Python爬取漫画 再也不用花钱买漫画!Python爬取某漫画的脚本及源码
程序猿中的BUG 人气:0想了解再也不用花钱买漫画!Python爬取某漫画的脚本及源码的相关内容吗,程序猿中的BUG在本文为您仔细讲解Python爬取漫画的相关知识和一些Code实例,欢迎阅读和指正,我们先划重点:Python爬取漫画,Python爬虫,下面大家一起来学习吧。
一、工具
- python3
- 第三方类库requests
- python3-pyqt5(GUI依赖,不用GUI可不装)
ubuntu系列系统使用以下命令安装依赖:
URL格式: 漫画首页的URL,如http://m.ac.qq.com/Comic/view/id/518333(移动版) 或 http://ac.qq.com/Comic/comicInfo/id/17114, http://ac.qq.com/naruto(PC版)
注意: 火影忍者彩漫需要访问m.ac.qq.com搜索火影忍者,因为PC端页面火影忍者彩漫和黑白漫画是一个id一个url。
二、命令行帮助
usage: getComic.py [-h] [-u URL] [-p PATH] [-d] [-l LIST]
*下载腾讯漫画,仅供学习交流,请勿用于非法用途*
空参运行进入交互式模式运行。
optional arguments:
-h, --help show this help message and exit
-u URL, --url URL 要下载的漫画的首页,可以下载以下类型的url:
http://ac.qq.com/Comic/comicInfo/id/511915
http://m.ac.qq.com/Comic/comicInfo/id/505430
http://pad.ac.qq.com/Comic/comicInfo/id/505430
http://ac.qq.com/naruto
-p PATH, --path PATH 漫画下载路径。 默认: /home/fengyu/tencent_comic
-d, --dir 将所有图片下载到一个目录(适合腾讯漫画等软件连看使用)
-l LIST, --list LIST 要下载的漫画章节列表,不指定则下载所有章节。格式范例:
N - 下载具体某一章节,如-l 1, 下载第1章
N,N... - 下载某几个不连续的章节,如 "-l 1,3,5", 下载1,3,5章
N-N... - 下载某一段连续的章节,如 "-l 10-50", 下载[10,50]章
杂合型 - 结合上面所有的规则,如 "-l 1,3,5-7,11-111"
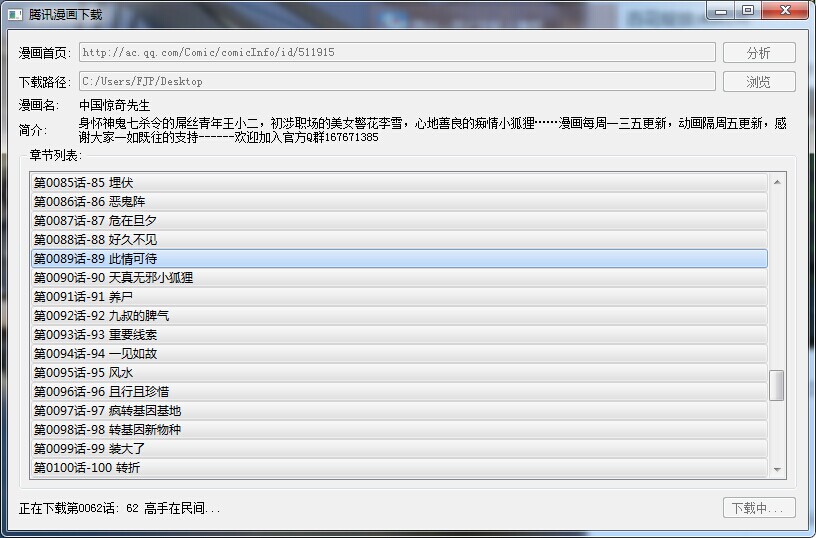
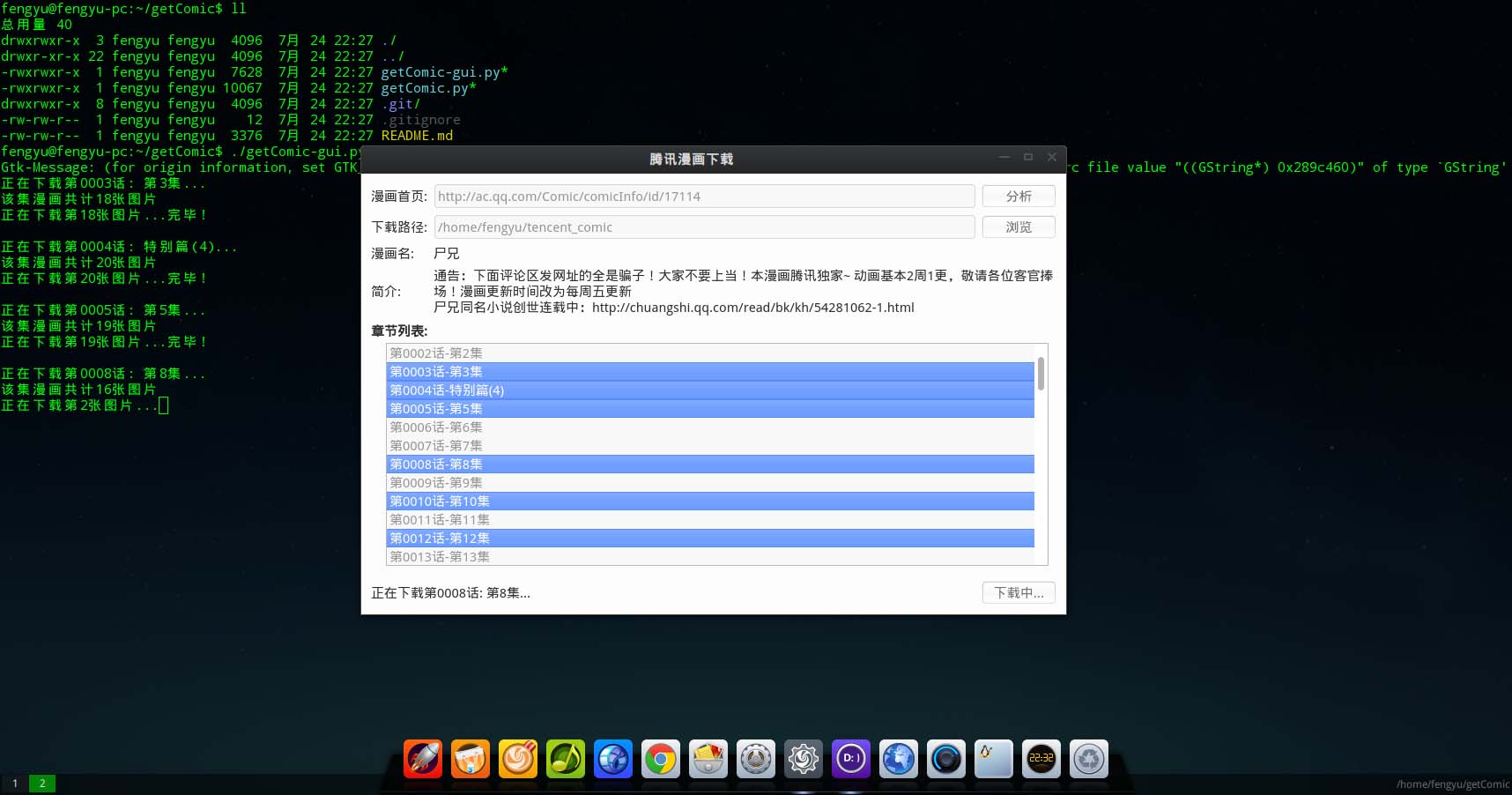
三、GUI预览效果
支持不连续的章节选择下载
windows预览效果:

deepin/Linux 预览效果:
四、全部源码
import requests
import re
import json
import os
import argparse
requestSession = requests.session()
UA = 'Mozilla/5.0 (iPad; CPU OS 5_1 like Mac OS X; en-us) \
AppleWebKit/534.46 (KHTML, like Gecko) Version/5.1 \
Mobile/9B176 Safari/7534.48.3' # ipad UA
requestSession.headers.update({'User-Agent': UA})
class ErrorCode(Exception):
'''自定义错误码:
1: URL不正确
2: URL无法跳转为移动端URL
3: 中断下载'''
