springboot+mybatis-plus拦截器实现分表 springboot+mybatis-plus基于拦截器实现分表的代码实例
LL小蜗牛 人气:0前言
最近在工作遇到数据量比较多的情况,单表压力比较大,crud的操作都受到影响,因为某些原因,项目上没有引入sharding-jdbc这款优秀的分表分库组件,所以打算简单写一个基于mybatis拦截器的分表实现
一、设计思路
在现有的业务场景下,主要实现的目标就是表名的替换,需要解决的问题有
- 如何从执行的方法中,获取对应的sql并解析获取当前执行的表名
- 表名的替换策略来源,替换规则
- 实体自动建表功能
二、实现思路
针对第一个问题,我们可以用mybatis提供的拦截器对sql进行处理,并用Druid自带的sql解析功能实现表名的获取
第二个问题是相对核心的,在拦截器里面,本质上是维护了一个map,key是原表名,value是替换后的表名,构造这个map可以有不同的方式,目前想到的有这2种
- threadLocal存储一个map,用于拦截器使用
- 从当前方法获取某个入参,通过一些策略来生成对应的替换后的表名
实现自动建表的功能可以在执行sql前,通过某些规则获取用户的方法,反射进行调用,但这里可能会存在线程安全问题(重复执行建表方法)
三、代码实现
首先看看代码结构

下面是对应的注解

接口描述
这个接口用于拦截器内标识解析的数据库类型,还有一个checkTableSql是用于检查是否有对应的表名存在,用于自动建表的校验
package com.xl.mphelper.shard;
import com.alibaba.druid.DbType;
import com.xl.mphelper.dynamic.DynamicDatasource;
import java.util.Collection;
import java.util.Iterator;
/**
* @author tanjl11
* @date 2021/10/18 16:57
* 简单的分库的可以直接用{@link com.xl.mphelper.dynamic.DynamicDataSourceHolder} 自己在业务层处理
* 在{@link DynamicDatasource#getConnection()}获取链接,如果用注解事务不能保证事务完整
* 可以在同一个数据源内,调{@link com.xl.mphelper.service.CustomServiceImpl#doInTransaction(Runnable)}来开启一个事务
*/
public interface ITableShardDbType {
/**
* 数据库类型
*
* @return
*/
DbType getDbType();
/**
* 必须返回单列,值为表名,传入的是待建表的值
* 如果没有的话,就不会走检查逻辑
* @param curTableNames
* @return
*/
default String getCheckTableSQL(Collection<String> curTableNames) {
return null;
}
;
class MysqlShard implements ITableShardDbType {
private static String DEFAULT_GET_TABLE_SQL = "select TABLE_NAME from information_schema.TABLES where TABLE_NAME in ";
@Override
public DbType getDbType() {
return DbType.mysql;
}
@Override
public String getCheckTableSQL(Collection<String> curTableNames) {
StringBuilder tableParam = new StringBuilder("(");
Iterator<String> iterator = curTableNames.iterator();
while (iterator.hasNext()) {
String next = iterator.next();
tableParam.append("'").append(next).append("'").append(",");
}
int i1 = tableParam.lastIndexOf(",");
tableParam.replace(i1, tableParam.length(), ")");
return DEFAULT_GET_TABLE_SQL + tableParam;
}
}
}
另外一个接口主要是处理表逻辑,将实体+逻辑表名映射为实际的表,默认提供三种策略
package com.xl.mphelper.shard;
import com.alibaba.druid.support.json.JSONUtils;
import com.xl.mphelper.annonations.TableShardParam;
import org.springframework.util.DigestUtils;
import java.nio.charset.StandardCharsets;
/**
* @author tanjl11
* @date 2021/10/15 16:18
*/
@FunctionalInterface
public interface ITableShardStrategy<T> {
/**
* 通过实体获取表名,可以用 {@link TableShardParam}指定某个参数,并复写对应的策略
* 如果是可迭代的对象,会取列表的第一个参数作为对象,所以再进入sql前要进行分组
* 也可以使用 {@link TableShardHolder} 进行名称替换
* 优先级:TableShardHolder>TableShardParam>参数第一个
*
* @param tableName
* @param entity
* @return
*/
String routingTable(String tableName, T entity);
class TableShardDefaultStrategy implements ITableShardStrategy {
@Override
public String routingTable(String tableName, Object entity) {
return tableName + "_" + entity.toString();
}
}
class CommonStrategy implements ITableShardStrategy<Shardable> {
@Override
public String routingTable(String tableName, Shardable shardable) {
