OpLog订阅MongoDB的数据变更
kl 人气:0前言
我们开源了一个订阅分发mysql的binlog的项目,一直用的非常好,忽然有天开发说能不能支持MongoDB的数据订阅呢,MongoDB的使用度也挺广泛的。安排。经过简单的了解后发现MongoDB也有类似binlog的机制,最终花了两天时间把功能完成,并统一抽象集成到binlog开源项目中,使用和binlog同一套订阅分发模型管理MongoDB数据源。整个过程非常顺利,比整mysql的binlog要简单的多了。
oplog简介
先来聊聊MongoDB的主备机制,和mysql的binlog类似,在MongoDB中,有一个系统库“”Local”,库里有一个集合“oplog.rs”,这个集合类似于binlog文件,里面记录了MongoDB的所有操作。从节点通过读取oplog.rs里的数据做到数据同步。
解析oplog
和订阅mysql的binlog一样(模拟一个从节点mysql)。我们的订阅服务要像从节点那样读取解析oplog.rs里的数据。解析前先看下oplog.rs的Document的数据结构
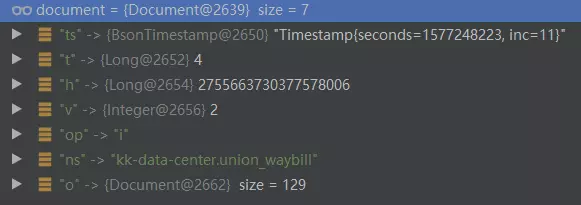
上图是一个插入的数据的日志,可见oplog的doc中共有如下字段,含义分别如下:
ts:操作的时间戳(非常重要)
t:term最初在主数据库上生成操作的。(含义不明)
h:本次操作的唯一hashID
v: 版本号
op:操作类型,有六种类型,我们只需要关注其中的i(插入)、u(更新)、d(删除)即可
ns:库名和集合名称,中间使用“.”连接
o:本次操作的document内容
o2:只有op操作类型时u更新时,才会有这个字段,代表更新的条件语句
$set:o2获取后的文档里的属性,代表更新的字段
如上字段,完成一次oplog的解析,只需要ts、op、ns、o、o2、$set即可,其中ts非常重要,可以类比为binlog中的Position。同步mysql的数据时,通过记录消费binlog的位置,也就是Position,可以有效避免订阅服务停机后,消费记录丢失的问题。同步MongoDB时,通过记录ts的值,来记录消费的位置,可以到达和订阅binlog一样的效果。和mysql订阅不同的是,MongoDB的同步需要同步服务自己查询,而且oplog在MongoDB4.0之前的版本有大小限制,超过设置的容量后,老的数据就会被丢失,在4.0之后的版本已经解除了这个限制。
代码
上面已经分析了oplog的结构以及订阅步骤,下面我们直接构建查询即可,需要注意,每次获取到的ts值,需要存储记录下来,已便重新订阅时,从上次断开的记录重新开始。下面直接看代码,重点逻辑都以注释详尽
private BsonTimestamp queryTs;
@Test
public void OpLogTest() {
MongoClient mongoClient = new MongoClient(new MongoClientURI("mongodb://admin:admin@127.0.0.1:3717"));
MongoCollectioncollection = mongoClient.getDatabase("local")
.getCollection("oplog.rs");
//如果是首次订阅,需要使用自然排序查询,获取第最后一次操作的操作时间戳。如果是续订阅直接读取记录的值赋值给queryTs即可
FindIterabletsCursor = collection.find().sort(new BasicDBObject("$natural", -1))
.limit(1);
Document tsDoc = tsCursor.first();
queryTs = (BsonTimestamp) tsDoc.get("ts");
while (true) try {
//构建查询语句,查询大于当前查询时间戳queryTs的记录
BasicDBObject query = new BasicDBObject("ts", new BasicDBObject("$gt", queryTs));
MongoCursordocCursor = collection.find(query)
.cursorType(CursorType.TailableAwait) //没有数据时阻塞休眠
.noCursorTimeout(true) //防止服务器在不活动时间(10分钟)后使空闲的游标超时。
.oplogReplay(true) //结合query条件,获取增量数据,这个参数比较难懂,见:https://docs.mongodb.com/manual/reference/command/find/index.html
.maxAwaitTime(1, TimeUnit.SECONDS) //设置此操作在服务器上的最大等待执行时间
.iterator();
while (docCursor.hasNext()) {
Document document = docCursor.next();
//更新查询时间戳
queryTs = (BsonTimestamp) document.get("ts");
//TODO 在这里接收到数据后通过订阅数据路由分发
String op = document.getString("op");
String database = document.getString("ns");
Document context = (Document) document.get("o");
Document where = null;
if (op.equals("u")) {
where = (Document) document.get("o2");
if (context != null) {
context = (Document) context.get("$set");
}
}
System.err.println("操作时间戳:" + queryTs.getTime());
System.err.println("操作类 型:" + op);
System.err.println("数据库.集合:" + database);
System.err.println("更新条件:" + JSON.toJSONString(where));
System.err.println("文档内容:" + JSON.toJSONString(context));
}
} catch (Exception e) { e.printStackTrace(); }
}结语
上面代码只是一个简单的测试用例,完整的应用还需要考虑ts的记录更新,事件的抽象,数据的分发等。我们已经开源的binlog订阅分发项目目前支持数据源在线管理,订阅数据(库、表)在线管理,如果能够使用同一套管理后台管理binlog和oplog的订阅在好不过。要实现和binlog统一管理模型,配置和分发方面基本不需要改动,然后从顶层数据源方面做区分实现即可。
目前我们整合管理的功能都已经开发好了,关于oplog部分的代码还没提交到github上,后面会和大家相见。
加载全部内容