def __init__(self, code):
self.code = code
def __str__(self):
return repr(self.code)
def isLegelUrl(url):
legal_url_list = [
re.compile(r'^http://ac.qq.com/Comic/[Cc]omicInfo/id/\d+/?$'),
re.compile(r'^http://m.ac.qq.com/Comic/[Cc]omicInfo/id/\d+/?$'),
re.compile(r'^http://ac.qq.com/\w+/?$'),
re.compile(r'^http://pad.ac.qq.com/Comic/[Cc]omicInfo/id/\d+/?$')
]
for legal_url in legal_url_list:
if legal_url.match(url):
return True
return False
def getId(url):
if not isLegelUrl(url):
print('请输入正确的url!具体支持的url请在命令行输入-h|--help参数查看帮助文档。')
raise ErrorCode(1)
numRE = re.compile(r'\d+$')
id = numRE.findall(url)
if not id:
get_id_request = requestSession.get(url)
url = get_id_request.url
id = numRE.findall(url)
if not isLegelUrl(url) or not id:
print('无法自动跳转移动端URL,请进入http://m.ac.qq.com,找到'
'该漫画地址。\n'
'地址应该像这样: '
'http://m.ac.qq.com/Comic/comicInfo/id/xxxxx (xxxxx为整数)')
raise ErrorCode(2)
return id[0]
def getContent(id):
getComicInfoUrl = 'http://pad.ac.qq.com/GetData/getComicInfo?id={}'.format(id)
requestSession.headers.update({'Cookie': 'ac_refer=http://pad.ac.qq.com'})
requestSession.headers.update({'Referer': 'http://pad.ac.qq.com'})
getComicInfo = requestSession.get(getComicInfoUrl)
comicInfoJson = getComicInfo.text
comicInfo = json.loads(comicInfoJson)
comicName = comicInfo['title']
comicIntrd = comicInfo['brief_intrd']
getChapterListUrl = 'http://pad.ac.qq.com/GetData/getChapterList?id={}'.format(id)
getChapterList = requestSession.get(getChapterListUrl)
contentJson = json.loads(getChapterList.text)
count = contentJson['length']
sortedContentList = []
for i in range(count + 1):
for item in contentJson:
if isinstance(contentJson[item], dict) and contentJson[item].get('seq') == i:
sortedContentList.append({item: contentJson[item]})
break
return (comicName, comicIntrd, count, sortedContentList)
def getImgList(contentJson, id):
cid = list(contentJson.keys())[0]
getPicHashURL = 'http://pad.ac.qq.com/View/mGetPicHash?id={}&cid={}'.format(id, cid)
picJsonPage = requestSession.get(getPicHashURL).text
picJson = json.loads(picJsonPage)
count = picJson['pCount'] #统计图片数量
pHash = picJson['pHash']
sortedImgDictList = []
for i in range(1, count + 1):
for item in pHash:
if pHash[item]['seq'] == i:
sortedImgDictList.append(pHash[item])
break
imgList = []
for imgDict in sortedImgDictList:
k = imgDict['cid']
m = imgDict['pid']
j = int(id)
uin = max(j + k + m, 10001)
l = [j % 1000 // 100, j % 100, j, k]
n = '/mif800/' + '/'.join(str(j) for j in l) + '/'
h = str(m) + '.mif2'
g="http://ac.tc.qq.com/store_file_download?buid=15017&uin="+str(uin)+"&dir_path="+n+"&name="+h
imgList.append(g)
return imgList
def downloadImg(imgUrlList, contentPath, one_folder=False):
count = len(imgUrlList)
print('该集漫画共计{}张图片'.format(count))
i = 1
for imgUrl in imgUrlList:
print('\r正在下载第{}张图片...'.format(i), end = '')
if not one_folder:
imgPath = os.path.join(contentPath, '{0:0>3}.jpg'.format(i))
else:
imgPath = contentPath + '{0:0>3}.jpg'.format(i)
i += 1
#目标文件存在就跳过下载
if os.path.isfile(imgPath):
continue
try:
downloadRequest = requestSession.get(imgUrl, stream=True)
with open(imgPath, 'wb') as f:
for chunk in downloadRequest.iter_content(chunk_size=1024):
if chunk: # filter out keep-alive new chunks
f.write(chunk)
f.flush()
except (KeyboardInterrupt, SystemExit):
print('\n\n中断下载,删除未下载完的文件!')
