Python 分析聊天记录
落伍的码农 人气:0导出聊天记录生成词云看看你和对象聊了什么(可惜我没女朋友)
1.导出聊天记录打开消息管理器
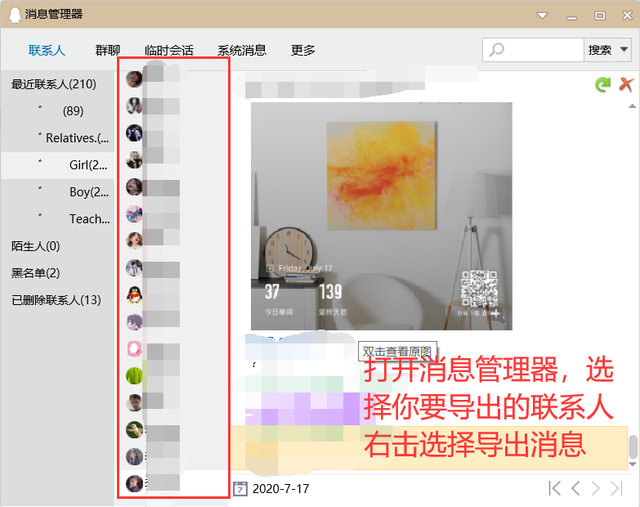
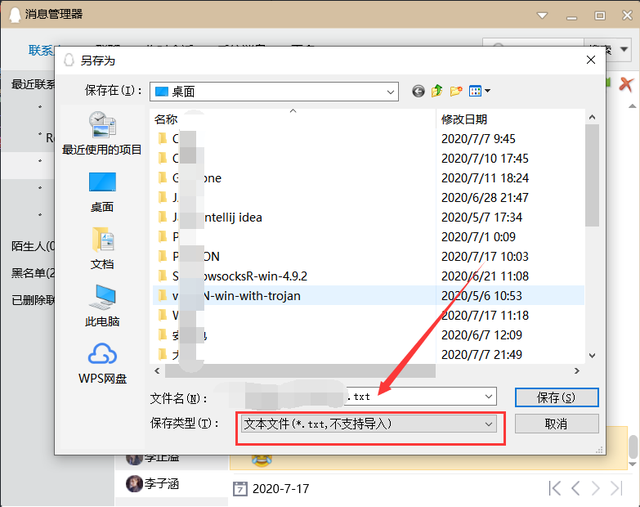
导出的格式选择txt格式(我这里选择导出的路径是桌面所以在桌面上生成了一个包含聊天记录的.txt文件)
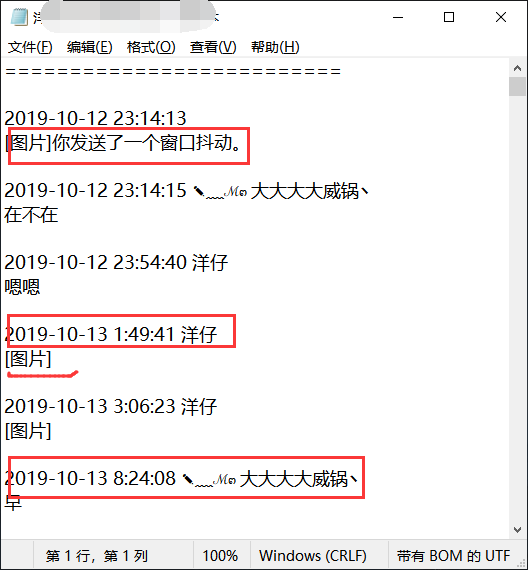
2.编写代码图中框出来的文本是我们不需要的(比如说图片会在这里面显示为[图片]表情显示为[表情]) 所以我们把它替换掉,我这里用到了正则:
string = open(r'C:\\Users\\l1768\\Desktop\\消息记录.txt','r',encoding='utf-8').read()
s = re.compile('2020.+洋仔|2020.+✎﹏ℳ๓ 大大大威锅丶|表情|图片|2019.+洋仔|2019.+✎﹏ℳ๓ 大大大威锅丶|撤回了一条消息|系统消息')#编写正则表达式
message = re.sub(s,'',string)#替换对应的字符串为空字符串
然后我们把经过处理的文本再进行去除特殊字符处理
def getText(text):#该函数用来替换文本中出现的特殊字符
txt = text
for ch in '!"#$%&()*+,-./:;<=>?@[\\]^_‘{|}~,。、 :':
txt = txt.replace(ch, "") #将文本中特殊字符替换为空格
return txt
message = getText(message)
使用jieba分词并生成词云
split_message = jieba.lcut(message)
wordcloud_txt = ' '.join(split_message)
w=wordcloud.WordCloud(background_color="white",
font_path='./fonts/simhei.ttf',
width=1600,height=800,
max_words=2000)#设置生成词云的参数,background_color指定图片背景颜色,
#font_path设置中文字体,要不然中文会显示不出来
#width=1600,height=800分别指定图片的宽度像素和高度像素,
#max_words指定生成词云的词最大是两千词
#还有很多可选参数,大家可以自行百度
w.generate(wordcloud_txt)#向词云传递文本
w.to_file("聊天记录词云.png")#最后生成词云的图片
3.最终生成的结果:

4.完整代码:
import re
import jieba
import wordcloud
def getText(text):#该函数用来替换文本中出现的特殊字符
txt = text
for ch in '!"#$%&()*+,-./:;<=>?@[\]^_‘{|}~,。、 :':
txt = txt.replace(ch, "") #将文本中特殊字符替换为空格
return txt
string = open(r'C:\Users\l1768\Desktop\消息记录.txt','r',encoding='utf-8').read()
s = re.compile('2020.+洋仔|2020.+✎﹏ℳ๓ 大大大威锅丶|表情|图片|2019.+洋仔|2019.+✎﹏ℳ๓ 大大大威锅丶|撤回了一条消息|系统消息')
message = re.sub(s,'',string)
message = getText(message)
split_message = jieba.lcut(message)
wordcloud_txt = ' '.join(split_message)
w=wordcloud.WordCloud(background_color="white", font_path='./fonts/simhei.ttf',width=1600,height=800,max_words=2000)#设置生成词云的参数
w.generate(wordcloud_txt)#向词云传递文本
w.to_file("聊天记录词云.png")#最后生成词云的图片
加载全部内容