return tableName + "_" + shardable.suffix();
}
}
class HashStrategy implements ITableShardStrategy {
@Override
public String routingTable(String tableName, Object entity) {
Integer length = TableShardHolder.hashTableLength();
if (length == null||length==0) {
throw new IllegalStateException("illegal hash length in TableShardHolder");
}
String hashKey=null;
if (entity instanceof String) {
hashKey= (String) entity;
}
if(entity instanceof Shardable){
hashKey=((Shardable)entity).suffix();
}
if(entity instanceof Number){
hashKey=entity.toString();
}
if(hashKey==null&&entity!=null){
hashKey= JSONUtils.toJSONString(entity);
}
if(hashKey==null){
throw new IllegalStateException("can not generate hashKey in current param:"+entity);
}
String value = DigestUtils.md5DigestAsHex(hashKey.getBytes(StandardCharsets.UTF_8));
value=value.substring(value.length()-4);
long hashMod = Long.parseLong(value, 16);
return tableName+"_"+hashMod % length;
}
}
}
shardable接口
package com.xl.mphelper.shard;
/**
* @author tanjl11
* @date 2021/10/27 17:17
*/
public interface Shardable {
String suffix();
}
核心组成部分
1.本地线程工具类
首先是上面说的本地线程,主要是获取了映射的map,通过tableName注解来获取原表名,并设置一些属性来标识是否走拦截器的逻辑,也包括了hash的一些逻辑
package com.xl.mphelper.shard;
import com.baomidou.mybatisplus.annotation.TableName;
import com.xl.mphelper.util.ApplicationContextHolder;
import java.util.HashMap;
import java.util.Map;
/**
* @author tanjl11
* @date 2021/10/18 15:18
* 用于自定义表名,在与sql交互前使用
* 否则默认走拦截器的获取参数逻辑
*/
public class TableShardHolder {
protected static ThreadLocal<Map<String, Object>> HOLDER = ThreadLocal.withInitial(HashMap::new);
private static String INGORE_FLAG = "##ingore@@";
private static String HASH_LENGTH = "##hash_length@@";
//默认以_拼接
public static void putVal(Class entityClazz, String suffix) {
if (entityClazz.isAnnotationPresent(TableName.class)) {
TableName tableName = (TableName) entityClazz.getAnnotation(TableName.class);
String value = tableName.value();
if (value.equals(INGORE_FLAG) || value.equals(HASH_LENGTH)) {
throw new IllegalStateException("conflict with ignore flag,try another table name");
}
//hash策略处理
String res = value + "_" + suffix;
if (hashTableLength() != null) {
ITableShardStrategy tableShardStrategy = TableShardInterceptor.SHARD_STRATEGY.computeIfAbsent(ITableShardStrategy.HashStrategy.class, e -> (ITableShardStrategy) ApplicationContextHolder.getBeanOrInstance(e));
res = tableShardStrategy.routingTable(value, suffix);
}
HOLDER.get().put(value, res);
}
}
public static void ignore() {
HOLDER.get().put(INGORE_FLAG, "");
}
protected static boolean isIgnore() {
return HOLDER.get().containsKey(INGORE_FLAG);
}
public static void resetIgnore() {
HOLDER.get().remove(INGORE_FLAG);
}
public static void remove(Class entityClazz) {
if (entityClazz.isAnnotationPresent(TableName.class)) {
TableName tableName = (TableName) entityClazz.getAnnotation(TableName.class);
String value = tableName.value();
HOLDER.get().remove(value);
}
}
protected static String getReplaceName(String tableName) {
return (String) HOLDER.get().get(tableName);
