Java MapReduce框架 Java基础之MapReduce框架总结与扩展知识点
GaryLea 人气:1一、MapTask工作机制
MapTask就是Map阶段的job,它的数量由切片决定

二、MapTask工作流程:
1.Read阶段:读取文件,此时进行对文件数据进行切片(InputFormat进行切片),通过切片,从而确定MapTask的数量,切片中包含数据和key(偏移量)
2.Map阶段:这个阶段是针对数据进行map方法的计算操作,通过该方法,可以对切片中的key和value进行处理
3.Collect收集阶段:在用户编写map()函数中,当数据处理完成后,一般会调用OutputCollector.collect()输出结果。在该函数内部,它会将生成的key/value分区(调用Partitioner),并写入一个环形内存缓冲区中。
4.Spill阶段:即“溢写”,当环形缓冲区满后,MapReduce会将数据写到本地磁盘上,生成一个临时文件。需要注意的是,将数据写入本地磁盘之前,先要对数据进行一次本地排序,并在必要时对数据进行合并、压缩等操作。
5.Combine阶段:当所有数据处理完成后,MapTask对所有临时文件进行一次合并,以确保最终只会生成一个数据文件,这个阶段默认是没有的,一般需要我们自定义
6.当所有数据处理完后,MapTask会将所有临时文件合并成一个大文件,并保存到文件output/file.out中,同时生成相应的索引文件output/file.out.index。
7.在进行文件合并过程中,MapTask以分区为单位进行合并。对于某个分区,它将采用多轮递归合并的方式。每轮合并io.sort.factor(默认10)个文件,并将产生的文件重新加入待合并列表中,对文件排序后,重复以上过程,直到最终得到一个大文件。
8.让每个MapTask最终只生成一个数据文件,可避免同时打开大量文件和同时读取大量小文件产生的随机读取带来的开销
第四步溢写阶段详情:
- 步骤1:利用快速排序算法对缓存区内的数据进行排序,排序方式是,先按照分区编号Partition进行排序,然后按照key进行排序。这样,经过排序后,数据以分区为单位聚集在一起,且同一分区内所有数据按照key有序。
- 步骤2:按照分区编号由小到大依次将每个分区中的数据写入任务工作目录下的临时文件output/spillN.out(N表示当前溢写次数)中。如果用户设置了Combiner,则写入文件之前,对每个分区中的数据进行一次聚集操作。
- 步骤3:将分区数据的元信息写到内存索引数据结构SpillRecord中,其中每个分区的元信息包括在临时文件中的偏移量、压缩前数据大小和压缩后数据大小。如果当前内存索引大小超过1MB,则将内存索引写到文件output/spillN.out.index中。
三、ReduceTask工作机制
ReduceTask就是Reduce阶段的job,它的数量由Map阶段的分区进行决定
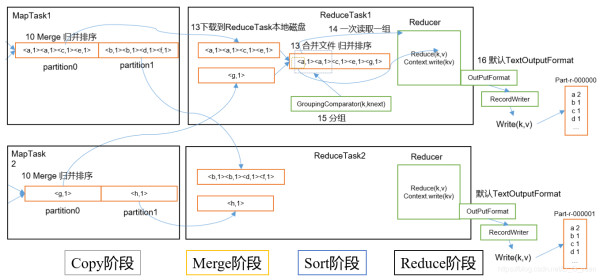
四、ReduceTask工作流程:
1.Copy阶段:ReduceTask从各个MapTask上远程拷贝一片数据,并针对某一片数据,如果其大小超过一定阈值,则写到磁盘上,否则直接放到内存中。
2.Merge阶段:在远程拷贝数据的同时,ReduceTask启动了两个后台线程对内存和磁盘上的文件进行合并,以防止内存使用过多或磁盘上文件过多。
3.Sort阶段:按照MapReduce语义,用户编写reduce()函数输入数据是按key进行聚集的一组数据。为了将key相同的数据聚在一起,Hadoop采用了基于排序的策略。由于各个MapTask已经实现对自己的处理结果进行了局部排序,因此,ReduceTask只需对所有数据进行一次归并排序即可。
4.Reduce阶段:reduce()函数将计算结果写到HDFS上
五、数据清洗(ETL)
我们在大数据开篇概述中说过,数据是低价值的,所以我们要从海量数据中获取到我们想要的数据,首先就需要对数据进行清洗,这个过程也称之为ETL
还记得上一章中的Join案例么,我们对pname字段的填充,也算数据清洗的一种,下面我通过一个简单的案例来演示一下数据清洗
数据清洗案例
需求:过滤一下log日志中字段个数小于11的日志(随便举个栗子而已)
测试数据:就拿我们这两天学习中HadoopNodeName产生的日志来当测试数据吧,我将log日志信息放到我的windows中,数据位置如下
/opt/module/hadoop-3.1.3/logs/hadoop-xxx-nodemanager-hadoop102.log
编写思路:
直接通过切片,然后判断长度即可,因为是举个栗子,没有那么复杂
真正的数据清洗会使用框架来做,这个我后面会为大家带来相关的知识
- ETLDriver
package com.company.etl;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class ETLDriver {
public static void main(String[] args) throws Exception {
Job job = Job.getInstance(new Configuration());
job.setJarByClass(ETLDriver.class);
job.setMapperClass(ETLMapper.class);
job.setNumReduceTasks(0);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job,new Path("D:\\io\\input8"));