if os.path.isfile(imgPath):
os.remove(imgPath)
raise ErrorCode(3)
print('完毕!\n')
def parseLIST(lst):
'''解析命令行中的-l|--list参数,返回解析后的章节列表'''
legalListRE = re.compile(r'^\d+([,-]\d+)*$')
if not legalListRE.match(lst):
raise LISTFormatError(lst + ' 不匹配正则: ' + r'^\d+([,-]\d+)*$')
#先逗号分割字符串,分割后的字符串再用短横杠分割
parsedLIST = []
sublist = lst.split(',')
numRE = re.compile(r'^\d+$')
for sub in sublist:
if numRE.match(sub):
if int(sub) > 0: #自动忽略掉数字0
parsedLIST.append(int(sub))
else:
print('警告: 参数中包括不存在的章节0,自动忽略')
else:
splitnum = list(map(int, sub.split('-')))
maxnum = max(splitnum)
minnum = min(splitnum) #min-max或max-min都支持
if minnum == 0:
minnum = 1 #忽略数字0
print('警告: 参数中包括不存在的章节0,自动忽略')
parsedLIST.extend(range(minnum, maxnum+1))
parsedLIST = sorted(set(parsedLIST)) #按照从小到大的顺序排序并去重
return parsedLIST
def main(url, path, lst=None, one_folder=False):
'''url: 要爬取的漫画首页。 path: 漫画下载路径。 lst: 要下载的章节列表(-l|--list后面的参数)'''
try:
if not os.path.isdir(path):
os.makedirs(path)
id = getId(url)
comicName,comicIntrd,count,contentList = getContent(id)
contentNameList = []
for item in contentList:
for k in item:
contentNameList.append(item[k]['t'])
print('漫画名: {}'.format(comicName))
print('简介: {}'.format(comicIntrd))
print('章节数: {}'.format(count))
print('章节列表:')
try:
print('\n'.join(contentNameList))
except Exception:
print('章节列表包含无法解析的特殊字符\n')
forbiddenRE = re.compile(r'[\\/":*?<>|]') #windows下文件名非法字符\ / : * ? " < > |
comicName = re.sub(forbiddenRE, '_', comicName) #将windows下的非法字符一律替换为_
comicPath = os.path.join(path, comicName)
if not os.path.isdir(comicPath):
os.makedirs(comicPath)
print()
if not lst:
contentRange = range(1, len(contentList) + 1)
else:
contentRange = parseLIST(lst)
for i in contentRange:
if i > len(contentList):
print('警告: 章节总数 {} ,'
'参数中包含过大数值,'
'自动忽略'.format(len(contentList)))
break
contentNameList[i - 1] = re.sub(forbiddenRE, '_', contentNameList[i - 1]) #将windows下的非法字符一律替换为_
contentPath = os.path.join(comicPath, '第{0:0>4}话-{1}'.format(i, contentNameList[i - 1]))
try:
print('正在下载第{0:0>4}话: {1}'.format(i, contentNameList[i -1]))
except Exception:
print('正在下载第{0:0>4}话: {1}'.format(i))
if not one_folder:
if not os.path.isdir(contentPath):
os.mkdir(contentPath)
imgList = getImgList(contentList[i - 1], id)
downloadImg(imgList, contentPath, one_folder)
except ErrorCode as e:
exit(e.code)
if __name__ == '__main__':
defaultPath = os.path.join(os.path.expanduser('~'), 'tencent_comic')
parser = argparse.ArgumentParser(formatter_class=argparse.RawTextHelpFormatter,
description='*下载腾讯漫画,仅供学习交流,请勿用于非法用途*\n'
'空参运行进入交互式模式运行。')
parser.add_argument('-u', '--url', help='要下载的漫画的首页,可以下载以下类型的url: \n'
'http://ac.qq.com/Comic/comicInfo/id/511915\n'
'http://m.ac.qq.com/Comic/comicInfo/id/505430\n'
'http://pad.ac.qq.com/Comic/comicInfo/id/505430\n'
'http://ac.qq.com/naruto')
parser.add_argument('-p', '--path', help='漫画下载路径。 默认: {}'.format(defaultPath),
default=defaultPath)
parser.add_argument('-d', '--dir', action='store_true', help='将所有图片下载到一个目录(适合腾讯漫画等软件连看使用)')
parser.add_argument('-l', '--list', help=("要下载的漫画章节列表,不指定则下载所有章节。格式范例: \n"
"N - 下载具体某一章节,如-l 1, 下载第1章\n"
'N,N... - 下载某几个不连续的章节,如 "-l 1,3,5", 下载1,3,5章\n'
'N-N... - 下载某一段连续的章节,如 "-l 10-50", 下载[10,50]章\n'
'杂合型 - 结合上面所有的规则,如 "-l 1,3,5-7,11-111"'))
args = parser.parse_args()
url = args.url
path = args.path
lst = args.list
one_folder = args.dir
if lst:
legalListRE = re.compile(r'^\d+([,-]\d+)*$')
if not legalListRE.match(lst):
print('LIST参数不合法,请参考--help键入合法参数!')