}
protected static boolean containTable(String tableName) {
return HOLDER.get().containsKey(tableName);
}
protected static boolean hasVal() {
return HOLDER.get() != null && !HOLDER.get().isEmpty();
}
public static void clearAll() {
HOLDER.remove();
}
public static void hashTableLength(int length) {
HOLDER.get().put(HASH_LENGTH, length);
}
protected static Integer hashTableLength() {
return (Integer) HOLDER.get().get(HASH_LENGTH);
}
public static void clearHashTableLength() {
HOLDER.get().remove(HASH_LENGTH);
}
}
2.注解部分
TableShardParam 作用于方法参数上面,对应的值会传入对应的分表方法里面,如果启用了hash分表,会自动替换成hash策略
package com.xl.mphelper.annonations;
import com.xl.mphelper.shard.ITableShardStrategy;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
/**
* @author tanjl11
* @date 2021/10/15 17:56
* 这个策略比类上的要高
* 用于方法参数
*/
@Target({ElementType.PARAMETER})
@Retention(RetentionPolicy.RUNTIME)
public @interface TableShardParam {
//获取表名的策略
Class<? extends ITableShardStrategy> shardStrategy() default ITableShardStrategy.TableShardDefaultStrategy.class;
int hashTableLength() default -1;
boolean enableHash() default false;
}
TableShard,作用于mapper上面,主要描述了自动建表信息和获取表映射的信息,还有获取当前方法的信息,同样也对常用的hash进行处理
package com.xl.mphelper.annonations;
import com.xl.mphelper.shard.ExecBaseMethod;
import com.xl.mphelper.shard.ITableShardDbType;
import com.xl.mphelper.shard.ITableShardStrategy;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
/**
* @author tanjl11
* @date 2021/10/15 16:13
* 作用于mapper上面
*/
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface TableShard {
//是否自动建表
boolean enableCreateTable() default false;
//创建表方法
String createTableMethod() default "";
//获取表名的策略
Class<? extends ITableShardStrategy> shardStrategy() default ITableShardStrategy.CommonStrategy.class;
//是否启用hash策略,-1不启用,其他作为分表的数量
int hashTableLength() default -1;
//默认使用的db策略
Class<? extends ITableShardDbType> dbType() default ITableShardDbType.MysqlShard.class;
//选取方法的策略,用到分页组件时需额外注意
Class<? extends ExecBaseMethod> execMethodStrategy() default ExecBaseMethod.class;
}
获取方法的类,对应上面的execMethodStrategy,主要是判断当前方法是否需要分表以及给出对应方法的参数(项目上用了pagehelper,count的时候会默认带个后缀,所以是额外处理),下面是公共处理
package com.xl.mphelper.shard;
import com.xl.mphelper.annonations.TableShardIgnore;
import java.lang.reflect.Method;
import java.lang.reflect.Parameter;
/**
* @author tanjl11
* @date 2021/10/26 18:43
* 当找不到方法时候,可能是分页类型的,需要额外处理
*/
public class ExecBaseMethod {
protected MethodInfo genMethodInfo(Method[] candidateMethods, String curMethodName) {
Method curMethod = null;
for (Method method : candidateMethods) {
if (method.getName().equals(curMethodName)) {
curMethod = method;
break;
}
}
if (curMethod == null) {
MethodInfo methodInfo = new MethodInfo();
methodInfo.shouldIgnore = true;
return methodInfo;
}
boolean shouldIgnore = curMethod.isAnnotationPresent(TableShardIgnore.class);
MethodInfo methodInfo = new MethodInfo();
methodInfo.shouldIgnore = shouldIgnore;
methodInfo.parameters = curMethod.getParameters();
return methodInfo;
}
public static class MethodInfo {
