pytorch神经网络Dropout应用 Python深度学习pytorch神经网络Dropout应用详解解
Supre_yuan 人气:0想了解Python深度学习pytorch神经网络Dropout应用详解解的相关内容吗,Supre_yuan在本文为您仔细讲解pytorch神经网络Dropout应用的相关知识和一些Code实例,欢迎阅读和指正,我们先划重点:Python深度学习,pytorch神经网络Dropout应用,下面大家一起来学习吧。
扰动的鲁棒性
在之前我们讨论权重衰减(L2正则化)时看到的那样,参数的范数也代表了一种有用的简单性度量。简单性的另一个有用角度是平滑性,即函数不应该对其输入的微笑变化敏感。例如,当我们对图像进行分类时,我们预计向像素添加一些随机噪声应该是基本无影响的。
dropout在正向传播过程中,计算每一内部层同时注入噪声,这已经成为训练神经网络的标准技术。这种方法之所以被称为dropout,因为我们从表面上看是在训练过程中丢弃(drop out)一些神经元。在整个训练过程的每一次迭代中,dropout包括在计算下一层之前将当前层中的一些节点置零。
那么关键的挑战就是如何注入这种噪声,一种想法是以一种无偏的方式注入噪声。这样在固定住其他层时,每一层的期望值等于没有噪音时的值。

实践中的dropout
之前多层感知机是带有一个隐藏层和5个隐藏单元的。当我们将dropout应用到隐藏层时,以 p的概率将隐藏单元置为零时,结果可以看作是一个只包含原始神经元子集的网络。右图中,删除了 h2和 h5。因此,输出的计算不再依赖于 h2或 h5,并且它们各自的梯度在执行反向传播时也会消失。这样,输出层的计算不能过度依赖于 h1,…,h5的任何一个元素。
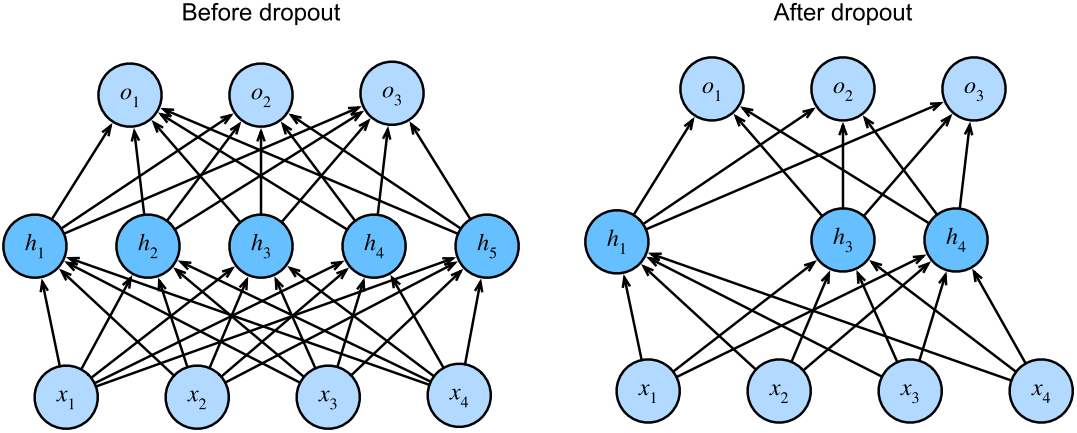
通常,我们在测试时仅用dropout。给定一个训练好的模型和一个新的样本,我们不会丢弃任何节点,因此不需要标准化。
简洁实现
对于高级API,我们所需要做的就是在每个全连接层之后添加一个Dropout层,将丢弃概率作为唯一的参数传递给它的构造函数。在训练过程中,Dropout层将根据指定的丢弃概率随机丢弃上一层的输出(相当于下一层的输入)。当不处于训练模式时,Dropout层仅在测试时传递数据。
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 256), nn.ReLU(), # 在第一个全连接层之后添加一个dropout层 nn.Dropout(dropout1), nn.Linear(256, 256), nn.ReLU(), # 在第二个全连接层之后添加一个dropout层 nn.Dropout(dropout2), nn.Linear(256, 10)) def init_weights(m): if type(m) == nn.Linear: nn.init.normal_(m.weight, std=0.01) net.apply(init_weights)
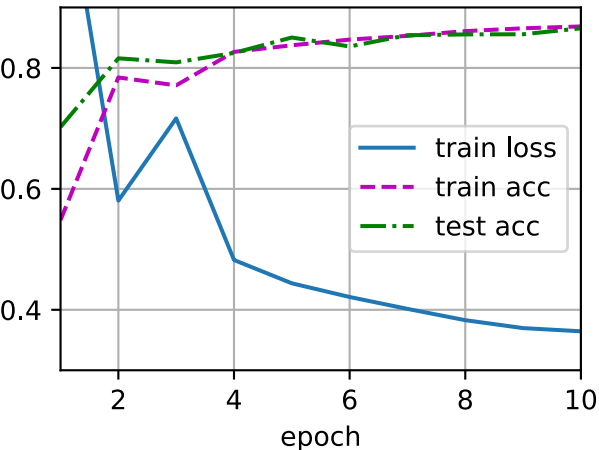
接下来,我们对模型进行训练和测试。
trainer = torch.optim.SGD(net.parameters(), lr=lr) d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
加载全部内容