exit(1)
if not url:
url = input('请输入漫画首页地址: ')
path = input('请输入漫画保存路径(默认: {}): '.format(defaultPath))
if not path:
path = defaultPath
main(url, path, lst, one_folder)
五、下载源码
from PyQt5.QtCore import *
from PyQt5.QtWidgets import *
from PyQt5.QtGui import *
import getComic
import os
import re
import sys
class TencentComicDownloader(QWidget):
def __init__(self, parent=None):
super(TencentComicDownloader, self).__init__(parent)
nameLabel = QLabel("漫画首页:")
self.nameLine = QLineEdit()
self.analysisButton = QPushButton("分析")
self.analysisButton.clicked.connect(self.anaysisURL)
self.nameLine.returnPressed.connect(self.analysisButton.click)
pathLineLabel = QLabel("下载路径:")
self.pathLine = QLineEdit()
defaultPath = os.path.join(os.path.expanduser('~'), 'tencent_comic')
self.pathLine.setText(defaultPath)
self.browseButton = QPushButton("浏览")
self.browseButton.clicked.connect(self.getPath)
comicNameLabel = QLabel("漫画名: ")
self.comicNameLabel = QLabel("暂无")
self.one_folder_checkbox = QCheckBox("单目录")
comicIntroLabel = QLabel("简介: ")
self.comicIntro = QLabel("暂无")
self.comicIntro.setWordWrap(True)
chapterGroupBox = QGroupBox("章节列表:")
self.chapterListView = QListWidget(chapterGroupBox)
self.chapterListView.setSelectionMode(QAbstractItemView.ExtendedSelection)
self.chapterListView.setEnabled(False)
groupBoxLayout = QHBoxLayout(chapterGroupBox)
groupBoxLayout.addWidget(self.chapterListView)
self.downloadButton = QPushButton("下载选中")
self.statusLabel = QLabel("输入要下载的漫画的首页,然后点分析")
self.statusLabel.setWordWrap(True)
self.downloadButton.setEnabled(False)
self.downloadButton.clicked.connect(self.download)
mainLayout = QGridLayout()
mainLayout.addWidget(nameLabel, 0, 0)
mainLayout.addWidget(self.nameLine, 0, 1)
mainLayout.addWidget(self.analysisButton, 0, 2)
mainLayout.addWidget(pathLineLabel, 1, 0)
mainLayout.addWidget(self.pathLine, 1, 1)
mainLayout.addWidget(self.browseButton, 1, 2)
mainLayout.addWidget(comicNameLabel, 2, 0)
mainLayout.addWidget(self.comicNameLabel, 2, 1, 1, 2)
mainLayout.addWidget(self.one_folder_checkbox, 2, 2)
mainLayout.addWidget(comicIntroLabel, 3, 0)
mainLayout.addWidget(self.comicIntro, 3, 1, 1, 2)
mainLayout.addWidget(chapterGroupBox, 4, 0, 1, 3)
mainLayout.addWidget(self.downloadButton, 5, 2)
mainLayout.addWidget(self.statusLabel, 5, 0, 1, 2)
self.setLayout(mainLayout)
self.setWindowTitle("腾讯漫画下载")
self.setGeometry(400, 300, 800, 500)
def setStatus(self, status):
self.statusLabel.setText(status)
def enableWidget(self, enable):
widgets_list = [
self.downloadButton,
self.nameLine,
self.pathLine,
self.chapterListView,
self.analysisButton,
self.browseButton,
self.one_folder_checkbox
]
for widget in widgets_list:
widget.setEnabled(enable)
if enable:
self.downloadButton.setText('下载选中')
self.chapterListView.setFocus()
def getPath(self):
path = str(QFileDialog.getExistingDirectory(self, "选择下载目录"))
if path:
self.pathLine.setText(path)
def anaysisURL(self):
url = self.nameLine.text()
self.downloadButton.setEnabled(False)
self.comicNameLabel.setText("暂无")
self.comicIntro.setText("暂无")
self.chapterListView.clear()
self.chapterListView.setEnabled(False)
try:
if getComic.isLegelUrl(url):
