pytorch卷积神经网络LeNet Python深度学习pytorch卷积神经网络LeNet
Supre_yuan 人气:0在本节中,我们将介绍LeNet,它是最早发布的卷积神经网络之一。这个模型是由AT&T贝尔实验室的研究院Yann LeCun在1989年提出的(并以其命名),目的是识别手写数字。当时,LeNet取得了与支持向量机性能相媲美的成果,成为监督学习的主流方法。LeNet被广泛用于自动取款机中,帮助识别处理支票的数字。
LeNet
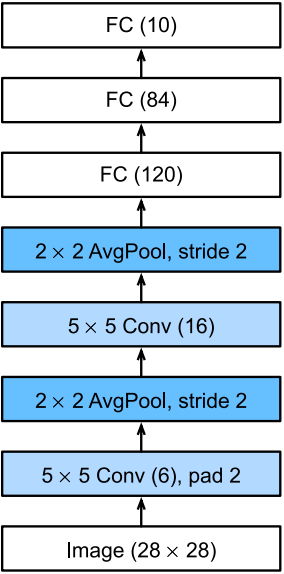
总体来看,LeNet(LeNet-5)由两个部分组成:
- 卷积编码器: 由两个卷积层组成
- 全连接层密集快: 由三个全连接层组成

每个卷积块中的基本单元是一个卷积层、一个sigmoid激活函数和平均池化层。这里,虽然ReLU和最大池化层更有效,但它们在20世纪90年代还没有出现。每个卷积层使用 5 × 5 5\times5 5×5卷积核和一个sigmoid激活函数。这些层将输入映射到多个二维特征输出,通常同时增加通道的数量。第一卷积层有6个输出通道,而第二个卷积层有16个输出通道。每个 2 × 2 2\times2 2×2池操作通过空间下采样将维数减少4倍。
为了将卷积块中的输出传递给稠密块,我们必须在小批量中战平每个样本。LeNet的稠密快有三个全连接层,分别有120、84和10个输出。因为我们仍在执行分类,所以输出层的10维对应于最后输出结果的数量。
通过下面的LeNet代码,我们会相信深度学习框架实现此类模型非常简单。我们只需要实例化一个Sequential块并将需要的层连接在一起。
import torch from torch import nn from d2l import torch as d2l class Reshape(torch.nn.Module): def forward(self, x): return x.view(-1, 1, 28, 28) net = torch.nn.Sequential( Reshape(), nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(), nn.AvgPool2d(kernel_size=2, stride=2), nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(), nn.AvgPool2d(kernel_size=2, stride=2), nn.Flatten(), nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(), nn.Linear(120, 84), nn.Sigmoid(), nn.Linear(84, 10) )
我们对原始模型做了一点小改动,去掉了最后一层的高斯激活。除此之外,这个网络与最初的LeNet-5一致。下面,我们将一个大小为 28 × 28 28\times28 28×28的单通道(黑白)图像通过LeNet。通过在每一层打印输出的形状,我们可以检查模型,以确保其操作与我们期望的下图一致。
X = torch.rand(size=(1, 1, 28, 28), dtype=torch.float32) for layer in net: X = layer(X) print(layer.__class__.__name__, 'output shape: \t', X.shape)
Reshape output shape: torch.Size([1, 1, 28, 28]) Conv2d output shape: torch.Size([1, 6, 28, 28]) Sigmoid output shape: torch.Size([1, 6, 28, 28]) AvgPool2d output shape: torch.Size([1, 6, 14, 14]) Conv2d output shape: torch.Size([1, 16, 10, 10]) Sigmoid output shape: torch.Size([1, 16, 10, 10]) AvgPool2d output shape: torch.Size([1, 16, 5, 5]) Flatten output shape: torch.Size([1, 400]) Linear output shape: torch.Size([1, 120]) Sigmoid output shape: torch.Size([1, 120]) Linear output shape: torch.Size([1, 84]) Sigmoid output shape: torch.Size([1, 84]) Linear output shape: torch.Size([1, 10])
请注意,在整个卷积块中,与上一层相比,每一层特征的高度和宽度都减小了。第一个卷积层使用2个像素的填充,来补偿 5 × 5 卷积核导致的特征减少。相反,第二个卷积层没有填充,因此高度和宽度都减少了4个像素。随着层叠的上升,通道的数量从输入时的1个,增加到第一个卷积层之后的6个,再到第二个卷积层之后的16个。同时,每个汇聚层的高度和宽度都减半。最后,每个全连接层减少维度,最终输出一个维数与结果分类数相匹配的输出。
模型训练
现在我们已经实现了LeNet,让我们看看LeNet在Fashion-MNIST数据集上的表现。
batch_size = 256 train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size = batch_size)
虽然卷积神经网络的参数较少,但与深度的多层感知机相比,它们的计算成本仍然很高,因为每个参数都参与更多的乘法。
如果我们有机会使用GPU,可以用它加快训练。
加载全部内容