Python全栈之协程
熬夜泡枸杞 人气:01. 线程队列
# ### 线程队列
from queue import Queue
"""
put 存放 超出队列长度阻塞
get 获取 超出队列长度阻塞
put_nowait 存放,超出队列长度报错
get_nowait 获取,超出队列长度报错
"""
# (1) Queue
"""先进先出,后进先出"""
q = Queue()
q.put(100)
q.put(200)
print(q.get())
# print(q.get())
# print(q.get()) 阻塞
# print(q.get_nowait())
# print(q.get_nowait()) 报错
# Queue(3) => 指定队列长度, 元素个数只能是3个;
q2 = Queue(3)
q2.put(1000)
q2.put(2000)
# q2.put(3000)
# q2.put(4000) 阻塞
q2.put_nowait(6000)
# q2.put_nowait(4000) 报错
# (2) LifoQueue
"""先进后出,后进先出(栈的特点)"""
from queue import LifoQueue
lq = LifoQueue()
lq.put(110)
lq.put(120)
lq.put(119)
print(lq.get())
print(lq.get())
print(lq.get())
# (3) PriorityQueue
"""按照优先级顺序进行排序存放(默认从小到大)"""
"""在一个优先级队列中,要放同一类型的数据,不能混合使用"""
from queue import PriorityQueue
pq = PriorityQueue()
# 1.对数字进行排序
pq.put(100)
pq.put(19)
pq.put(-90)
pq.put(88)
print(pq.get())
print(pq.get())
print(pq.get())
print(pq.get())
# 2.对字母进行排序 (按照ascii编码)
pq.put("wangwen")
pq.put("sunjian")
pq.put('wangwei')
pq.put("王文")
pq.put("孙坚")
pq.put('王维')
print( pq.get() )
print( pq.get() )
print( pq.get() )
print( pq.get() )
print( pq.get() )
print( pq.get() )
# 3.对容器进行排序
pq.put( (22,"wangwen") )
pq.put( (67,"wangyuhan") )
pq.put( (3,"anxiaodong") )
pq.put( (3,"liuyubo") )
print(pq.get())
print(pq.get())
print(pq.get())
print(pq.get())
# 4.注意点
pq.put(100)
pq.put("nihao")
pq.put( (1,2,3) )
2. 进程池_线程池
知识点:
# 线程池
# 实例化线程池 ThreadPoolExcutor (推荐5*cpu_count)
# 异步提交任务 submit / map
# 阻塞直到任务完成 shutdown
# 获取子线程的返回值 result
# 使用回调函数 add_done_callback
# 线程池 是由子线程实现的
# 进程池 是由主进程实现的
程序实现:
# ### 进程池 和 线程池
from concurrent.futures import ProcessPoolExecutor , ThreadPoolExecutor
import os,time,random
# 获取的逻辑处理器
# print(os.cpu_count())
"""多条进程提前开辟,可触发多cpu的并行效果"""
'''
# (1) 进程池 ProcessPoolExecutor
def func(i):
# print(i)
time.sleep(random.uniform(0.1,0.8))
print(" 任务执行中 ... start ... 进程号{}".format(os.getpid()) , i )
print(" 任务执行中 ... end ... 进程号{}".format(os.getpid()))
return i
if __name__ == "__main__":
lst = []
# (1) 创建进程池对象
"""默认参数是 系统最大的逻辑核心数 4"""
p = ProcessPoolExecutor()
# (2) 异步提交任务
"""submit(任务,参数1,参数2 ... )"""
"""默认如果一个进程短时间内可以完成更多的任务,进程池就不会使用更多的进程来辅助完成 , 可以节省系统资源的损耗;"""
for i in range(10):
obj = p.submit( func , i )
# print(obj)
# print(obj.result()) 不要写在这,导致程序同步,内部有阻塞
lst.append(obj)
# (3) 获取当前任务的返回值
for i in lst:
print(i.result(),">===获取返回值===?")
