Python爬虫基础selenium Python爬虫基础初探selenium
松鼠爱吃饼干 人气:0Python爬虫、数据分析、网站开发等案例教程视频免费在线观看
https://space.bilibili.com/523606542
Selenium
Selenium是一个Web的自动化测试工具,最初是为网站自动化测试而开发的,就像玩游戏用的按键精灵,可以按指定的命令自动操作。
Selenium测试工具直接操控浏览器中,就像真正的用户在操作一样。Selenium可以根据的指令,让浏览器自动加载页面,获取需要的数据,甚至页面截屏,或者判断网站上某些动作是否发生等。
selenium的用途
(1)、selenium可以驱动浏览器自动执行自定义好的逻辑代码,也就是可以通过代码完全模拟成人类使用浏览器自动访问目标站点并操作,那我们也可以拿它来做爬虫。
(2)、selenium本质上是通过驱动浏览器,完全模拟浏览器的操作,比如跳转、输入、点击、下拉等...进而拿到网页渲染之后的结果,可支持多种浏览器
selenium是优缺点
(1)优点
优点就是可以帮我们避开一系列复杂的通信流程,例如在我们之前学习的requests模块,那么requests模块在模拟请求的时候是不是需要把素有的通信流程都分析完成后才能通过请求,然后返回响应。假如目标站点有一系列复杂的通信流程,例如的登录时的滑动验证等...那么你使用requests模块的时候是不是就特别麻烦了。不过你也不需要担心,因为网站的反爬策略越高,那么用户的体验效果就越差,所以网站都需要在用户的淫威之下降低安全策略。
再看一点requests请求库能不能执行js?是不是不能呀!那么如果你的网站需要发送ajax请求,异步获取数据渲染到页面上,是不是就需要使用js发送请求了。那浏览器的特点是什么?是不是可以直接访问目标站点,然后获取对方的数据,从而渲染到页面上。那这些就是使用selenium的好处!
(2)缺点
使用selenium本质上是驱动浏览器对目标站点发送请求,那浏览器在访问目标站点的时候,是不是都需要把静态资源都加载完毕。html、css、js这些文件是不是都要等待它加载完成。是不是速度特别慢。那用它的坏处就是效率极低!所以我们一般用它来做登录验证。