protected boolean shouldIgnore;
protected Parameter[] parameters;
}
}
还有个注解就是作用于方法上,标识该方法需要忽略,不走分表拦截的逻辑
3.拦截器实现
定义了几个缓存类
分别是缓存mapper、分表策略、数据库类型、已经处理过的表(自动建表逻辑)
private static final Map<String, Class> MAPPER_CLASS_CACHE = new ConcurrentHashMap<>();
private static final Map<Class, ITableShardStrategy> SHARD_STRATEGY = new ConcurrentHashMap<>();
private static final Map<Class, ITableShardDbType> SHARD_DB = new ConcurrentHashMap<>();
private static final Set<String> HANDLED_TABLE = new ConcurrentSkipListSet<>();
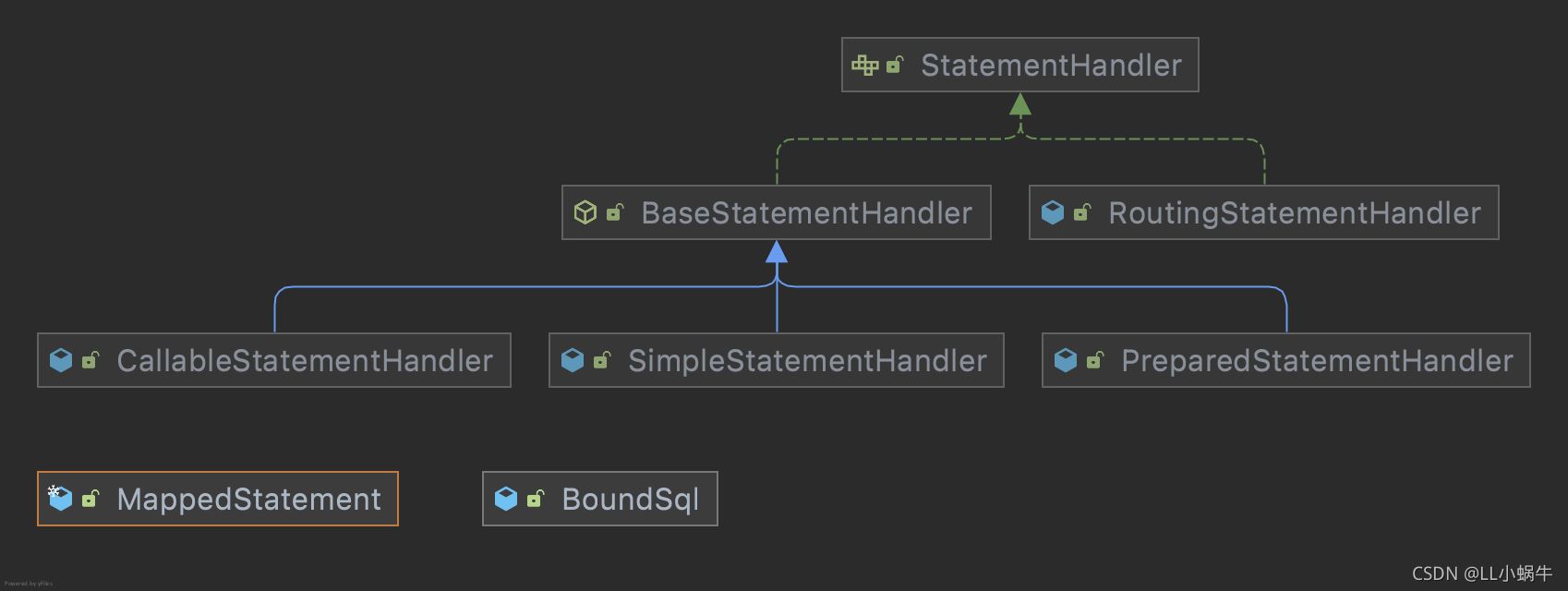
首先需要通过StatmentHandler来获取boundSql、MappedStatement对象
routingStatementHandler里面有三种statementHandler,他们都继承于BaseStatementHandler
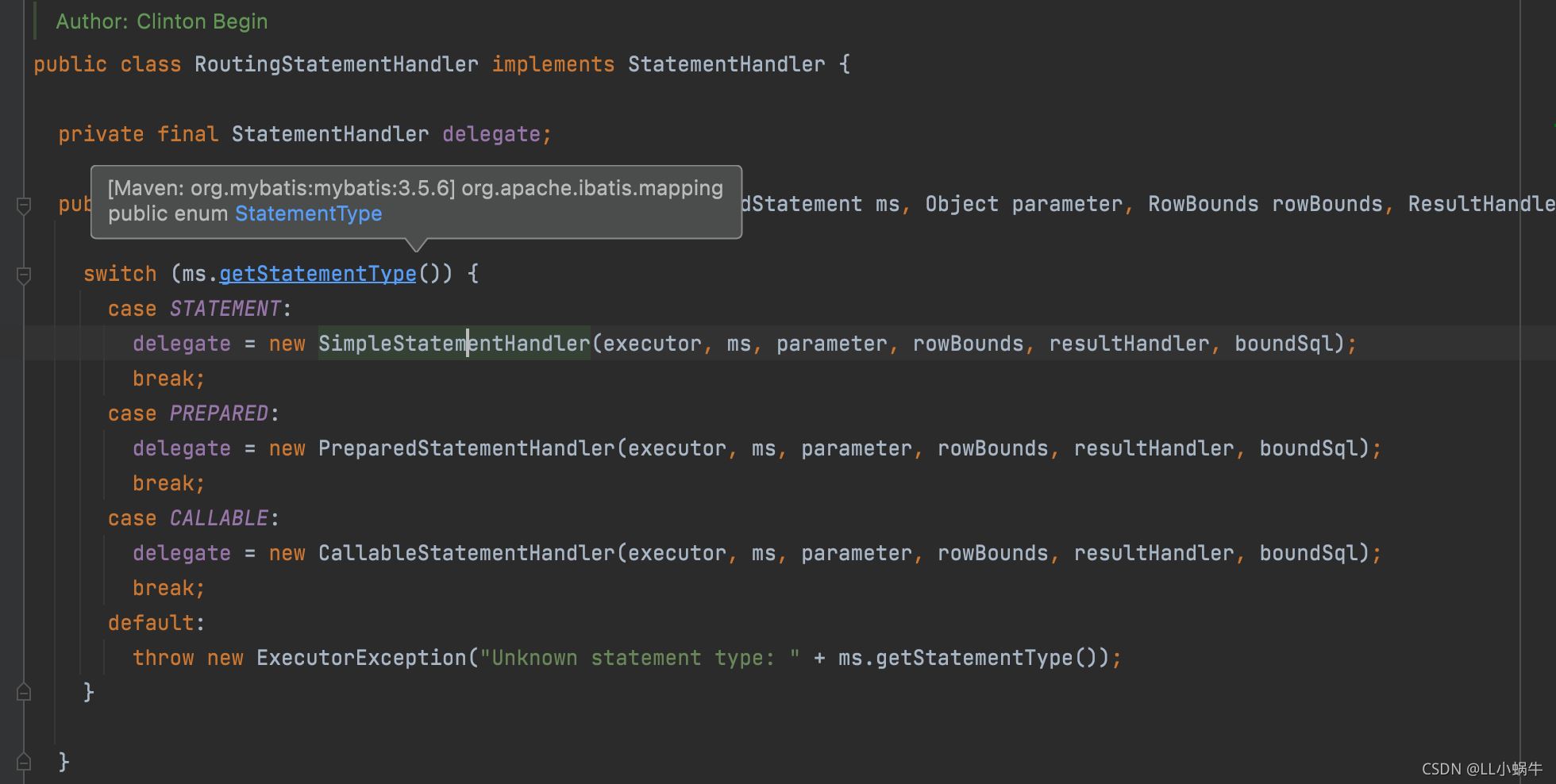
这个类里面就有boundSql对象
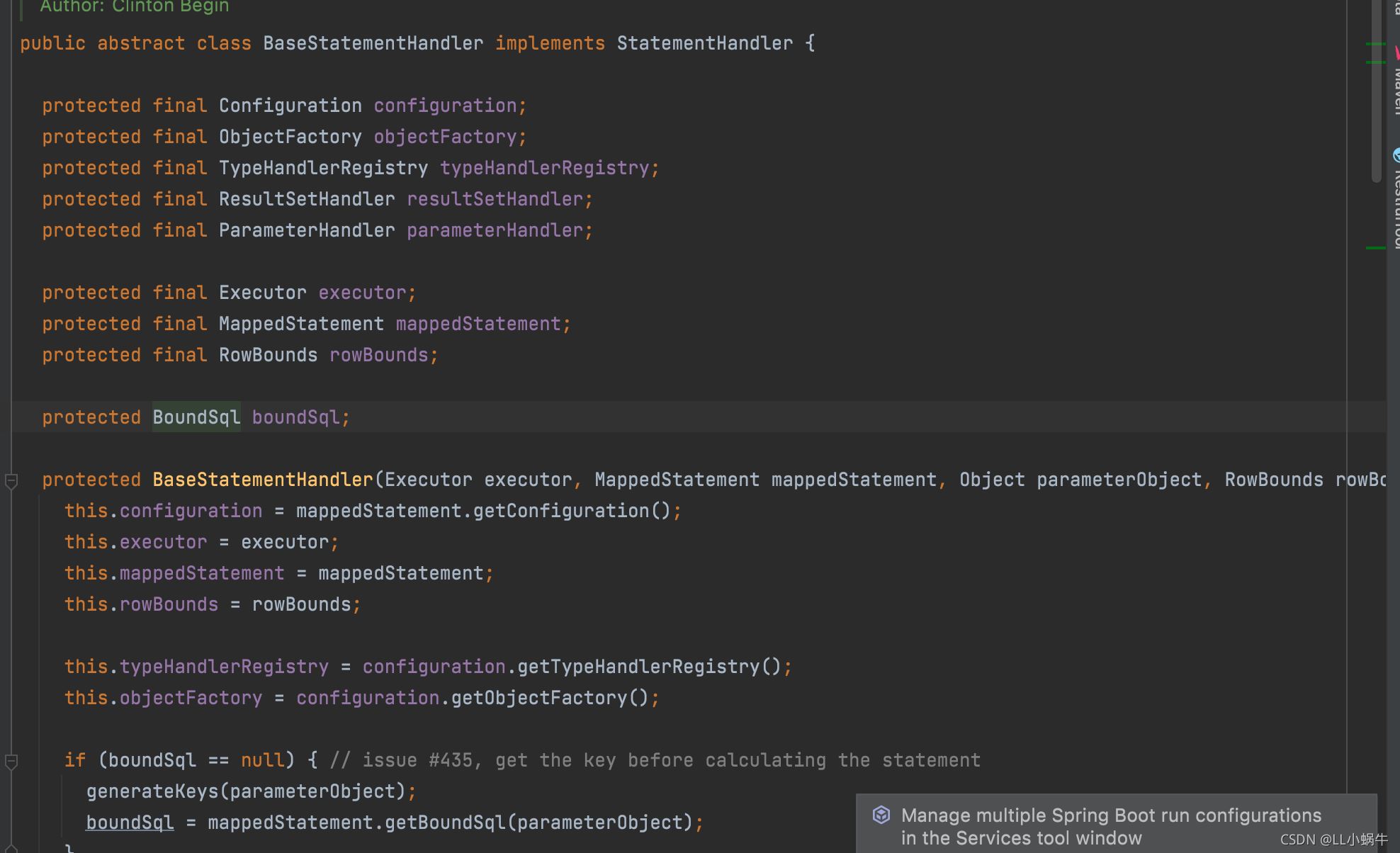
boundSql对象可以获取执行的sql,还有当前方法的值
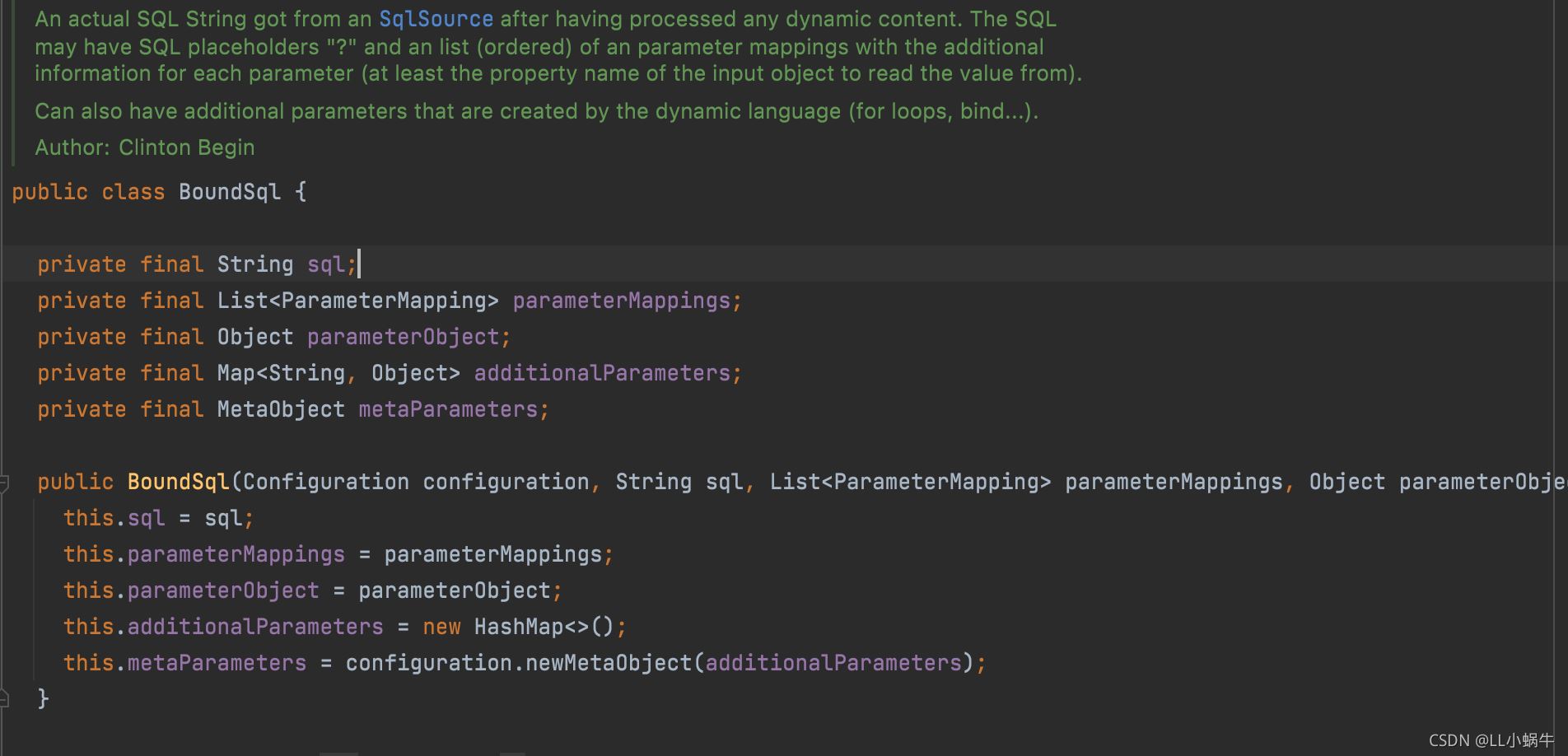
MappedStatement对象主要是mapper方法的一个封装,包括入参、返回结果等
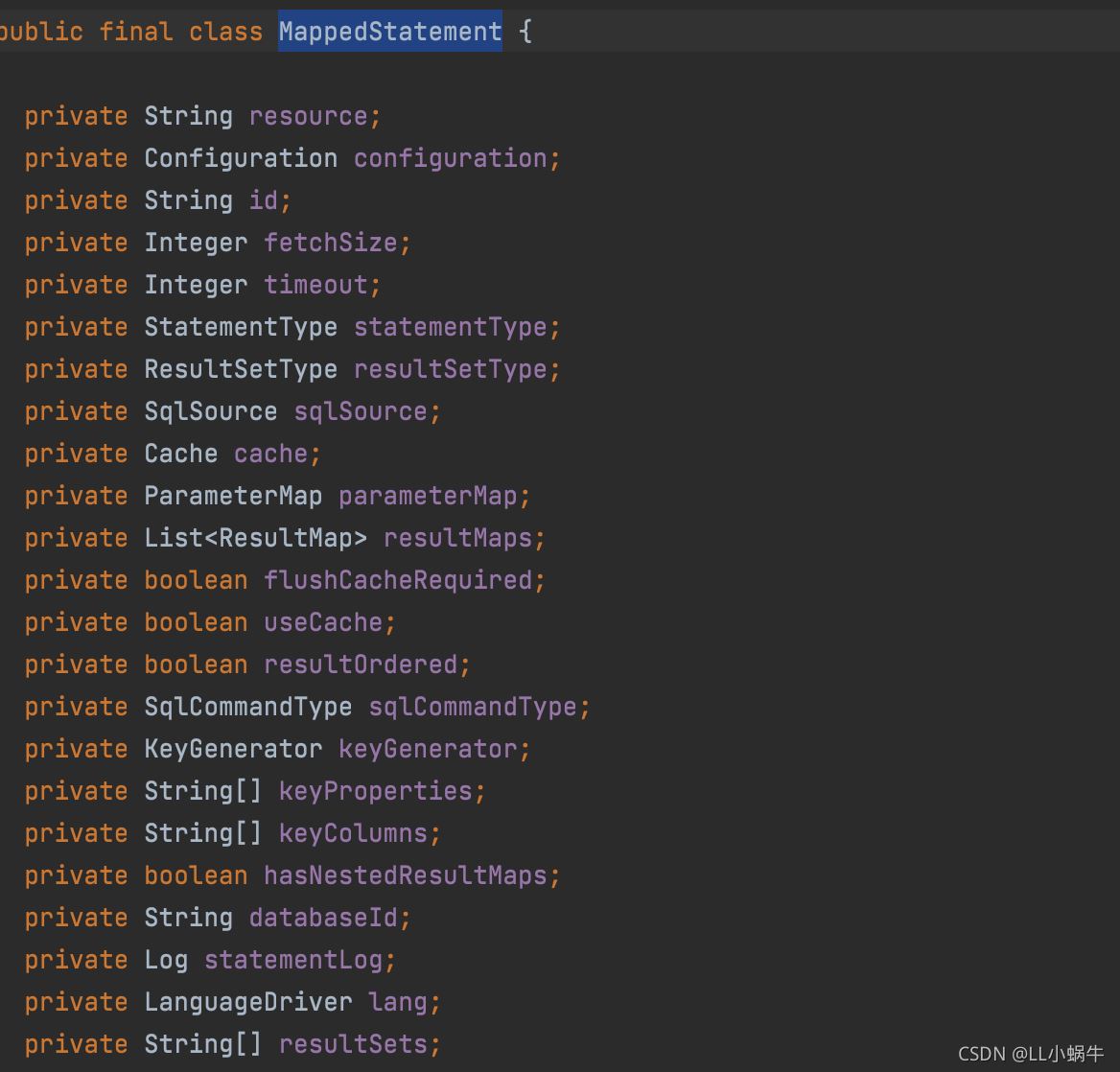
关系图如下,routingStatementHandler是一个入口,根据不同的type用不同的handler进行处理
mybatis会用动态代理来创建一个invocation对象给到拦截器
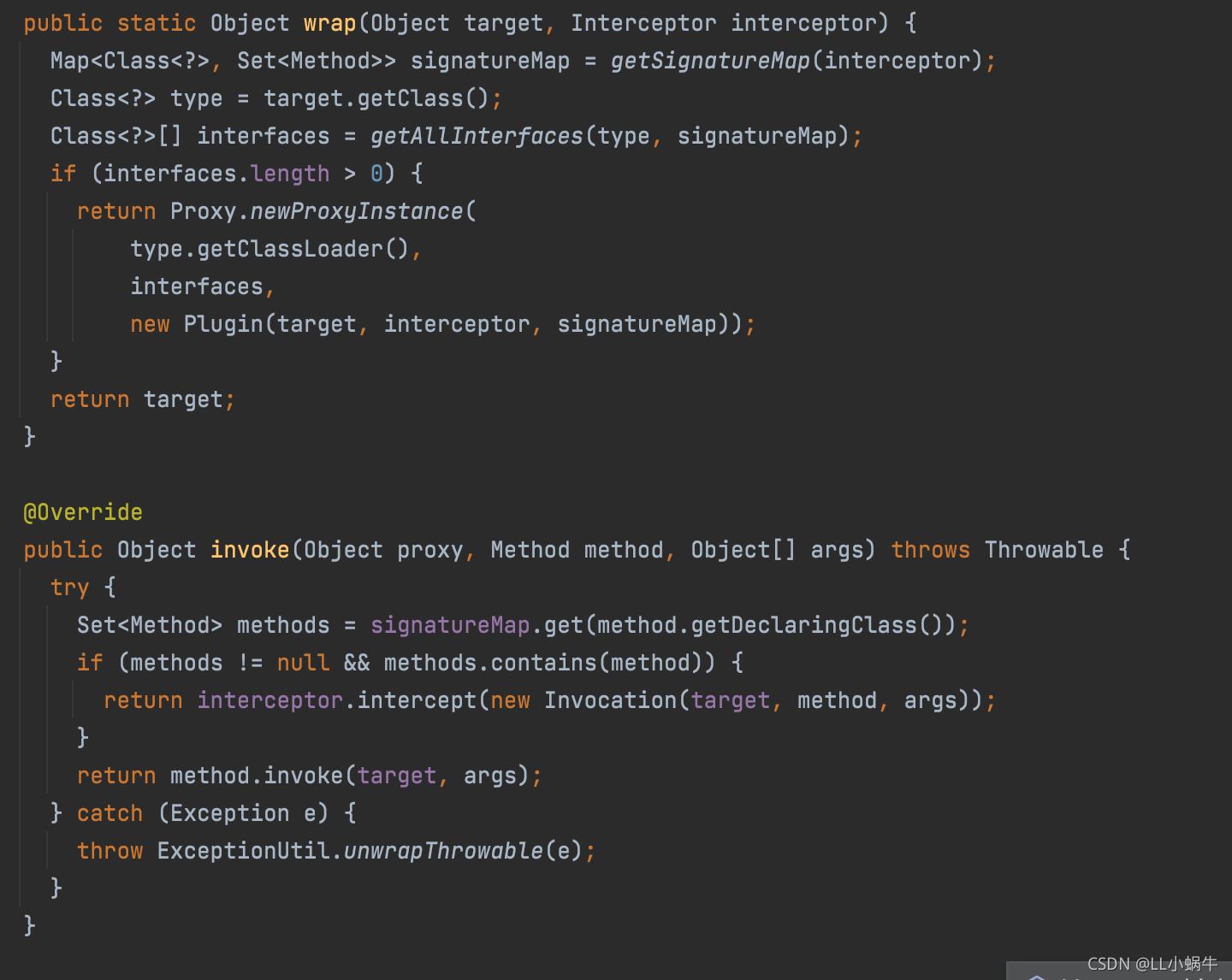
上面大概说明了拦截器是怎么获取到当前方法的参数的,以及myabtis提供了metaObject来获取BoundSql、MappedStatement 来获取当前执行的sql,当前执行的方法等信息
这时候我们可以确定,我们拦截器的拦截范围
@Override
public Object plugin(Object target) {
if (target instanceof RoutingStatementHandler) {
return Plugin.wrap(target, this);
}
return target;
}
以及获取上面两个关键对象的方法
RoutingStatementHandler statementHandler = (RoutingStatementHandler) invocation.getTarget();
//获取
MetaObject metaObject = MetaObject.forObject(statementHandler, DEFAULT_OBJECT_FACTORY, DEFAULT_OBJECT_WRAPPER_FACTORY, REFLECTOR_FACTORY);
BoundSql boundSql = (BoundSql) metaObject.getValue("delegate.boundSql");
MappedStatement mappedStatement = (MappedStatement) metaObject.getValue("delegate.mappedStatement");
MappedStatement的ID就是mapper里面一个方法的标识
org.apache.ibatis.builder.annotation.MapperAnnotationBuilder#parseStatement
上面的方法里面标识了他的组成,就是mapperClass的名称+方法名
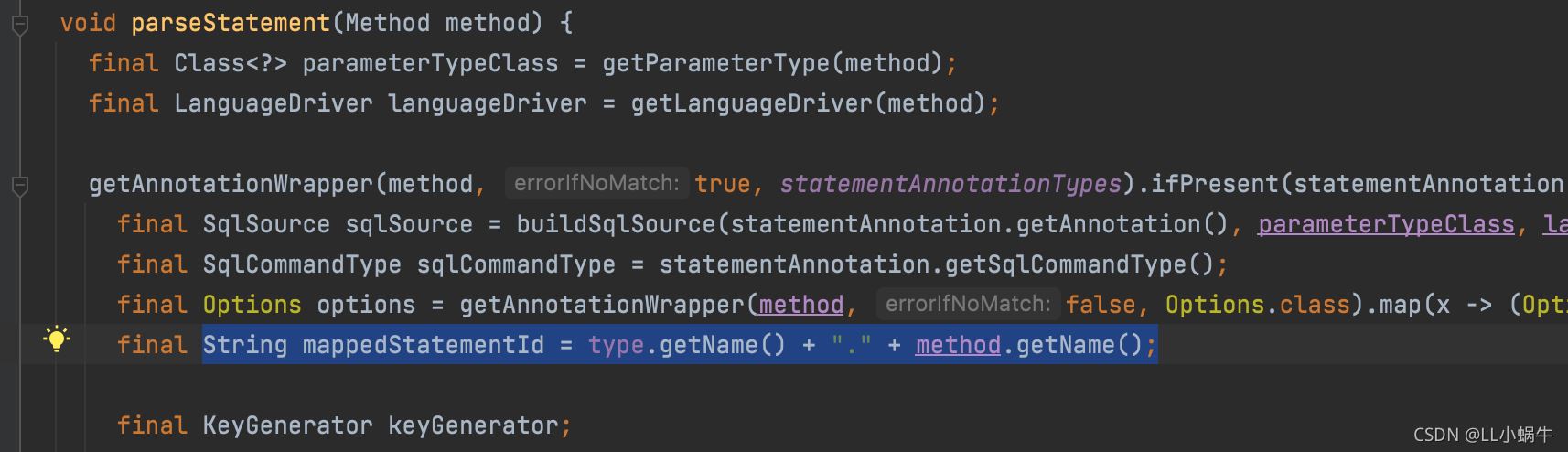
通过上述规则,解析id来获取对应的mapper名称
private Class<? extends BaseMapper> getMapperClass(MappedStatement mappedStatement) {
String id = mappedStatement.getId();
//mapperClass
String className = id.substring(0, id.lastIndexOf("."));
return MAPPER_CLASS_CACHE.computeIfAbsent(className, name -> {
try {
return Class.forName(name);
} catch (ClassNotFoundException e) {
throw new IllegalStateException(e);
}
});
}
获取到mapper的class之后,获取对应的注解,对于判断是否需要走拦截器的逻辑,用到了上面获取方法信息的ExecBaseMethod,该接口返回了是否需要执行逻辑,以及当前方法的参数列表
private ExecBaseMethod.MethodInfo getExecMethod(MappedStatement mappedStatement, Class mapperClass, TableShard annotation) {
String id = mappedStatement.getId();
//methodName
String methodName = id.substring(id.lastIndexOf(".") + 1);
final Method[] methods = mapperClass.getMethods();
ExecBaseMethod execMethod = (ExecBaseMethod) getObjectByClass(annotation.execMethodStrategy());
return execMethod.genMethodInfo(methods, methodName);
}
这时候已经获取到了TableShard注解、执行方法的信息,然后可以结合上面获取的BoundSql对象,来解析获取对应的表名
这里插个题外话,下面这段代码是获取一个解析sql的处理器
SchemaStatVisitor visitor = SQLUtils.createSchemaStatVisitor(dbType);
