Java8中Stream流式操作
汤圆 人气:0简介
流式操作也叫做函数式操作,是Java8新出的功能
流式操作主要用来处理数据(比如集合),就像泛型也大多用在集合中一样(看来集合这个小东西还是很关键的啊,哪哪都有它)
下面我们主要用例子来介绍下,流的基操(建议先看下lambda表达式篇,里面介绍的lambda表达式、函数式接口、方法引用等,下面会用到)
正文
1. 流是什么
流是一种以声明性的方式来处理数据的API
什么是声明性的方式?
就是只声明,不实现,类似抽象方法(多态性)
2. 老板,上栗子
下面我们举个栗子,来看下什么是流式操作,然后针对这个栗子,引出后面的相关概念
需求:筛选年龄大于1的猫(猫的1年≈人的5年),并按年龄递增排序,最后提取名字单独存放到列表中
public class BasicDemo {
public static void main(String[] args) {
// 以下猫的名字均为真名,非虚构
List<Cat> list = Arrays.asList(new Cat(1, "tangyuan"), new Cat(3, "dangdang"), new Cat(2, "milu"));
// === 旧代码 Java8之前 ===
List<Cat> listTemp = new ArrayList<>();
// 1. 筛选
for(Cat cat: list){
if(cat.getAge()>1){
listTemp.add(cat);
}
}
// 2. 排序
listTemp.sort(new Comparator<Cat>() {
@Override
public int compare(Cat o1, Cat o2) {
// 递增排序
return Integer.compare(o1.getAge(), o2.getAge());
}
});
// 3. 提取名字
List<String> listName = new ArrayList<>();
for(Cat cat: listTemp){
listName.add(cat.getName());
}
System.out.println(listName);
// === 新代码 Java8之后 ===
List<String> listNameNew = list.stream()
// 函数式接口 Predicate的 boolean test(T t)抽象方法
.filter(cat -> cat.getAge() > 1)
// lambda表达式的方法引用
.sorted(Comparator.comparingInt(Cat::getAge))
// 函数式接口 Funtion的 R apply(T t)抽象方法
.map(cat-> cat.getName())
// 收集数据,把流转为集合List
.collect(Collectors.toList());
System.out.println(listNameNew);
}
}
class Cat{
int age;
String name;
public Cat(int age, String name) {
this.age = age;
this.name = name;
}
// 省略getter/setter
}可以看到,用了流式操作,代码简洁了很多(秒哇)
Q:有的官人可能会想,这跟前面lambda表达式的组合操作有点像啊。
A:你说对了,确实只是像,区别还是很大的。因为lambda表达式的组合操作其实还是属于直接针对集合的操作;
文末会讲到直接操作集合和流式操作的区别,这里先跳过
下面我们基于这个栗子,来分别介绍涉及到的知识点
3. 流的操作步骤
我们先忽略旧版的集合操作(后面介绍流和集合的区别时再说),先来介绍流的操作(毕竟流才是今天的主角嘛)
流的操作分三步走:创建流、中间操作、终端操作
流程如下图:
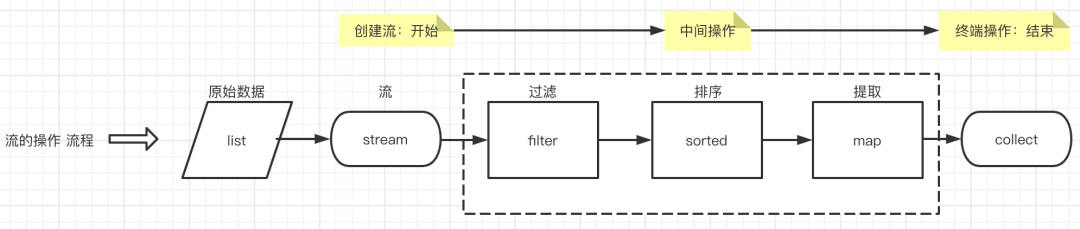
这里我们要关注一个很重要的点:
在终端操作开始之前,中间操作不会执行任何处理,它只是声明执行什么操作;
你可以想象上面这个流程是一个流水线:我们这里做个简化处理
目的:先告诉你,我们要加工瓶装的水(先创建流,告诉你要处理哪些数据)
再针对这些瓶子和水,来搭建一个流水线:固定瓶子的夹具、装水的水管、拧盖子的爪子、装箱的打包器(中间操作,声明要执行的操作)
最后按下启动按钮,流水线开始工作(终端操作,开始根据中间操作来处理数据)
因为每一个中间操作都是返回一个流(Stream),这样他们就可以一直组合下去(我好像吃到了什么东西?),但是他们的组合顺序是不固定的,流会根据系统性能去选择合适的组合顺序
我们可以打印一些东西来看下:
List<Cat> list = Arrays.asList(new Cat(1, "tangyuan"), new Cat(3, "dangdang"), new Cat(2, "milu"));
List<String> listNameNew = list.stream()
.filter(cat -> {
System.out.println("filter: " + cat);
return cat.getAge() > 1;
})
.map(cat-> {
System.out.println("map:" + cat);
return cat.getName();
