JVM解读GC日志记录分析
Idea的技术分享 人气:0相信大家在系统学习jvm的时候都会有遇到过这样的问题,散落的jvm知识点知道很多,但是真正在线上环境遇到一些莫名其妙的gc异常时候却无从下手去分析。
关于这块的苦我也表示能够理解,之前光是JVM相关的八股文就整理了许多,但是经常是不知道如何在实战中使用。最近也尝试在模拟一些案例来训练自己的JVM相关知识,本文特意记录下这段调优经历。
Java应用的GC评估
可能大多数程序员在开发完某个需求之后,往线上环境一丢,然后就基本不怎么关注后续的变化了。但是是否有考虑过,这些新引入的代码会对原有系统造成的影响呢?下边我们通过一段实战来带各位读者较好地去深入理解这个过程。
模拟场景
有一个应用程序(暂且称呼为moment服务)准备在小程序上开展社交动态推送功能,大概就是每次用户刷新页面时候便会按照一定规则推送出20条用户动态数据。由于该产品的c端用户数量比较多,于是便在上线该产品之前进行了相应的压测,判断该功能的承载能力。
在压测开始的初期,接口响应速度都还可以,但是渐渐地开始加压的时候,发现程序出现了OOM。经过排查后,排除数据库层的问题。于是开始怀疑是否是Java应用内部出现了异常。
应用的启动参数:
java -Xmx1512m -Xms1512m -Xmn1024m -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+HeapDumpOnOutOfMemoryError -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:log/gc.log -jar qiyu-framework-demo-jvm.jar
单节点压测,压力测试10w次请求,1000并发。使用ab工具进行压力测试:
ab -n100000 -c1000 http://localhost:8080/user/batch-query