当时也想用一个静态map缓存起来,但是线上运行时候发现oom,后面分析一下原来这个visitor每次解析sql之后,都会产生大量跟预编译相关SLVariantRefExpr对象,所以导致缓存不断变大缺无法回收,后面改为在方法内执行
private Set<String> getTableNames(BoundSql boundSql, TableShard shard) {
Class<? extends ITableShardDbType> shardDb = shard.dbType();
ITableShardDbType iTableShardDb = SHARD_DB.computeIfAbsent(shardDb, e -> (ITableShardDbType) getObjectByClass(shardDb));
//获取sql语句
String originSql = boundSql.getSql();
DbType dbType = iTableShardDb.getDbType();
SchemaStatVisitor visitor = SQLUtils.createSchemaStatVisitor(dbType);
List<SQLStatement> stmtList = SQLUtils.parseStatements(originSql, dbType);
Set<String> tableNames = new HashSet<>();
for (int i = 0; i < stmtList.size(); i++) {
SQLStatement stmt = stmtList.get(i);
stmt.accept(visitor);
Map<TableStat.Name, TableStat> tables = visitor.getTables();
for (TableStat.Name name : tables.keySet()) {
tableNames.add(name.getName());
}
}
return tableNames;
}
此时我们已经获取了表名,可以准备构造上面说的映射map了,在此之前先说明下建表逻辑
拿出一个连接,执行用户的方法,可以看到我们当前拦截的方法prepare,第一个参数就是连接

这个时候我们可以直接拿链接进行建表操作(只针对insert操作才进行建表判断),不过出于性能考虑,这里设置了两个校验,第一个是判断本地内存是否已经处理了这些表,第二个是判断数据库里面是否有了这些表,校验通过后,才会执行建表的方法,但如果并发比较高的话,还是可能有多个线程同时走到了建表方法,所以这里建议建表方法使用create if not exists语法
private void handleTableCreate(Invocation invocation, Class<? extends BaseMapper> mapperClass, Map<String, String> routingTableMap, TableShard annotation) throws SQLException {
//代表已经处理了这些表
boolean exec = false;
Collection<String> curTableValues = routingTableMap.values();
for (String value : curTableValues) {
if (!HANDLED_TABLE.contains(value)) {
exec = true;
break;
}
}
if (!exec) {
return;
}
String tableMethod = annotation.createTableMethod();
Method createTableMethod = null;
if (tableMethod.length() > 0) {
createTableMethod = ReflectionUtils.findMethod(mapperClass, tableMethod);
}
//把建表语句对应的sql进行表名的替换,如果该方法有ignore注解,不会进行调用
if (createTableMethod != null && !createTableMethod.isAnnotationPresent(TableShardIgnore.class)) {
SqlSessionFactory sessionFactory = ApplicationContextHolder.getBean(SqlSessionFactory.class);
String methodPath = mapperClass.getName() + "." + tableMethod;
Configuration configuration = sessionFactory.getConfiguration();
String createTableSql = configuration.getMappedStatement(methodPath).getBoundSql("delegate.boundSql").getSql();
//判断是否已经有这个表
Set<String> prepareHandledTable = new HashSet<>();
for (Map.Entry<String, String> entry : routingTableMap.entrySet()) {
if (createTableSql.contains(entry.getKey())) {
prepareHandledTable.add(entry.getValue());
createTableSql = createTableSql.replaceAll(entry.getKey(), entry.getValue());
}
}
//获取一个连接
Connection conn = (Connection) invocation.getArgs()[0];
boolean preAutoCommitState = conn.getAutoCommit();
conn.setAutoCommit(false);
Class<? extends ITableShardDbType> shardDb = annotation.dbType();
ITableShardDbType iTableShardDb = SHARD_DB.computeIfAbsent(shardDb, e -> (ITableShardDbType) getObjectByClass(shardDb));
//如果没有检查sql,默认已经建表
String checkTableSQL = iTableShardDb.getCheckTableSQL(curTableValues);
