Python相互导入
__程序喵__ 人气:0前言
Hi! 这是随笔专栏的第一篇文章。好的开始等于成功了一半。在之后的日子里,除了不定期分享实战中可总结出的小项目外,还会经常与大分享开发时遇到的问题。今天,是一个曾困扰了我许久的关于 Python 两个文件间互相 import 的问题。
问题→解决
问题描述
两个文件间相互导入时产生了一系列错误,比如 ImportError, NameError 等等。这次,我用简单的代码示例复现一下这些问题,并一步一步解决。
问题复现
这里,我创建两个同目录下的 Python 文件:mutualImportA 和 mutualImportB 并输入代码。
# mutualImportA.py
from mutualImportB import b
a = 1
def pA():
print(b)
pA()
# mutualImportB.py
from mutualImportA import a
b = 1
def pB():
print(a)
pB()
创建完毕后,任意运行 A 或 B 都会报错:ImportError: cannot import name 'b' from partially initialized module 'mutualImportB' (most likely due to a circular import)当然有些人习惯于用 import 的导入而非 from import 的导入方式,这时候的报错就会变成:AttributeError: partially initialized module 'mutualImportB' has no attribute 'b' (most likely due to a circular import)
好的,这两个报错还算友好。这种导入的方式都在程序出指明了导入的内容,所以解释器可以发现这里是循环导入(most likely due to a circular import)。但有时出现的 NameError 才真正让人头疼。
我们将代码改一下,保留 from import 语句,但将其 import 后面的变量名改为通配符 * 。这次的报错:NameError: name 'b' is not defined
这就很奇怪了。我们在使用 IDE 时, IDE 不会检出相互导入时引发的循环导入问题。不过前两种在报错中即可看出,而这时,从报错中很难发现为何 b 没有声明。这种专为复现而出现的小文件中问题可以捋清思路、找到问题,在较大的项目中就往往无从下手了。
那么为什么会出现这样的情况呢?我们想一下整个程序的运行流程。
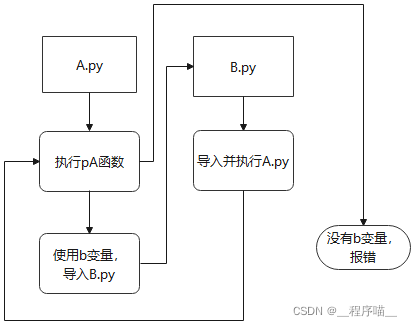
问题复现完毕,下面探讨如何解决问题。
解决问题
此前,我曾在许多平台看到过文章,但其中绝大部分都是完全重复的(尤其在 CSDN 上),明显互相“转载”来“转载”去。可惜,转载的文章并不能真正解决问题。在这篇原创的文章中,我将自己摸索的经验分享了出来。下面转入正题。
循环导入的根本原因是什么?为什么会循环导入?
其实由循环导入,我们可以想到递归而引发的栈溢出。
def a(b):
return a(b)
这,是一个明显错误的函数。一旦我们调用了函数,函数内部就会不加判断地再次调用此函数。 而当我们加入了判断时:
def a(b): if b == 1: return 1 else: return a(b - 1)
这样的话,该函数就转变为一个健康的函数了。
将同样的思路运用到相互导入的方式上。我们必须在整个文件初就要导入某个模块吗?一般来说不是的。我们应当将导入放在它真正被需要的函数里。比如,问题复现中的 a、b 改一下:
# mutualImportA.py
a = 1
def pA():
from mutualImportB import b
print(b)
pA()
# mutualImportB.py
b = 1
def pB():
from mutualImportA import a
print(a)
pB()
这样的话,就没有上面的循环导入的问题了。这次再划分下流程:
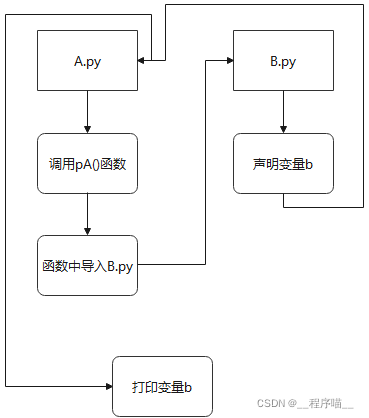
OK,那么问题到此为止就解决完毕了。
当然,据此问题也衍生出了一些代码的规范问题:
开发中,若文件较小,还是最好不要将需要相互使用的两个函数或类分到两个文件中。这样,可以避免不少的问题。
总结
说个事情,上一篇博客《利用深度优先搜索等算法实现围棋棋盘控制》有一处打错,应是 GitHub 而非 Github ,在此更正一下~
那么今天关于 Python 开发时遇到的问题的分享就到此为止了,再见!
加载全部内容