jstat 查看GC,每隔5秒打印一次,持续20次
jstat -gc 5673 5000 20
经过一段时间的施压,在施压的持续了1分钟之后,YGC的频率让人感觉着实有些高。通常一个健康的系统ygc应该是20-30min左右一次,full gc可能是好几周才一次。
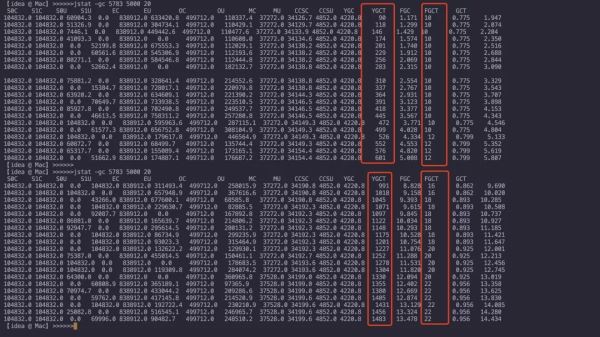
通过jstat可以看出,年轻代的gc会比较频繁,并且停顿时间严重影响了正常的业务使用。为了得到更加精准的数据,我尝试将gc日志放到GCeasy工具上进行可视化分析:
这是一款非常不错的gc日志分析工具
https://www.gceasy.io/
GC日志的可视化分析
首先是JVM内存中的占用分析,很清晰地可以看出,年轻代的内存和老年代的内存几乎占满,元空间基本没有变动过。
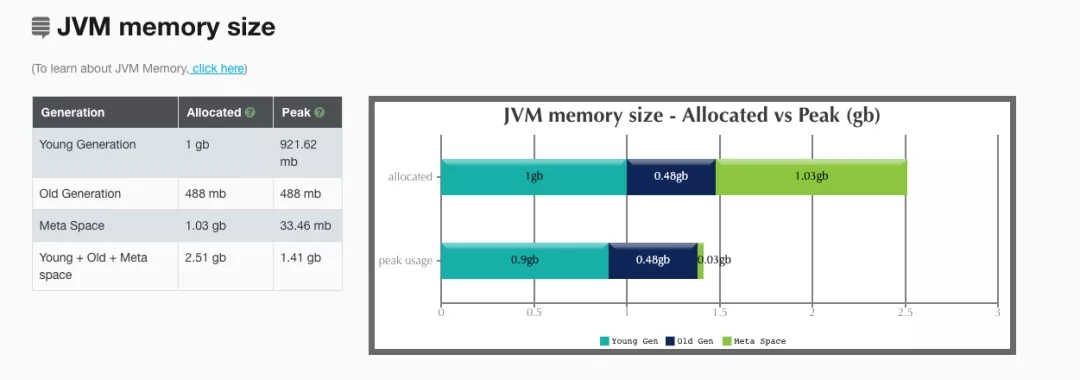
然后是整个系统的GC耗时分析:
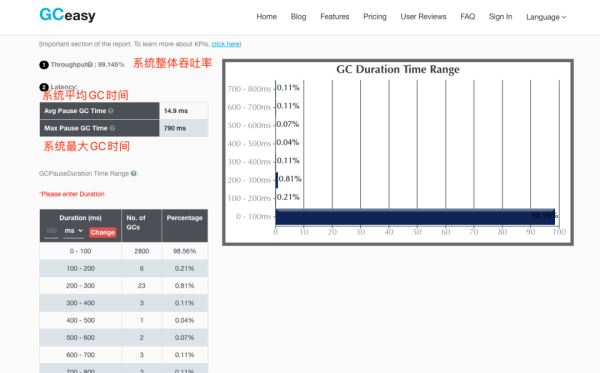
从整体来看,大部分的GC耗时都是在0-100ms内,极端情况下的GC耗时可能会达到700ms。
接下来是看看GC回收对堆内存整体的一个影响。观测发现,基本每次GC都能够回收达改200mb左右的内存。
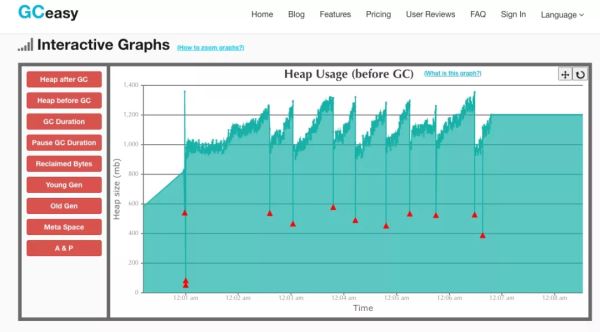
再继续分析,可以发现CMS回收器在回收的各个阶段中所消耗的时间:初始标记,并发标记,修正标记,并发清除
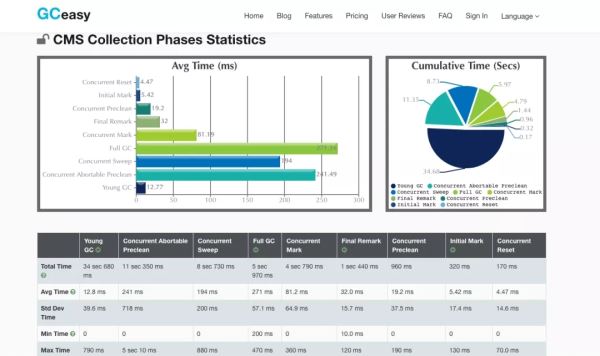
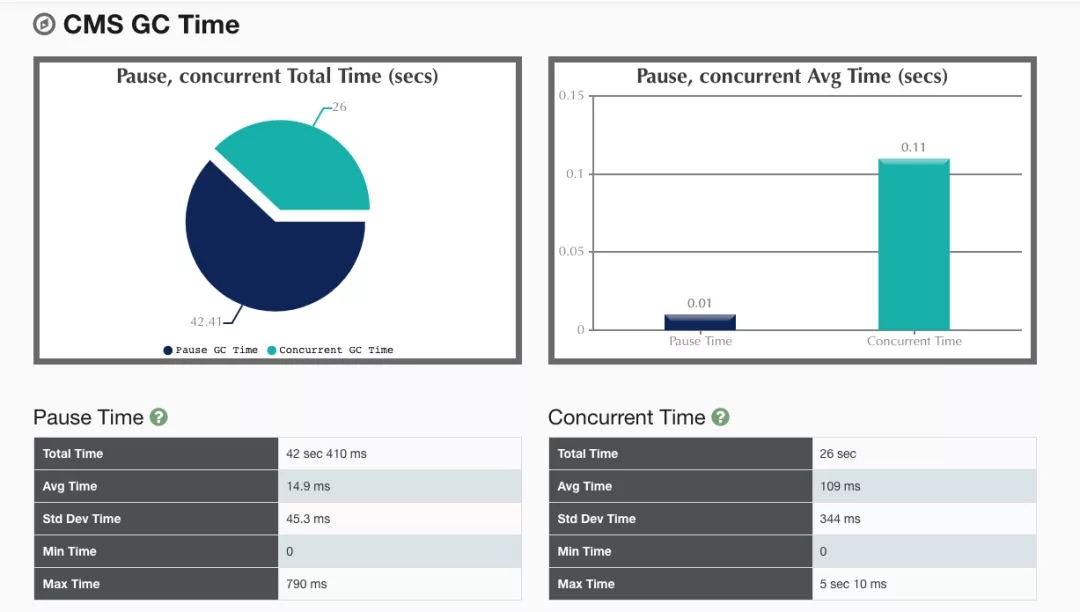
除了单纯分析GC回收的耗时之外,这款工具还有个非常赞的功能,可以帮助我们分析这段时间内,该Java程序产生对象的速率:
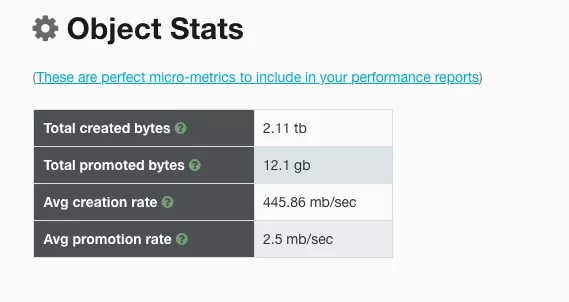
可以发现,一秒大概要产生445mb的对象,大概一秒就会有2.5mb对象晋升到老年代。
内存逃逸分析没有发现异常记录。
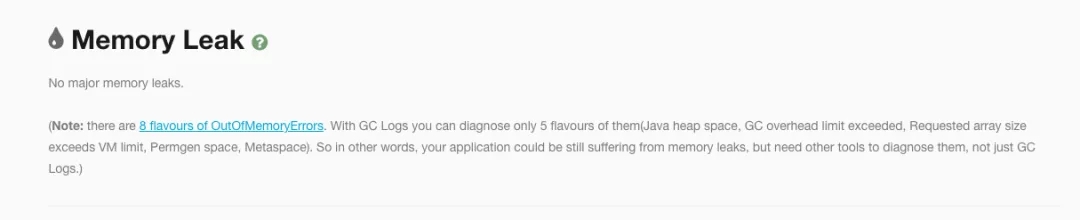
通过对这份报告分析完毕之后,我的第一直觉告诉我,年轻代不足,需要对年轻代内存进行增加。但是仔细观察下,产生对象的速率竟然高达445mb/s,这感觉非常不正常啊,极度怀疑是程序内部存在大对象的情况。
于是尝试使用jvisualVM这款工具进行深入分析,通过对CPU样例的监控,发现了一些异常信息:
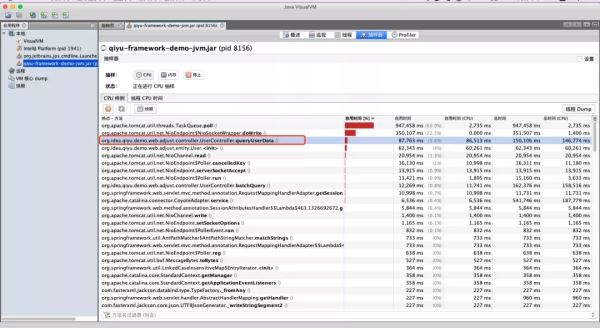
似乎这个方法对CPU的消耗比较高,接着是内存的一个监控:
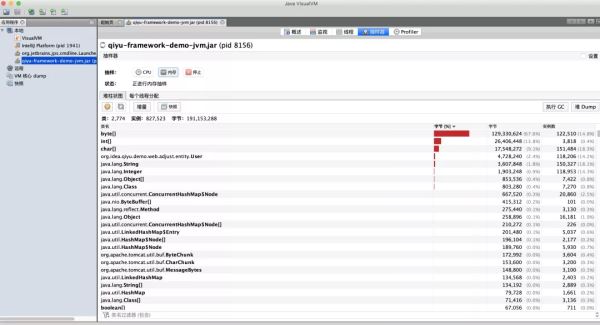
此时大概可以定位出异常方法所在的位置了,接下来便是对系统内部的业务代码进行分析了。
最后排查结果发现,其实是系统内部的一个方法调用,加载了5k个User对象到内存中做计算,而每个User对象里存放了一个大小为1kb的byte数组。大概的代码逻辑为:
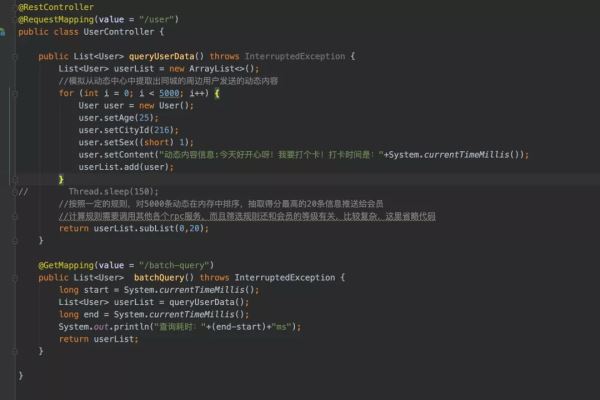
于是便需要从业务层面对该方法进行优化,例如调小5k这个数值,同时对User对象内的byte数组进行过滤(因为实际使用不到这个字段)。
调整后发现GC的频率降低了许多,比较正常。
频繁GC的排查思路总结
通过本次实验,大概能够梳理出Java应用在出现频繁GC的时候该如何去排查问题点,大致为:
通过结合工具分析GC日志,排查是否有大量对象频繁创建所导致。
通过对GC日志的分析能够排查出年轻代和老年代的GC频率。
通过对CPU占用比较高的线程,或者内存占用比较高的对象进行分析,定位异常点。
最后结合业务系统代码进行分析,精确定位异常点。
加载全部内容