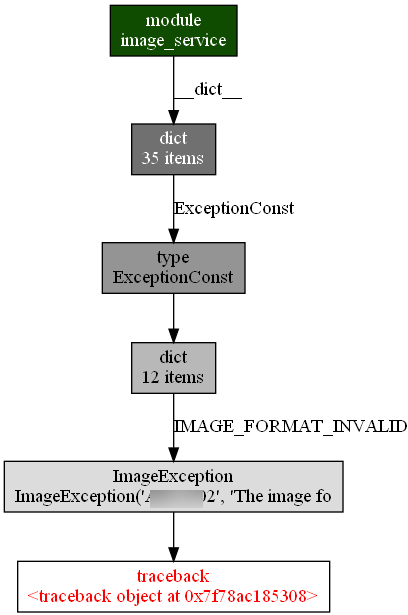
虽然带着前面的先验知识,使我们很自然的就关注到了traceback和其对应的IMAGE_FORMAT_EXCEPTION异常。
但通过思考为何上面这些本应在服务调用结束后就被回收的变量却没有被回收,尤其是所有的traceback变量在被IMAGE_FORMAT_EXCEPTION异常调用后就无法回收等这些现象;同时再做一些小实验,相信很快就能定位到问题根源。
另,关于 python3中 缓存Exception导致的内存泄漏问题,我们可以看看这篇文章:https:
至此,我们可以得出结论如下:
由于抛出的异常无法回收,导致对应的异常栈、请求体等变量都无法被回收,而请求体中由于包含图片信息因此每次这类请求都会导致MB级别的内存泄漏。
另外,研究过程中还发现python3自带了一个内存分析工具tracemalloc,通过如下代码就可以观察代码行与内存之间的关系,虽然可能未必精确,但也能大概提供一些线索。
import tracemalloc
tracemalloc.start(25)
snapshot = tracemalloc.take_snapshot()
global snapshot
gc.collect()
snapshot1 = tracemalloc.take_snapshot()
top_stats = snapshot1.compare_to(snapshot, 'lineno')
logger.warning("[ Top 20 differences ]")
for stat in top_stats[:20]:
if stat.size_diff < 0:
continue
logger.warning(stat)
snapshot = tracemalloc.take_snapshot()
到此这篇关于python内存泄漏排查技巧总结的文章就介绍到这了,更多相关python内存泄漏排查技巧内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
参考文章:
https://testerhome.com/articles/19870?order_by=created_at&
https://blog.51cto.com/u_3423936/3019476
https://segmentfault.com/a/1190000038277797
https://www.cnblogs.com/zzbj/p/13532156.html
https://drmingdrmer.github.io/tech/programming/2017/05/06/python-mem.html
https://zhuanlan.zhihu.com/p/38600861
加载全部内容