boolean contains = existsTable(conn, curTableValues, checkTableSQL);
if (contains) {
conn.setAutoCommit(preAutoCommitState);
HANDLED_TABLE.addAll(curTableValues);
return;
}
try (PreparedStatement countStmt = conn.prepareStatement(createTableSql)) {
countStmt.execute();
conn.commit();
} catch (Exception e) {
log.error("自动建表报错", e);
} finally {
//恢复状态
conn.setAutoCommit(preAutoCommitState);
HANDLED_TABLE.addAll(prepareHandledTable);
}
}
}
自动建表逻辑说明完之后,再回到刚刚的映射map的构造上面,一种是通过本地线程的map
Map<String, String> routingTableMap = new HashMap<>(tableNames.size());
if (TableShardHolder.hasVal()) {
for (String tableName : tableNames) {
if (TableShardHolder.containTable(tableName)) {
routingTableMap.put(tableName, TableShardHolder.getReplaceName(tableName));
}
}
}
一种是通过参数+分表策略获取替换后的表
首先通过mapper上面的注解获取默认的分表策略,然后查看方法参数有没有,有的话就以方法参数为准,但是这里也要兼顾了常用的hash逻辑
Class<? extends ITableShardStrategy> shardStrategy = annotation.shardStrategy();
boolean autoHash = false;
if (annotation.hashTableLength() != -1) {
shardStrategy = ITableShardStrategy.HashStrategy.class;
if (TableShardHolder.hashTableLength() == null) {
autoHash = true;
TableShardHolder.hashTableLength(annotation.hashTableLength());
}
}
ITableShardStrategy strategy = SHARD_STRATEGY.computeIfAbsent(shardStrategy, e -> (ITableShardStrategy) getObjectByClass(e));
if (strategy == null) {
return invocation.proceed();
}
Object objFromCurMethod = null;
for (String tableName : tableNames) {
String resName = null;
if (objFromCurMethod == null) {
Pair<Object, ITableShardStrategy> res = getObjFromCurMethod(curMethod.parameters, boundSql, autoHash);
if (res.getRight() != null) {
strategy = res.getRight();
}
objFromCurMethod = res.getLeft();
}
resName = strategy.routingTable(tableName, objFromCurMethod);
routingTableMap.put(tableName, resName);
}
上面这段代码主要获取了实际的分表策略,和对应的参数,然后存入映射表里面,那么如何获取实际的分表策略和参数呢,主要有以下两个方法
通过boundSql对象获取方法参数的实际值,然后遍历获取符合的参数值,如果入参是可迭代的,就拿第一个非可迭代的值作为分表策略的入参,所以要求同一批数据中分表的策略都是一样的,这里由于在拦截器不好做,所以放到了service层去处理
private Pair<Object, ITableShardStrategy> getObjFromCurMethod(Parameter[] parameters, BoundSql boundSql, boolean isAutoHash) {
Object parameterObject = boundSql.getAdditionalParameter("_parameter");
if (parameterObject == null) {
parameterObject = boundSql.getParameterObject();
}
if (parameterObject == null || parameters.length == 0) {
return null;
}
Parameter defaultParam = parameters[0];
ITableShardStrategy res = null;
for (int i = 0; i < parameters.length; i++) {
Parameter cur = parameters[i];
if (cur.isAnnotationPresent(TableShardParam.class)) {
defaultParam = cur;
TableShardParam annotation = cur.getAnnotation(TableShardParam.class);
Class<? extends ITableShardStrategy> shardStrategy = annotation.shardStrategy();
if (isAutoHash && annotation.enableHash()) {
//如果支持hash
shardStrategy = ITableShardStrategy.HashStrategy.class;
//如果当前mapper为hash模式,并且对应的长度不为-1,设置长度
if (annotation.hashTableLength() != -1) {
TableShardHolder.hashTableLength(annotation.hashTableLength());
}
}
res = SHARD_STRATEGY.computeIfAbsent(shardStrategy, e -> (ITableShardStrategy) getObjectByClass(e));