# (4) shutdown 等待所有进程池里的进程执行完毕之后,在放行
p.shutdown()
print("进程池结束 ... ")
'''
# (2) ThreadPoolExecutor
'''
# from threading import currentThread as ct
from threading import current_thread as ct
def func(i):
print(" 任务执行中 ... start ... 线程号{}".format( ct().ident ) , i )
time.sleep(1)
print(" 任务执行中 ... end ... 线程号{}".format(os.getpid()))
return ct().ident # 线程号
if __name__ == "__main__":
lst = []
setvar = set()
"""默认参数是 系统最大的逻辑核心数 4 * 5 = 20"""
# (1) 创建线程池对象
t = ThreadPoolExecutor() # 20
# print(t)
# (2) 异步提交任务
"""默认如果一个线程短时间内可以完成更多的任务,线程池就不会使用更多的线程来辅助完成 , 可以节省系统资源的损耗;"""
for i in range(100):
obj = t.submit(func,i)
lst.append(obj)
# (3) 获取当前任务的返回值
for i in lst:
setvar.add(i.result())
# (4) shutdown 等待所有线程池里的线程执行完毕之后,在放行
t.shutdown()
print("主线程执行结束 ... ")
print(setvar , len(setvar))
'''
# (3) 线程池 map
from threading import currentThread as ct
from collections import Iterator,Iterable
def func(i):
time.sleep(random.uniform(0.1,0.7))
print("thread ... 线程号{}".format(ct().ident),i)
return "*" * i
if __name__ == "__main__":
t = ThreadPoolExecutor()
it = t.map(func,range(100))
# 返回的数据是迭代器
print(isinstance(it,Iterator))
# 协调子父线程,等待线程池中所有线程执行完毕之后,在放行;
t.shutdown()
# 获取迭代器里面的返回值
for i in it:
print(i)
"""
# 总结: 无论是进程池还是线程池,都是由固定的进程数或者线程数来执行所有任务
系统不会额外创建多余的进程或者线程来执行任务;
"""
3. 回调函数
知识点:
# 回调函数
就是一个参数,将这个函数作为参数传到另一个函数里面.
函数先执行,再执行当参数传递的这个函数,这个参数函数是回调函数
程序实现:
# ### 回调函数
"""
回调函数: 回头调用一下函数获取最后结果
微信支付宝付款成功后, 获取付款金额
微信支付宝退款成功后, 获取退款金额
一般用在获取最后的状态值时,使用回调
通过add_done_callback最后调用一下自定义的回调函数;
"""
from concurrent.futures import ProcessPoolExecutor , ThreadPoolExecutor
from threading import currentThread as ct
import os,time,random
"""进程任务"""
def func1(i):
time.sleep(random.uniform(0.1,0.9))
print(" 进程任务执行中 ... start ... 进程号{}".format(os.getpid()) , i )
print(" 进程任务执行中 ... end ... 进程号{}".format(os.getpid()) )
return i
def call_back1(obj):
print( "<==回调函数的进程号{}==>".format(os.getpid()) )
print(obj.result())
"""线程任务"""
def func2(i):
time.sleep(random.uniform(0.1,0.9))
print(" 线程任务执行中 ... start ... 线程号{}".format(ct().ident) , i )
print(" 线程任务执行中 ... end ... 线程号{}".format( ct().ident) )
return i
def call_back2(obj):
print( "<==回调函数的线程号{}==>".format( ct().ident) )
print(obj.result())
if __name__ == "__main__":
"""
# (1)进程池 结果:(进程池的回调函数由主进程执行)
p = ProcessPoolExecutor() # os.cpu_count() => 4
for i in range(1,11):
obj = p.submit(func1 , i )
# 使用add_done_callback在获取最后返回值的时候,可以异步并行
obj.add_done_callback(call_back1)
# 直接使用result获取返回值的时候,会变成同步程序,速度慢;
# obj.result()
p.shutdown()
print( "主进程执行结束...进程号:" , os.getpid() )
"""
print("<==============================================>")
# (2)线程池 结果:(线程池的回调函数由子线程执行)
t = ThreadPoolExecutor()
for i in range(1,11):
obj = t.submit(func2 , i )
# 使用add_done_callback在获取最后返回值的时候,可以异步并发
obj.add_done_callback(call_back2)
# 直接使用result获取返回值的时候,会变成同步程序,速度慢;
# obj.result()
t.shutdown()
print("主线程执行结束 .... 线程号{}".format(ct().ident))
"""
# 原型:
class Ceshi():
def add_done_callback(self,func):
print("系统执行操作1 ... ")
print("系统执行操作2 ... ")
# 回头调用一下
func(self)
def result(self):
return 112233
def call_back(obj):
print(obj.result())
obj = Ceshi()
obj.add_done_callback(call_back)
"""
4. 协程
知识点:
#协程也叫纤程: 协程是线程的一种实现方式.