1. Selenium工作原理

如图所示,通过Python来控制Selenium,然后让Selenium 控制浏览器,操纵浏览器,这样就实现了使用Python间接的操控浏览器。
1.1 Selenium配置
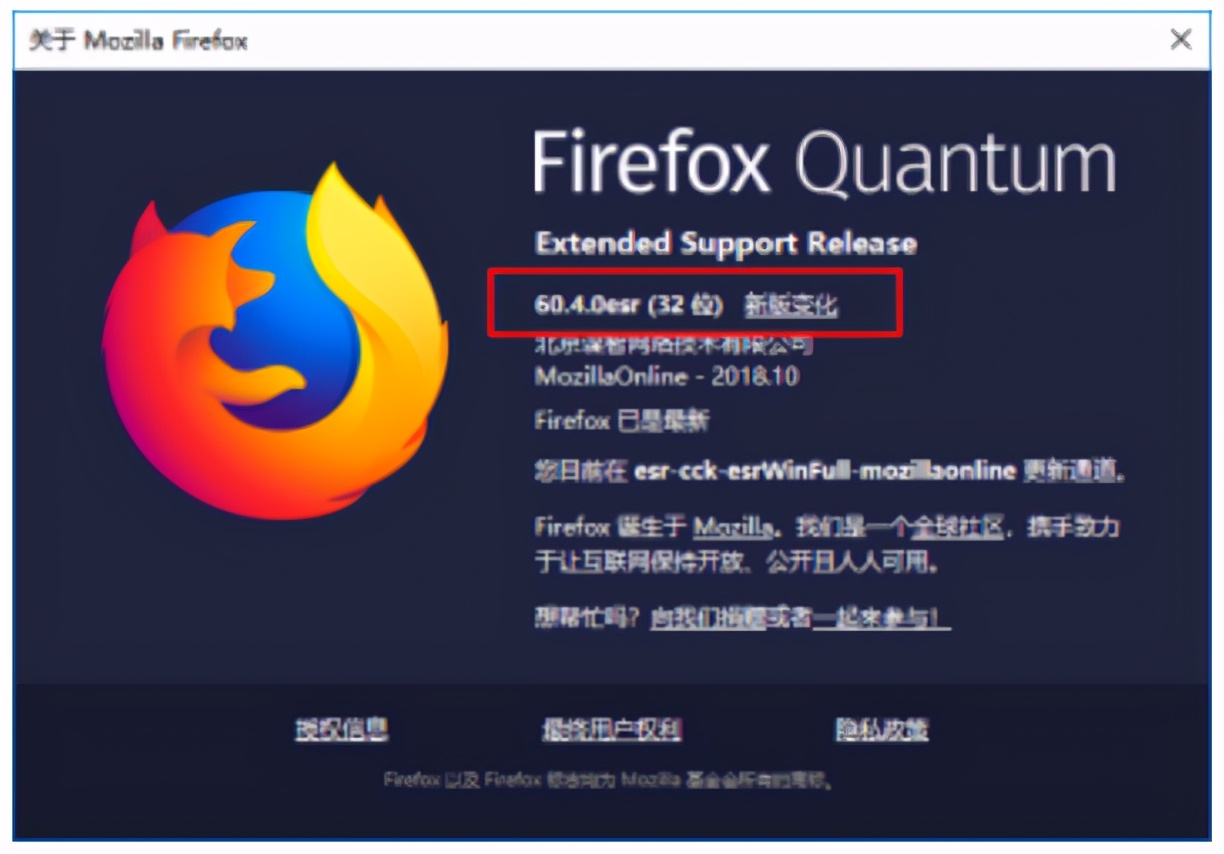
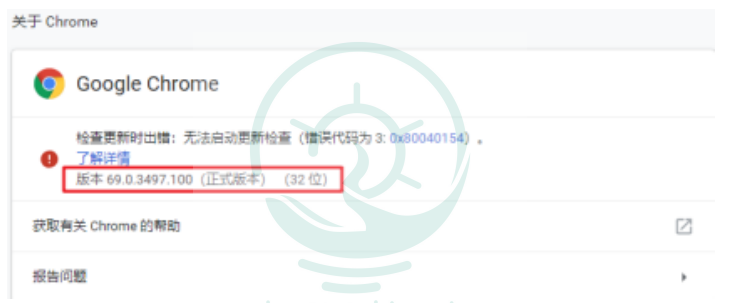
Selenium支持多种浏览器,最常见的就是火狐和谷歌浏览器。首先在电脑上下载浏览器,浏览器版本不宜过新。
火狐:截图如下
谷歌:截图如下
1.2 浏览器驱动
Selenium具体怎么就能操纵浏览器呢?这要归功于浏览器驱动,Selenium可以通过API接口实现和浏览器驱动的交互,进而实现和浏览器的交互。所以要配置浏览器驱动。
火狐驱动下载地址:
http://npm.taobao.org/mirrors/geckodriver/
谷歌驱动下载地址:
https://npm.taobao.org/mirrors/chromedriver/
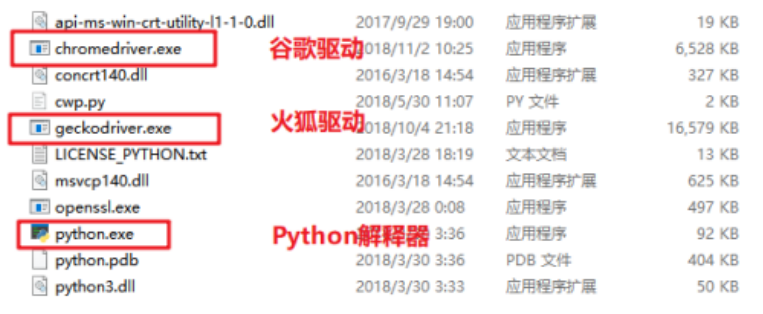
配置浏览器驱动:
将下载好的浏览器驱动解压,将解压出的exe文件放到Python的安装目录下,也就是和python.exe同目录即可。
1.3 使用Selenium
安装selenium模块,python借助这个模块驱动浏览器,使用如下命令行安装这个模块即可
pip install selenium
2 快速入门
# 打开百度首页 from selenium import webdriver driver = webdriver.chrome() url = 'https : / /www.baidu . com/ ' driver.get(url) #打开get就类似与在浏览器地址栏里面放入网址 driver.get(url) #退出浏览器 driver.quit()
加载全部内容