})
.collect(Collectors.toList());输出如下:
filter: Cat{age=1}
filter: Cat{age=3}
map:Cat{age=3}
filter: Cat{age=2}
map:Cat{age=2}
可以看到,中间操作的filter和map组合到一起交叉执行了,尽管他们是两个独立的操作(这个技术叫作循环合并)
这个合并主要是由流式操作根据系统的性能来自行决定的
既然讲到了循环合并,那下面捎带说下短路技巧
短路这个词大家应该比较熟悉(比如脑子短路什么的),指的是本来A->B->C是都要执行的,但是在B的地方短路了,所以就变成了A->C了
这里的短路指的是中间操作,由于某些原因(比如下面的limit),导致只执行了部分,没有全部去执行
我们来修改下上面的例子(加了一个中间操作limit):
List<Cat> list = Arrays.asList(new Cat(1, "tangyuan"), new Cat(3, "dangdang"), new Cat(2, "milu"));
List<String> listNameNew = list.stream()
.filter(cat -> {
System.out.println("filter: " + cat);
return cat.getAge() > 1;
})
.map(cat-> {
System.out.println("map:" + cat);
return cat.getName();
})
// 只加了这一行
.limit(1)
.collect(Collectors.toList());输出如下:
filter: Cat{age=1}
filter: Cat{age=3}
map:Cat{age=3}
可以看到,因为limit(1)只需要一个元素,所以filter过滤时,只要找到一个满足条件的,就会停止过滤操作(后面的元素就放弃了),这个技巧叫做短路技巧
这个就很大程度上体现了中间操作的组合顺序带来的优点:需要多少,处理多少,即按需处理
4. 流的特点
特点有三个:
声明性:简洁,易读,代码行数大大减少(每天有代码行数要求的公司除外)
可复合:更灵活,各种组合都可以(只要你想,只要流有)
可并行:性能更好(不用我们去写多线程,多好)
5. 流式操作和集合操作的区别:
现在我们再来回顾下开头例子中的集合操作:筛选->排序->提取
List<Cat> listTemp = new ArrayList<>();
// 1. 筛选
for(Cat cat: list){
if(cat.getAge()>1){
listTemp.add(cat);
}
}
// 2. 排序
listTemp.sort(new Comparator<Cat>() {
@Override
public int compare(Cat o1, Cat o2) {
// 递增排序
return Integer.compare(o1.getAge(), o2.getAge());
/**
* Q:为啥不用减法 return o1.getAge() - o2.getAge()?
* A:因为减法会有数据溢出的风险
* 如果o1.getAge()为20亿,o2.getAge()为-2亿,那么结果就会超过int的极限21亿多
**/
}
});
// 3. 提取名字
List<String> listName = new ArrayList<>();
for(Cat cat: listTemp){
listName.add(cat.getName());
}
System.out.println(listName);可以看到跟流式操作不一样的有两点:
集合操作中有一个listTemp临时变量(流式操作没),
集合操作一直都在处理数据(而流式操作是直到最后一步的终端操作才会去处理数据),依次筛选->排序->提取名字,是顺序执行的
下面我们用表格来列出区别,应该会直观点
| 流式操作 | 集合操作 | |
|---|---|---|
| 功能 | 处理数据为主 | 存储数据为主 |
| 迭代方式 | 内部迭代(只迭代一次),只需声明,不需要实现,流内部自己有实现) | 外部迭代(可一直迭代)需要自己foreach |
| 处理数据 | 直到终端操作,才会开始真正处理数据(按需处理) | 一直都在处理数据(全部处理) |
用生活中的例子来对比的话,可以用电影来比喻
流就好比在线观看,集合就好本地观看(下载到本地)
总结
流是什么:
流是一种以声明性的方式来处理数据的API
流是从支持数据处理操作的源生成的元素序列
源:数据的来源,比如集合,文件等(本节只介绍了集合的流式操作,因为用的比较多;后面有空再介绍其他的)
数据处理操作:就是流的中间操作,比如filter, map
元素序列:通过流的终端操作,返回的结果集
流的操作流程:
创建流 -> 中间操作 -> 终端操作
中间操作只是声明,不真实处理数据,直到终端操作开始才会执行
循环合并:中间操作会自由组合(流根据系统自己来决定组合的顺序)
短路技巧:如果中间操作处理的数据已经达到需求,则会立即停止处理数据(比如limit(1),则当处理完1个就会停止处理)
流式操作和集合操作的区别:
流按需处理,集合全处理
流主攻数据处理,集合主攻数据存储
流简洁,集合不
流内部迭代(只迭代一次,完后流会消失),集合外部迭代(可一直迭代)
加载全部内容