Mysql explain 索引
功夫熊猫阿宝 人气:0简介
Mysql 在我们项目中使用是非常广的,当我们数据量大的时候,就需要考虑建立索引了,我感觉这也是一种以空间换时间的方式;在我们查询的时候,通过使用索引来提高速度;那么,我们在使用的过程中,怎么判定有没有走索引呢?有一个explain语句来进行分析,根据阿里的Java编程规范,至少类型要提升到range;我那时候就在想为什么要提升到range呢?后来结合Mysql的索引终于知道explain和Mysql底层B+树的对应关系;注:以下内容都是基于InnoDB引擎;
1.索引分类
索引分为聚簇索引和非聚簇索引;那么,我们先来探讨一下聚簇索引;
聚簇索引
那么在InnoDB中,如果没有定义主键,那么会怎么办?
首先,他会看你有没有定义唯一键;如果有唯一键,那么就会把这个唯一键当作主键来建立索引;如果连唯一键也没有的话,就会默认创建一个隐藏列 row_id 通过这个row_id来建立索引;所以,由于有这个机制(这个机制是为了配合普通索引的),使用Innodb的话,还是,需要有一个主键 最好是递增主键;不用白不用;(还有,就是主键尽量小一点,如果像UUID一样,问题很多 第一:主键被其他普通索引叶子使用,占用空间 第二:插入的时候,需要随机访问I/O,并且,容易导致页分裂)
聚簇索引的结构 假设,我们主键递增,它的结构示意图如下:
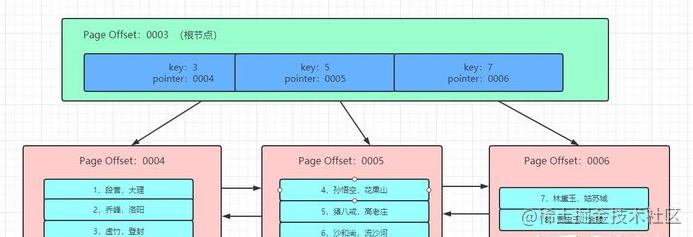
这是一个简单示意图:一页数据能存16k 所以,第一层节点数据肯定比这多多了; 但是,我们可以得到一个结论: 对于非叶子节点存的是主键 + 指针 对于叶子节点存的是 主键 + 真实的数据;
普通索引的结构 假设以 create index idx_t1_bcd on t1(b, c, d)来建立索引; 其示意图如下:
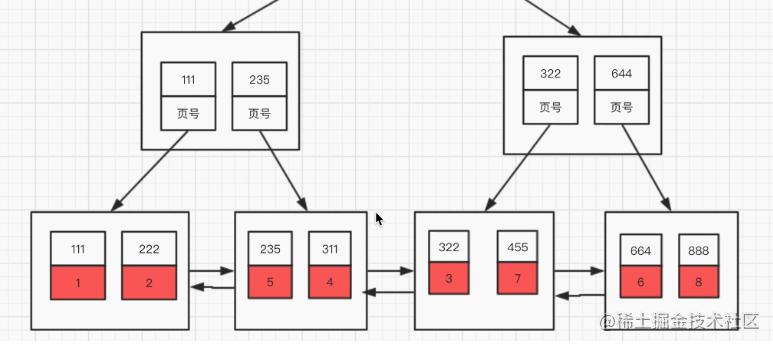
对于普通的索引来说,采用的也是B+树结构,但是: 对于 非叶子节点来说存的是 创建索引的字段(b,c,d) + 指向数据指针 对于叶子节点来说 存的是 创建索引的字段(b,c,d) + 主键的指针;
这里由于存的是主键的指针出现会导致回表:普通索引为什么需要这么设计(为什么不存数据)? 个人理解原因如下:
- 如果,普通索引也要存下数据的话,那么需要内存空间太大了;
- 如果,普通索引也存数据的话,当发生修改的话,就需要修改全部的数据;
所以,很明显这个普通索引是比聚簇索引占用空间小很多的,这个特性在count(*) 的时候会用到;
那么,为了解决回表问题,覆盖索引来进行解决;
为什么选择B+树
刚刚已经介绍了Mysql 聚簇索引和普通索引的特征;那么,现在问题来了?为什么要选择B+树呢?
原因:和Mysql的特性所致:针对磁盘来说 IO是它的一大瓶颈,索引的出现是为了快速找到对应的数据,所以说:IO越少效率越好,(就是磁盘页加载到内存次数越少越好) 那么,为什么使用B+树就会加载的少呢?