self.id = getComic.getId(url)
self.comicName,self.comicIntrd,self.count,self.contentList = getComic.getContent(self.id)
self.contentNameList = []
for item in self.contentList:
for k in item:
self.contentNameList.append(item[k]['t'])
self.comicNameLabel.setText(self.comicName)
self.comicIntro.setText(self.comicIntrd)
self.chapterListView.setEnabled(True)
self.downloadButton.setEnabled(True)
self.chapterListView.setFocus()
self.statusLabel.setText('选择要下载的章节后点击右侧按钮')
for i in range(len(self.contentNameList)):
self.chapterListView.addItem('第{0:0>4}话-{1}'.format(i+1, self.contentNameList[i]))
self.chapterListView.item(i).setSelected(True)
self.downloadButton.setEnabled(True)
else:
self.statusLabel.setText('<font color="red">错误的URL格式!请输入正确的漫画首页地址!</font>')
except getComic.ErrorCode as e:
if e.code == 2:
self.statusLabel.setText('<font color="red">无法跳转为移动端URL,请进入http://m.ac.qq.com找到该漫画地址</font>')
except KeyError:
self.statusLabel.setText('<font color="red">不存在的地址</font>')
def download(self):
self.downloadButton.setText("下载中...")
one_folder = self.one_folder_checkbox.isChecked()
self.enableWidget(False)
selectedChapterList = [ item.row() for item in self.chapterListView.selectedIndexes() ]
path = self.pathLine.text()
comicName = self.comicName
forbiddenRE = re.compile(r'[\\/":*?<>|]') #windows下文件名非法字符\ / : * ? " < > |
comicName = re.sub(forbiddenRE, '_', comicName) #将windows下的非法字符一律替换为_
comicPath = os.path.join(path, comicName)
if not os.path.isdir(comicPath):
os.makedirs(comicPath)
self.downloadThread = Downloader(selectedChapterList, comicPath, self.contentList, self.contentNameList, self.id, one_folder)
self.downloadThread.output.connect(self.setStatus)
self.downloadThread.finished.connect(lambda: self.enableWidget(True))
self.downloadThread.start()
class Downloader(QThread):
output = pyqtSignal(['QString'])
finished = pyqtSignal()
def __init__(self, selectedChapterList, comicPath, contentList, contentNameList, id, one_folder=False, parent=None):
super(Downloader, self).__init__(parent)
self.selectedChapterList = selectedChapterList
self.comicPath = comicPath
self.contentList = contentList
self.contentNameList = contentNameList
self.id = id
self.one_folder = one_folder
def run(self):
try:
for i in self.selectedChapterList:
outputString = '正在下载第{0:0>4}话: {1}...'.format(i+1, self.contentNameList[i])
print(outputString)
self.output.emit(outputString)
forbiddenRE = re.compile(r'[\\/":*?<>|]') #windows下文件名非法字符\ / : * ? " < > |
self.contentNameList[i] = re.sub(forbiddenRE, '_', self.contentNameList[i])
contentPath = os.path.join(self.comicPath, '第{0:0>4}话-{1}'.format(i+1, self.contentNameList[i]))
if not self.one_folder:
if not os.path.isdir(contentPath):
os.mkdir(contentPath)
imgList = getComic.getImgList(self.contentList[i], self.id)
getComic.downloadImg(imgList, contentPath, self.one_folder)
self.output.emit('完毕!')
except Exception as e:
self.output.emit('<font color="red">{}</font>\n'
'遇到异常!请尝试重新点击下载按钮重试'.format(e))
raise
finally:
self.finished.emit()
if __name__ == '__main__':
app = QApplication(sys.argv)
main = TencentComicDownloader()
main.show()
app.exec_()
加载全部内容