指的是一条线程能够在多任务之间来回切换的一种实现.
对于CPU、操作系统来说,协程并不存在.
任务之间的切换会花费时间.
目前电脑配置一般线程开到200会阻塞卡顿.
#协程的实现
协程帮助你记住哪个任务执行到哪个位置上了,并且实现安全的切换
一个任务一旦阻塞卡顿,立刻切换到另一个任务继续执行,保证线程总是忙碌的,更加充分的利用CPU,抢占更多的时间片
# 一个线程可以由多个协程来实现,协程之间不会产生数据安全问题
#协程模块
# greenlet gevent的底层,协程,切换的模块
# gevent 直接用的,gevent能提供更全面的功能
程序实现:
# ### 协程
"""
进程是资源分配的最小单位
线程是程序调度的最下单位
协程是线程实现的具体方式
总结:
在进程一定的情况下,开辟多个线程,
在线程一定的情况下,创建多个协程,
以便提高更大的并行并发
"""
# (1) 用协程改写生产者消费者模型
"""
def producer():
for i in range(1000):
yield i
def consumer(gen):
for i in range(10):
print( next(gen) )
gen = producer()
consumer(gen)
print("<==========>")
consumer(gen)
print("<==========>")
consumer(gen)
"""
# (2) greenlet 协程的早期版本
from greenlet import greenlet
import time
""" switch 可以切换任务,但是需要手动切换"""
"""
def eat():
print("eat1")
g2.switch()
time.sleep(3)
print("eat2")
def play():
print("play1")
time.sleep(3)
print("play2")
g1.switch()
g1 = greenlet(eat)
g2 = greenlet(play)
g1.switch()
"""
# (3) 升级到gevent版本
"""自动进行任务上的切换,但是不能识别阻塞"""
"""
import gevent
def eat():
print("eat1")
gevent.sleep(3)
# time.sleep(3)
print("eat2")
def play():
print("play1")
gevent.sleep(3)
# time.sleep(3)
print("play2")
# 利用gevent.spawn创建协程对象g1
g1 = gevent.spawn(eat)
# 利用gevent.spawn创建协程对象g2
g2 = gevent.spawn(play)
# 如果不加join, 主线程直接结束任务,不会默认等待协程任务.
# 阻塞,必须等待g1任务完成之后在放行
g1.join()
# 阻塞,必须等待g2任务完成之后在放行
g2.join()
print("主线程执行结束 .... ")
"""
# (4) 协程的终极版本;
from gevent import monkey;monkey.patch_all()
"""引入猴子补丁,可以实现所有的阻塞全部识别"""
import time
import gevent
def eat():
print("eat1")
time.sleep(3)
print("eat2")
def play():
print("play1")
time.sleep(3)
print("play2")
# 利用gevent.spawn创建协程对象g1
g1 = gevent.spawn(eat)
# 利用gevent.spawn创建协程对象g2
g2 = gevent.spawn(play)
