python字符分割算法
听、 风 人气:0背景
在诸如车牌识别,数字仪表识别等问题中,最关键的就是将单个的字符分割开来再分别进行识别,如下图。最近刚好用到,就自己写了一个简单地算法进行字符分割,来记录一下。
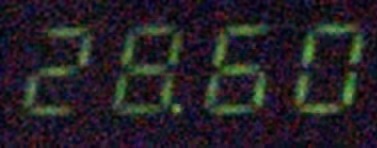
图像预处理
彩图二值化以减小参数量,再进行腐蚀膨胀去除噪点。
image = cv2.imread('F://demo.jpg', 0) # 读取为灰度图
_, image = cv2.threshold(image, 50, 255, cv2.THRESH_BINARY) # 二值化
kernel1 = cv2.getStructuringElement(cv2.MORPH_RECT, (7, 7)) # 腐蚀膨胀核
kernel2 = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5)) # 腐蚀膨胀核
image = cv2.erode(image, kernel=kernel1) # 腐蚀
image = cv2.dilate(image, kernel=kernel2) # 膨胀

确定字符区域
考虑最理想的情况,图中的字符是端正没有倾斜歪曲的。将像素灰度矩阵分别进行列相加、行相加,则在得到的列和、行和数组中第一个非 0 元素索引到最后一个非 0 元素索引包裹的区间即就是字符区域。
h, w = image.shape # 原图的高和宽
list1 = [] # 列和
list2 = [] # 行和
for i in range(w):
list1.append(1 if image[:, i].sum() != 0 else 0) # 列求和,不为0置1
for i in range(h):
list2.append(1 if image[i, :].sum() != 0 else 0) # 行求和,不为0置1
# 裁剪字符区域
# 求行的范围
flag = 0
for i, e in enumerate(list1):
if e != 0:
if flag == 0: # 第一个不为0的位置记录
start_w = i
flag = 1
else: # 最后一个不为0的位置
end_w = i
# 求列的范围
flag = 0
for i, e in enumerate(list2):
if e != 0:
if flag == 0: # 第一个不为0的位置记录
start_h = i
flag = 1
else: # 最后一个不为0的位置
end_h = i
print(start_w, end_w) # 行索引范围
print(start_h, end_h) # 列索引范围
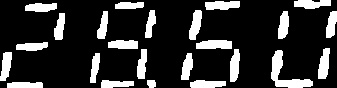
分割单个字符
与分割全部字符区域同理,在行和数组中非 0 元素索引的范围即是单个字符的区域。
l = ([i for i, e in enumerate(list1) if e != 0]) # 列和列表中不为0的索引
img_list = [] # 分割数字图片存储列表
temp = [] # 存储某一个数字的所有行索引值
n = 0 # 数字图片数量
for x in l:
temp.append(x)
if x+1 not in l: # 索引不连续的情况
if len(temp) != 1:
start_w = min(temp) # 索引最小值
end_w = max(temp) # 索引最大值
img_list.append(image[start_h:end_h, start_w:end_w]) # 对该索引包括数字切片
n += 1
temp = []
print(n) # 字符数

完整源码
import cv2
start_h, end_h, start_w, end_w = 0, 0, 0, 0 # 字符区域的高和宽起止
image = cv2.imread('F://001_1.jpg', 0) # 直接读取为灰度图
cv2.imshow('img_GRAY', image)
_, image = cv2.threshold(image, 50, 255, cv2.THRESH_BINARY) # 二值化
cv2.imshow('img_BINARY', image)
# 去噪点
kernel1 = cv2.getStructuringElement(cv2.MORPH_RECT, (7, 7)) # 简单腐蚀膨胀核
kernel2 = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5)) # 简单腐蚀膨胀核
image = cv2.erode(image, kernel=kernel1) # 腐蚀
image = cv2.dilate(image, kernel=kernel2) # 膨胀
cv2.imshow('img_denoise', image)
h, w = image.shape # 原图的高和宽
# print(h, w)
list1 = [] # 列和
list2 = [] # 行和
for i in range(w):
list1.append(1 if image[:, i].sum() != 0 else 0) # 列求和,不为0置1
for i in range(h):
list2.append(1 if image[i, :].sum() != 0 else 0) # 行求和,不为0置1
# print(len(list1))
# print(len(list2))
# 裁剪字符区域
# 求行的范围
flag = 0
for i, e in enumerate(list1):
if e != 0:
if flag == 0: # 第一个不为0的位置记录
start_w = i
flag = 1
else: # 最后一个不为0的位置
end_w = i
# 求列的范围
flag = 0
for i, e in enumerate(list2):
if e != 0:
if flag == 0: # 第一个不为0的位置记录
start_h = i
flag = 1
else: # 最后一个不为0的位置
end_h = i
print(start_w, end_w) # 行索引范围
print(start_h, end_h) # 列索引范围
cv2.imshow('img_number', image[start_h:end_h, start_w:end_w])
l = ([i for i, e in enumerate(list1) if e != 0]) # 列和列表中不为0的索引
# print(l)
img_list = [] # 分割数字图片存储列表
temp = [] # 存储某一个数字的所有行索引值
n = 0 # 数字图片数量
for x in l:
temp.append(x)
if x+1 not in l: # 索引不连续的情况
if len(temp) != 1:
start_w = min(temp) # 索引最小值
end_w = max(temp) # 索引最大值
img_list.append(image[start_h:end_h, start_w:end_w]) # 对该索引包括数字切片
n += 1
# print(temp)
temp = []
print(n) # 字符数
for i in range(n): # 显示保存字符
cv2.imshow('number'+str(i), img_list[i])
cv2.imwrite('F://demo'+str(i+1).zfill(2)+'.jpg', img_list[i])
cv2.waitKey(0)
结语
利用列向和行向相加的方法简单分割字符的方法并不适用更加复杂的分割要求,另外算法中也没有考虑小数点分割问题,仅作为学习参考,欢迎有问题一起讨论交流。
加载全部内容