FileOutputFormat.setOutputPath(job,new Path("D:\\io\\output88"));
job.waitForCompletion(true);
}
}
- ETLMapper
package com.company.etl;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Counter;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class ETLMapper extends Mapper<LongWritable, Text,Text, NullWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//清洗(过滤)
String line = value.toString();
String[] info = line.split(" ");
//判断
if (info.length > 11){
context.write(value,NullWritable.get());
}
}
}
六、计数器应用
- 顾名思义,计数器的作用就是用于计数的,在Hadoop中,它内部也有一个计数器,用于监控统计我们处理数据的数量
- 我们通常在MapReduce中通过上下文 context进行应用,例如在Mapper中,我通过step方法进行初始化计数器,然后在我们map方法中进行计数
七、计数器案例
在上面数据清洗的基础上进行计数器的使用,Driver没什么变化,只有Mapper
我们在Mapper的setup方法中,创建计数器的对象,然后在map方法中调用它即可
ETLMapper
package com.company.etl;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Counter;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class ETLMapper extends Mapper<LongWritable, Text,Text, NullWritable> {
private Counter sucess;
private Counter fail;
/*
创建计数器对象
*/
@Override
protected void setup(Context context) throws IOException, InterruptedException {
/*
getCounter(String groupName, String counterName);
第一个参数 :组名 随便写
第二个参数 :计数器名 随便写
*/
sucess = context.getCounter("ETL", "success");
fail = context.getCounter("ETL", "fail");
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//清洗(过滤)
String line = value.toString();
String[] info = line.split(" ");
//判断
if (info.length > 11){
context.write(value,NullWritable.get());
//统计
sucess.increment(1);
}else{
fail.increment(1);
}
}
}
八、MapReduce总结
好了,到这里,我们MapReduce就全部学习完毕了,接下来,我再把整个内容串一下,还是MapReduce的那个图
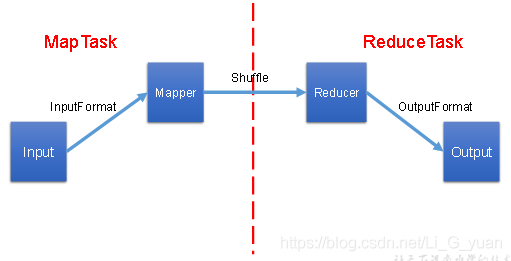
MapReduce的主要工作就是对数据进行运算、分析,它的工作流程如下:
1.我们会将HDFS中的数据通过InputFormat进行进行读取、切片,从而计算出MapTask的数量
2.每一个MapTask中都会有Mapper类,里面的map方法就是任务的具体实现,我们通过它,可以完成数据的key,value封装,然后通过分区进入shuffle中来完成每个MapTask中的数据分区排序
3.通过分区来决定ReduceTask的数量,每一个ReduceTask都有一个Reducer类,里面的reduce方法是ReduceTask的具体实现,它主要是完成最后的数据合并工作
4.当Reduce任务过重,我们可以通过Combiner合并,在Mapper阶段来进行局部的数据合并,减轻Reduce的任务量,当然,前提是Combiner所做的局部合并工作不会影响最终的结果
5.当Reducer的任务完成,会将最终的key,value写出,交给OutputFormat,用于数据的写出,通过OutputFormat来完成HDFS的写入操作
每一个MapTask和ReduceTask内部都是循环进行读取,并且它有三个方法:setup() map()/reduce() cleanup()
setup()方法是在MapTask/ReduceTask刚刚启动时进行调用,cleanup()是在任务完成后调用
加载全部内容
 爱之家商城
爱之家商城 氢松练
氢松练 Face甜美相机
Face甜美相机 花汇通
花汇通 走路宝正式版
走路宝正式版 天天运动有宝
天天运动有宝 深圳plus
深圳plus 热门免费小说
热门免费小说