聚集索引、辅助索引、覆盖索引、联合索引
BingoOnline 人气:0《MySQL技术内幕 InnoDB存储引擎》学习笔记
聚集索引(Clustered Index)
聚集索引就是按照每张表的主键构造一棵B+树,同时叶子节点中存放的即为整张表的行记录数据。
举个例子,直观感受下聚集索引。
创建表t,并以人为的方式让每个页只能存放两个行记录(不清楚怎么人为控制每页只存放两个行记录):
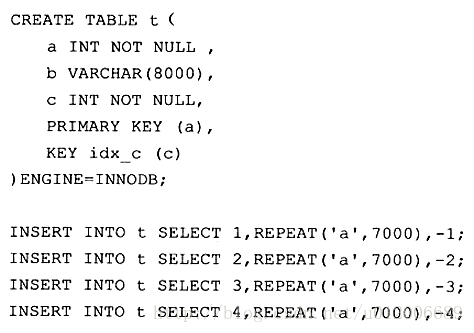
最后《MySQL技术内幕》的作者通过分析工具得到这棵聚集索引树的大致构造如下:
聚集索引的叶子节点称为数据页,每个数据页通过一个双向链表来进行链接,而且数据页按照主键的顺序进行排列。
如图所示,每个数据页上存放的是完整的行记录,而在非数据页的索引页中,存放的仅仅是键值及指向数据页的偏移量,而不是一个完整的行记录。
如果定义了主键,InnoDB会自动使用主键来创建聚集索引。如果没有定义主键,InnoDB会选择一个唯一的非空索引代替主键。如果没有唯一的非空索引,InnoDB会隐式定义一个主键来作为聚集索引。
辅助索引(Secondary Index)
辅助索引,也叫非聚集索引。和聚集索引相比,叶子节点中并不包含行记录的全部数据。叶子节点除了包含键值以外,每个叶子节点的索引行还包含了一个书签(bookmark),该书签用来告诉InnoDB哪里可以找到与索引相对应的行数据。
还是以《MySQL技术内幕》中的例子,来直观感受下辅助索引的模样。
还是以上面的表t为例,在列c上创建非聚集索引:
然后作者通过分析工作得到辅助索引和聚集索引的关系图:
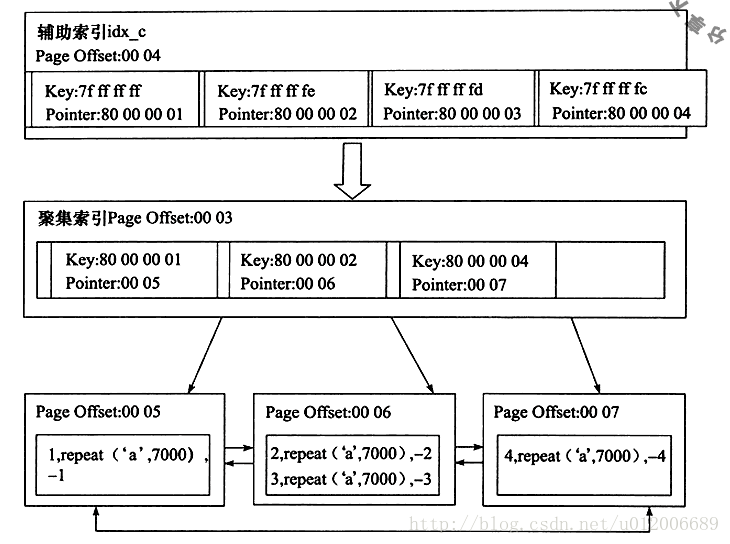
可以看到辅助索引idx_c的叶子节点中包含了列c的值和主键的值。
以Key为7fffffff为例,7是0111,0代表负数,真实的值应该取反加1,是-1,这是列c的值。Pointer是80000001,8是1000,1代表正数,所以80000001代表1,是主键的值。
覆盖索引(Covering index)
InnoDB存储引擎支持覆盖索引,即从辅助索引中就可以得到查询的记录,而不需要查询聚集索引中的记录。
使用覆盖索引有啥好处?
- 可以减少大量的IO操作
上图中我们知道,如果要查询辅助索引中不含有的字段,得先遍历辅助索引,再遍历聚集索引,而如果要查询的字段值在辅助索引上就有,就不用再查聚集索引了,这显然会减少IO操作。
比如上图中,以下sql可以直接使用辅助索引,
select a from where c = -2;
- 有助于统计
假设存在如下表:
CREATE TABLE `student` ( `id` bigint(20) NOT NULL, `name` varchar(255) NOT NULL, `age` varchar(255) NOT NULL, `school` varchar(255) NOT NULL, PRIMARY KEY (`id`), KEY `idx_name` (`name`), KEY `idx_school_age` (`school`,`age`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
如果在该表上执行:
select count(*) from student
优化器会怎么处理?
遍历聚集索引和辅助索引都可以统计出结果,但辅助索引要远小于聚集索引,所以优化器会选择辅助索引来统计。执行explain命令:

key和Extra显示使用了idx_name这个辅助索引。
还有,假设执行以下sql:
select * from student where age > 10 and age < 15
因为联合索引idx_school_age的字段顺序是先school再age,按照age做条件查询,通常不走索引:

但是,如果保持条件不变,查询所有字段改为查询条目数:
select count(*) from student where age > 10 and age < 15
优化器会选择这个联合索引:

联合索引
联合索引是指对表上的多个列进行索引。
以下为创建联合索引idx_a_b的示例:

联合索引的内部结构:
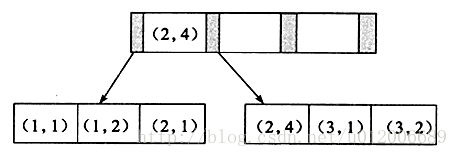
联合索引也是一棵B+树,其键值数量大于等于2。键值都是排序的,通过叶子节点可以逻辑上顺序的读出所有数据。数据(1,1)(1,2)(2,1)(2,4)(3,1)(3,2)是按照(a,b)先比较a再比较b的顺序排列。
基于上面的结构,对于以下查询显然是可以使用(a,b)这个联合索引的:
select * from table where a=xxx and b=xxx ; select * from table where a=xxx;
但是对于下面的sql是不能使用这个联合索引的,因为叶子节点的b值,1,2,1,4,1,2显然不是排序的。
select * from table where b=xxx
联合索引的第二个好处是对第二个键值已经做了排序。举个例子:
create table buy_log(
userid int not null,
buy_date DATE
)ENGINE=InnoDB;
insert into buy_log values(1, '2009-01-01');
insert into buy_log values(2, '2009-02-01');
alter table buy_log add key(userid);
alter table buy_log add key(userid, buy_date);当执行
select * from buy_log where user_id = 2;
时,优化器会选择key(userid);但是当执行以下sql:
select * from buy_log where user_id = 2 order by buy_date desc;
时,优化器会选择key(userid, buy_date),因为buy_date是在userid排序的基础上做的排序。
如果把key(userid,buy_date)删除掉,再执行:
select * from buy_log where user_id = 2 order by buy_date desc;
优化器会选择key(userid),但是对查询出来的结果会进行一次filesort,即按照buy_date重新排下序。所以联合索引的好处在于可以避免filesort排序。
加载全部内容