Java自定义静音音频
剑客阿良_ALiang 人气:0Maven依赖
<dependency>
<groupId>org</groupId>
<artifactId>jaudiotagger</artifactId>
<version>2.0.1</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>30.1.1-jre</version>
</dependency>
代码
以16k采样率,单声道,16bits采样分辨率为例,具体参数原理,下面有说明。
import com.google.common.primitives.Bytes;
import java.io.BufferedOutputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.IntStream;
/** @Author huyi @Date 2021/9/30 15:33 @Description: 静音音频工具类 */
public class SilenceAudioUtils {
/**
* 根据PCM文件构建wav的header字段
*
* @param srate Sample rate - 8000, 16000, etc.
* @param channel Number of channels - Mono = 1, Stereo = 2, etc..
* @param format Number of bits per sample (16 here)
* @throws IOException
*/
public static byte[] buildWavHeader(int dataLength, int srate, int channel, int format)
throws IOException {
byte[] header = new byte[44];
long totalDataLen = dataLength + 36;
long bitrate = srate * channel * format;
header[0] = 'R';
header[1] = 'I';
header[2] = 'F';
header[3] = 'F';
header[4] = (byte) (totalDataLen & 0xff);
header[5] = (byte) ((totalDataLen >> 8) & 0xff);
header[6] = (byte) ((totalDataLen >> 16) & 0xff);
header[7] = (byte) ((totalDataLen >> 24) & 0xff);
header[8] = 'W';
header[9] = 'A';
header[10] = 'V';
header[11] = 'E';
header[12] = 'f';
header[13] = 'm';
header[14] = 't';
header[15] = ' ';
header[16] = (byte) format;
header[17] = 0;
header[18] = 0;
header[19] = 0;
header[20] = 1;
header[21] = 0;
header[22] = (byte) channel;
header[23] = 0;
header[24] = (byte) (srate & 0xff);
header[25] = (byte) ((srate >> 8) & 0xff);
header[26] = (byte) ((srate >> 16) & 0xff);
header[27] = (byte) ((srate >> 24) & 0xff);
header[28] = (byte) ((bitrate / 8) & 0xff);
header[29] = (byte) (((bitrate / 8) >> 8) & 0xff);
header[30] = (byte) (((bitrate / 8) >> 16) & 0xff);
header[31] = (byte) (((bitrate / 8) >> 24) & 0xff);
header[32] = (byte) ((channel * format) / 8);
header[33] = 0;
header[34] = 16;
header[35] = 0;
header[36] = 'd';
header[37] = 'a';
header[38] = 't';
header[39] = 'a';
header[40] = (byte) (dataLength & 0xff);
header[41] = (byte) ((dataLength >> 8) & 0xff);
header[42] = (byte) ((dataLength >> 16) & 0xff);
header[43] = (byte) ((dataLength >> 24) & 0xff);
return header;
}
/**
* 默认写入的pcm数据是16000采样率,16bit,可以按照需要修改
*
* @param filePath
* @param pcmData
*/
public static boolean writeToFile(String filePath, byte[] pcmData) {
BufferedOutputStream bos = null;
try {
bos = new BufferedOutputStream(new FileOutputStream(filePath));
byte[] header = buildWavHeader(pcmData.length, 16000, 1, 16);
bos.write(header, 0, 44);
bos.write(pcmData);
bos.close();
return true;
} catch (Exception e) {
e.printStackTrace();
} finally {
if (bos != null) {
try {
bos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return false;
}
/**
* 生成静音音频
*
* @param filePath 输出文件地址
* @param duration 音频时长
*/
public static void makeSilenceWav(String filePath, Long duration) {
List<Byte> oldBytes = new ArrayList<>();
IntStream.range(0, (int) (duration * 32)).forEach(x -> oldBytes.add((byte) 0));
writeToFile(filePath, Bytes.toArray(oldBytes));
}
public static void main(String[] args) {
makeSilenceWav("E:/csdn/1.wav", 5000L);
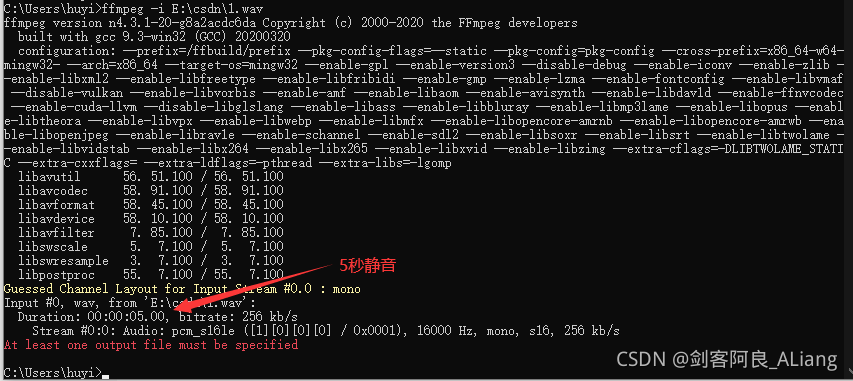
}运行结果:
使用ffmpeg查看
参数说明和使用方法
1、构造原理
构造一个wav主要分为两个部分,头文件和数据文件。那么只需要构造一个全是静音的音频数据包,在加上头就可以构造出一个静音文件。
所以代码的主要逻辑就是构造数据包->封装文件头。
2、怎么1毫秒的静音包如何构建呢?
这里首先要知道的是,音频采样率、采样分辨率和声道的概念。
这里分享一个简单的说明链接: 详解RIFF和WAVE音频文件格式
而静音就是每个采样到的音频包里面的内容都是由(byte)0构成的。
3、那么每毫秒的音频包对应多少个(byte)0呢?
这里有个公式:采样率 x 声道数 x 采样分辨率 / 8
参考链接: http://soundfile.sapp.org/doc/WaveFormat/

举个例子:如果你要生成32k采样率、双声道、16bits的静音,每毫秒需要构建几个比特0呢?
按照公式: result = 32000 x 2 x 16 / 8000 = 128 (为什么是8000,因为我们算的是毫秒,原公式单位为秒)
那么就可以把代码中的
IntStream.range(0, (int) (duration * 32)).forEach(x -> oldBytes.add((byte) 0));
修改为:
IntStream.range(0, (int) (duration * 128)).forEach(x -> oldBytes.add((byte) 0));
同时需要把头文件的格式也调整一下:
byte[] header = buildWavHeader(pcmData.length, 16000, 1, 16);
修改为:
byte[] header = buildWavHeader(pcmData.length, 32000, 2, 16);
总结
当然生成静音的方法有很多,比如使用sox在ubuntu上一行命令就行。不过如果需要在工程化项目中,对原始音频做静音拼接组装,那么你看懂了我上面的逻辑,就应该知道如何实现了吧。只要读取音频中的数据包,然后往后面添加需要静音时长的静音数据包,重新封装头,就可以得到了。
这里附上ubuntu上sox生成静音的命令供大家参考.
sox -n -r 16000 -b 16 -c 1 -L silence.wav trim 0.0 5.000
加载全部内容