# 如果不加join, 主线程直接结束任务,不会默认等待协程任务.
# 阻塞,必须等待g1任务完成之后在放行
g1.join()
# 阻塞,必须等待g2任务完成之后在放行
g2.join()
print(" 主线程执行结束 ... ")
"""
# 分号,利用分号可以把多行代码放在一行进行编写;
a = 1
b = 2
a = 1;b = 2
"""
==理解:==一个线程上有好多任务,协程可以记住每个任务完成的状态,比如做饭的时候做到一半的时候停下来,去扫地,扫完地之后拐回来做饭,从做到一半的时候开始做。
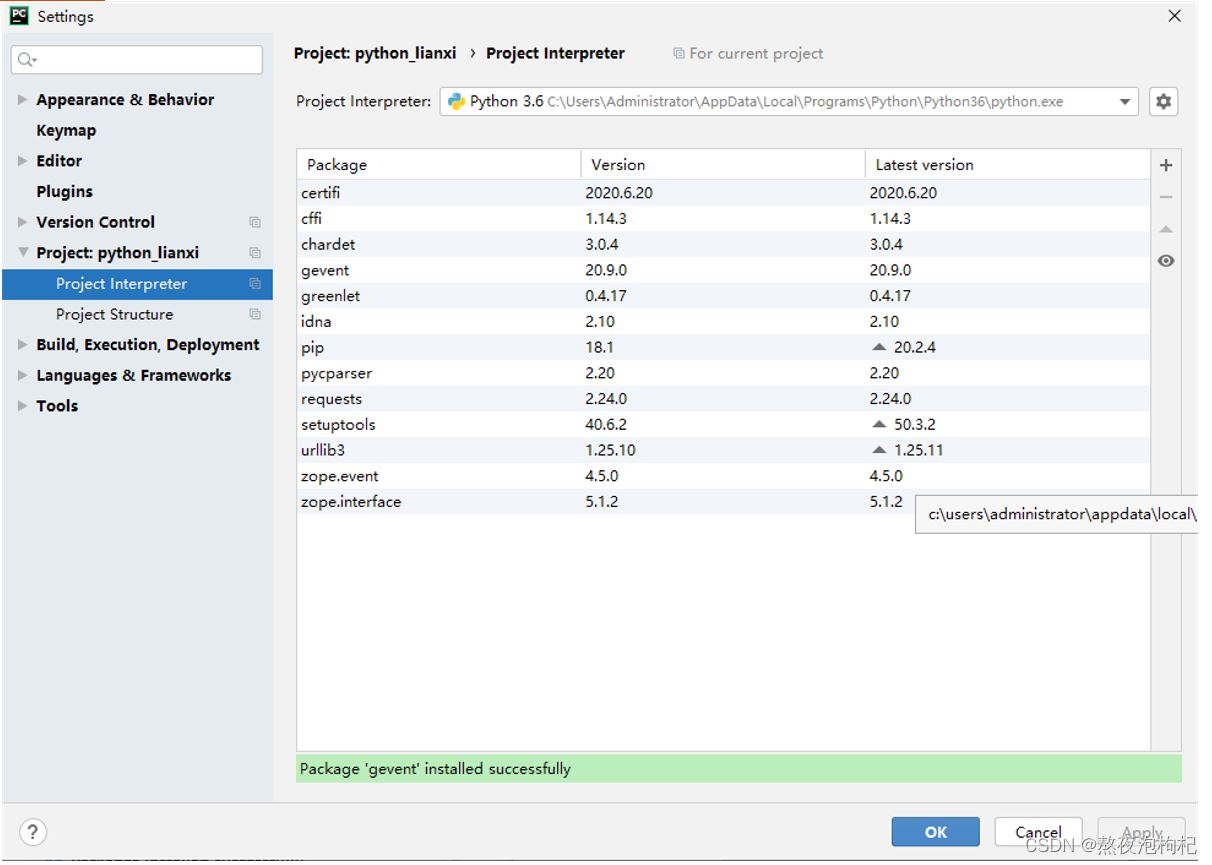
小提示: 下载gevent包,会自带greenlet
早期版本的想到在time.sleep执行了两次,每次执行了一秒钟,切换回来有执行了一秒,这是模拟早期版本,模拟堵塞

总结:
p.shutdown() 这里的shutdown类似于join 生成器在实例化对象的时候,里面的代码是不走的,调用的时候才有,next 调用等 单线程实现的一种异步并发的一种结构 协程能记住任务的状态
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注的更多内容!
加载全部内容