举例说明: 我们假设待存储数据一行大小是1k; 所以,我们一页可以存16行数据;假设我们的主键id为bigint类型,长度为8字节(如果是int 4字节),而指针大小为6字节;一页 为 16k 16 * 1024 /14 = 1170,所以,我们非节点页,可以存放1170个主键 + 指针;综上:如果是2层节点的B+树;可以存的数据是 1170 * 16 = 18720行数据;
那么,如果是三层的B+树呢?这时候第一页非叶子节点,可以存1170个主键+ 指针(指向的是非叶子节点) 第二页非叶子节点,也可以存1170个主键 + 指针(指向叶子节点);第三层 每一页 可以存16行数据;所以,总共可以存 1170 * 1170 * 16行数据;(这已经是千万条数据了)而且,第一层或者第二层非叶子节点一般是是缓存在内存中的,其实千万条数据找一或两次就可以了;其他的以此类推; 如果,采用B树,因为它的非叶子节点中也是存数据的层级会高过B+树;
原因2:使用B+树结构时,因为数据是存在叶子节点中,所以,对于访问查询找到第一个值,就可以通过叶子节点的双向链表进行遍历查询;而如果B树,就需要采用中序遍历;
综上: 1.B+树层级会比较低 2.对范围查询效率比较高;
explain
介绍完Mysql索引结构,我们可以来讲解explain了;

这是explain的字段,我记得我刚刚开始的时候是怎么都记不住;后来和索引建立联系以后就记住了;
id :表示表的加载顺序,id 越大越先查询 用于大表驱动小表;如果相关,就从上到下执行;
type: 查询使用了那种类型 从最好到最差 system > const > eq_ref > ref > range > index > ALL;
const:只匹配一次 出行在主键索引或者唯一索引
ref : 非唯一性索引扫描,返回匹配某个单个值的所在行; 就是通过一个where 条件找到一条或多条数据;
range: 范围查询时使用到;最低标准了;
index: 只遍历索引树 比全表扫描好一点点 因为通常来说索引文件比数据文件小;
all : 全表扫描
row :通过采用函数推算出来的要读的条数,涉及索引的选择,正常情况下误差不会很大; extra: Using filesort 文件排序 需要对找出来的数据进行外部排序,不能使用表内索引完成排序; 慢 需要优化
Using temporary : 使用了临时表来保存中间结果 更慢 需要优化
Using index : 使用了覆盖索引 Using where 使用了Where 这两个不用优化
如果,对Using filesort Using temporary为什么慢感兴趣的同学,可以查看我的另一篇文章 Using filesort Using temporary为什么这么慢
从索引树的角度分析为什么ref>range>index
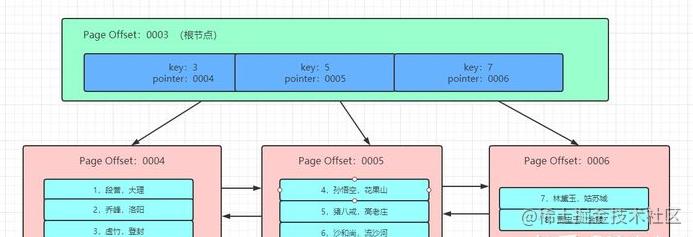
比如说:where key = 4 这个时候,它首先在第一页进行查找(这里它对链表处理过,引入了数组,为了查找快速,使用的是二分查找) 然后,找到数据指针是0005,所以就去0005数据页中,进行查找,(在页中查找也是使用二分查找)找到了第一条数据key = 4,然后,只要找下一条,看看是不是key != 4 如果,不等于4,那么,就找完了;这是ref级别的过程;
然后,where key >= 4;同理,先找到key = 4,然后,因为大于4,所以,就按照叶子节点中的指针向后找,找到底,这个是type = range 的情况;
至于 type = index 其实就是对整个索引树进行遍历 ,比如说:我创建了普通索引 user(姓名,SFZ号) 我想把所有的SFZ号找出来,这个时候,就可能使用基于索引树的全表扫描了,因为,索引树相对来说内容小一点,如果,全部扫描的话,内存中没有对应数据页还得都去找出来; 通过,这样推理,可以感受到 ref > range > index;
最左前缀原则理解 我们都知道有最左前缀原则,那么,为什么会有这个原则呢?
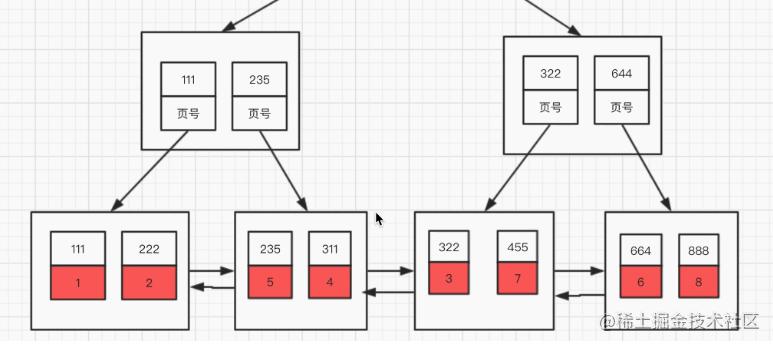
还是以他为例:因为B+树先是按照b列的值排序的,在b列的值相同的情况下才使用c列进行排序;也就是说b列的值不同的记录中c的值可能是无序的。而现在你跳过b列直接根据c的值去查找,这是做不到的。 所以说:下面sql语句是没有用的;
select * from t1 where c = 1;
但是,针对下面这条语句:从索引层面这个C是用不上的,从系统性能角度,C又是用的上的,它这叫做索引下推,因为它可以根据b = 1的双向链表相后推的时候,直接把不符合条件的C排除掉了;不用先回表查出数据,在进行排除;
select * from t1 where b > 1 and c > 1;
加载全部内容