Python PDF 基于Python快速处理PDF表格数据
其实还好啦 人气:2我们有下面一张PDF格式存储的表格,现在需要使用Python将它提取出来。
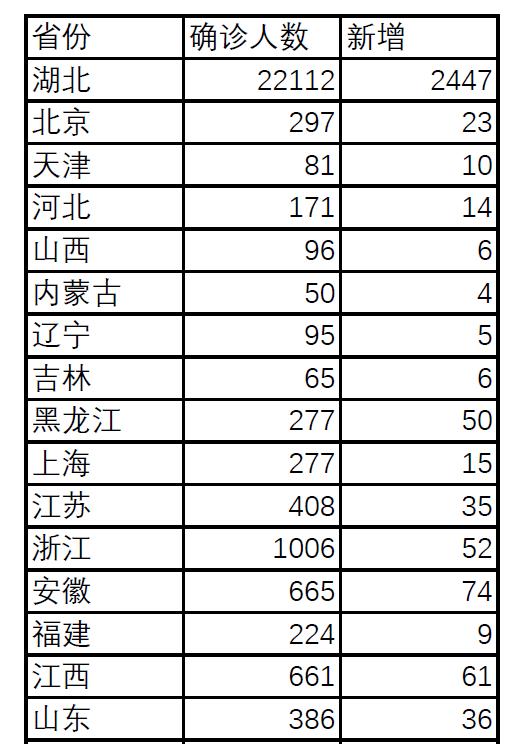
使用Python提取表格数据需要使用pdfplumber模块,打开CMD,安装代码如下:
pip install pdfplumber
安装完之后,将需要使用的模块导入
import pdfplumberimport pandas as pd
然后打开PDF文件
# 使用with语句打开pdf文件
with pdfplumber.open("D:\\python\\cai\\yq.pdf") as pdf:
# pages[0]表示取第1页
page = pdf.pages[0]
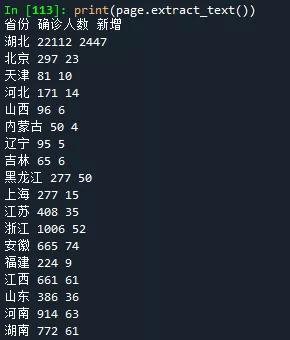
我们来打印输出下获取到的文本,这句语句只是帮我们验证下是否成功获取到PDF里的内容
print(page.extract_text())
执行的结果如下,看来是成功了
然后可以使用extract_table()函数获取表格,如果有多个表格,可以使用extract_tables()函数,就是多了个s
d1=page.extract_table()
执行代码后,将得到一个列表,还不是数据框

所以最后一步就是将列表转为数据框就可以了,代码如下:
df = pd.DataFrame(d1[1:], columns=d1[0])
执行代码后,将得到了df数据框

有几个注意事项要提醒下:
1.pdf表格中的数据,对于同一个数据或内容,不要有换行,如果换行,可能被识别为2个数据;
2.pdf中的表格一定要有边框,没有边框的话,否则使用extract_table()函数就无法获取表格数据,extract_text()还是可以获取文本信息的,不要问我是怎么知道的,说多了都是泪。
我们现在有一份PDF数据,里面有三页,每页都有一样数据结构但数据不同的数据表,现在需要使用Python将它批量提取出来。

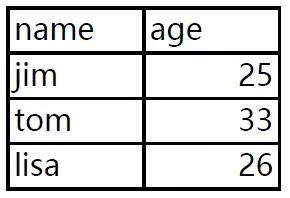
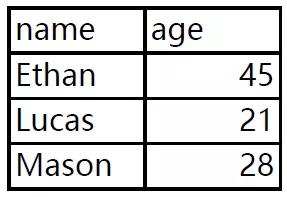
有了上回经验,我们就直接上代码:
import pdfplumber
import pandas as pd
# 创建一个空数据框
df = pd.DataFrame()
# 使用with语句打开pdf文件
with pdfplumber.open("D:\\python\\cai\\5.pdf") as pdf:
# 使用for循环遍历每个pages
for page in pdf.pages:
# 取出当前页表格,结果为列表
d=page.extract_table()
# 将列表转为数据框
df1 = pd.DataFrame(d[1:], columns=d[0])
#添加至df数据框中
df = df.append(df1)
执行代码后,将得到了df数据框
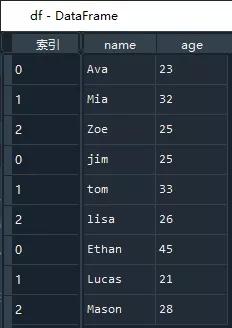
是不是so easy 呢?
加载全部内容