break;
}
}
Object paramValue = null;
if (defaultParam.isAnnotationPresent(Param.class)) {
String value = defaultParam.getAnnotation(Param.class).value();
paramValue = ((MapperMethod.ParamMap) parameterObject).get(value);
} else {
paramValue = parameterObject;
}
return Pair.of(getInnerObj(paramValue), res);
}
private static Object getInnerObj(Object paramValue) {
if (paramValue instanceof Iterable) {
Iterable value = (Iterable) paramValue;
Iterator iterator = value.iterator();
while (iterator.hasNext()) {
return getInnerObj(iterator.next());
}
}
return paramValue;
}
最后就是处理我们的sql,把生成的map进行值替换
private void replaceSql(MetaObject metaObject, BoundSql boundSql, Map<String, String> routingTableMap) {
String sql = boundSql.getSql();
for (Map.Entry<String, String> entry : routingTableMap.entrySet()) {
sql = sql.replaceAll(entry.getKey(), entry.getValue());
}
metaObject.setValue("delegate.boundSql.sql", sql);
}
以上就是整套拦截器的实现代码和思路
四、测试
具体代码可以查看github项目的example模块
测试代码如下
@SpringBootApplication(scanBasePackages = "com.xl.mphelper.*")
@MapperScan(basePackages = "com.xl.mphelper.example.mapper")
@Slf4j
public class MpHelperApplication {
public static void main(String[] args) {
ConfigurableApplicationContext run = SpringApplication.run(MpHelperApplication.class, args);
OrderController controller = run.getBean(OrderController.class);
List<OrderInfo> orderInfos = controller.testAdd();
String suffix = orderInfos.get(0).suffix();
Page<OrderInfo> orderInfoPage = controller.queryByPage(suffix);
log.info("分页查询{}", orderInfoPage.getRecords().size());
List<OrderInfo> query = controller.query(suffix);
log.info("查询所有{}", query.size());
IOrderService service = run.getBean(IOrderService.class);
//自定义service的crud操作
service.testCustomServiceShardCUD();
}
}
测试结果如下
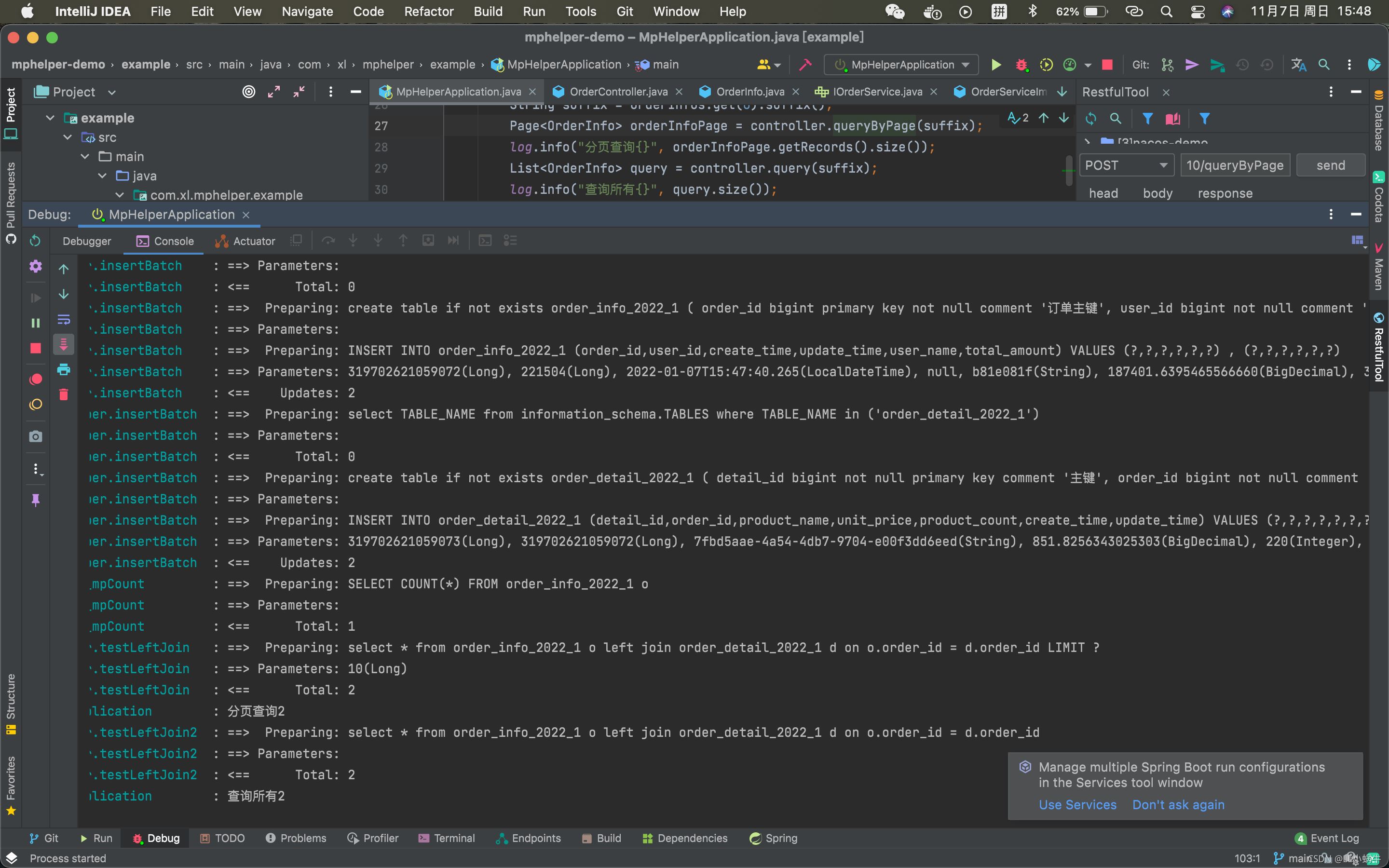
可以看到是先去数据库查询是否存在该表,没有的话就进行建表操作,分页操作通过本地线程进行了表名的替换
接下来是基于service分组的增删改的案例

附上service层实现的方法,主要是根据接口进行分组处理
/**
* 分表新增
* @param entityList
* @return
*/
public boolean saveBatchShard(Collection<T> entityList) {
if (CollectionUtils.isEmpty(entityList)) {
return false;
}
T param = entityList.iterator().next();
if (param instanceof Shardable) {
Collection<Shardable> shardables = (Collection<Shardable>) entityList;
shardables.stream().collect(Collectors.groupingBy(Shardable::suffix)).forEach((k, v) -> {
TableShardHolder.putVal(param.getClass(),k);
super.saveBatch((Collection<T>) v);
TableShardHolder.remove(param.getClass());
});
return true;
}
return false;
}
public boolean updateBatchByShard(Collection<T> entityList){
if (CollectionUtils.isEmpty(entityList)) {
return false;
}
T param = entityList.iterator().next();
if (param instanceof Shardable) {
Collection<Shardable> shardables = (Collection<Shardable>) entityList;
shardables.stream().collect(Collectors.groupingBy(Shardable::suffix)).forEach((k, v) -> {
TableShardHolder.putVal(param.getClass(),k);
super.updateBatchById((Collection<T>) v);
TableShardHolder.remove(param.getClass());
});
return true;
}
return false;
}
/**
* 分表删除
* @param entityList
* @return
*/
public boolean removeByShard(Collection<T> entityList){
if (CollectionUtils.isEmpty(entityList)) {
return false;
}
T param = entityList.iterator().next();
if (param instanceof Shardable) {
Collection<Shardable> shardables = (Collection<Shardable>) entityList;
String keyProperty = getKeyPropertyFromLists(entityList);
shardables.stream().collect(Collectors.groupingBy(Shardable::suffix)).forEach((k, v) -> {
TableShardHolder.putVal(param.getClass(),k);
List<Serializable> id=new ArrayList<>(v.size());;
for (Shardable shardable : v) {
Serializable idValue = (Serializable) ReflectionKit.getFieldValue(shardable, keyProperty);
if(Objects.nonNull(idValue)){
id.add(idValue);
}
}
super.removeByIds(id);
TableShardHolder.remove(param.getClass());
});
return true;
}
return false;
}
为了简化操作,这里对hash,本地线程替换的方法抽取出来
public void wrapRunnable(Runnable runnable, Map<Class, String> map) {
putValIfExistHashStrategy();
for (Map.Entry<Class, String> entry : map.entrySet()) {
TableShardHolder.putVal(entry.getKey(), entry.getValue());
}
runnable.run();
for (Map.Entry<Class, String> entry : map.entrySet()) {
TableShardHolder.remove(entry.getKey());
}
TableShardHolder.clearHashTableLength();
}
public void putValIfExistHashStrategy() {
TableShard annotation = mapperClass.getAnnotation(TableShard.class);
if (annotation == null) {
throw new IllegalStateException("not found tableShard in mapper");
}
int i = annotation.hashTableLength();
if (i != -1) {
TableShardHolder.hashTableLength(i);
}
}
这里的查询采用本地线程调用,也是通过包装对通用的操作进行屏蔽
Page<OrderInfo> page = new Page<>();
Page<OrderInfo> res = (Page<OrderInfo>) wrapSupplier(() -> orderInfoMapper.testLeftJoin(page, month), KVBuilder.init(OrderInfo.class, month).put(OrderDetail.class, month)
);
return res;
也可以直接通过mapper方法的参数进行表路由的操作
关于hash有个额外注意点——如果mapper是hash策略,且本地线程没有指定hash策略,而方法上面指定了param参数且没有开启enableHash,就会走到默认的分表策略
List<OrderInfo> testLeftJoin2(@TableShardParam String month);
然后是hash路由的测试,把对应的注解注释打开
//@TableShard(enableCreateTable = true, createTableMethod = "createTable")
@TableShard(enableCreateTable = true,createTableMethod = "createTable", hashTableLength = 10)
public interface OrderDetailMapper extends CustomMapper<OrderDetail> {
void createTable();
}
//@TableShard(enableCreateTable = true, createTableMethod = "createTable")
@TableShard(enableCreateTable = true, createTableMethod = "createTable", hashTableLength = 10)
public interface OrderInfoMapper extends CustomMapper<OrderInfo> {
void createTable();
//注意,这里调用的service层没设置本地线程变量,如果enableHash也为false,则不会调用hash策略
List<OrderInfo> testLeftJoin2(@TableShardParam(enableHash = true)
//@TableShardParam
String month);
Page<OrderInfo> testLeftJoin(IPage page, @TableShardParam String month);
@TableShardIgnore
@Select("select * from order_info where update_time is null")
Cursor<OrderInfo> test();
}
测试结果

也可以看到对应的数据库表已经建立起来

后记
以上是全部内容,在做的时候也参考了别人的一些做法,结合了自己的一些想法,最后形成本文,代码已上传的到GitHub, 有兴趣的小伙伴可以下来看看,里面有一些关于sqlInject的用法,具体解析可以参考我另一篇博文,但这些还是有很多改进的点,主要是属性写死在代码里面,不是很灵活,比如把注解上面的属性改为配置处理,以适配不同环境等
加载全部内容