R语言循环读取excel保存RData R语言-怎样循环读取excel并保存为RData
t156xxxx4671 人气:0之前写过一个循环读取excel的代码,最近又有了新的需求:循环读取xlsx文件中的多个sheet,处理完之后循环输出到xlsx文件中的多个sheet中,总结一下。
1、循环读取csv文件并输出为RData格式
homedir <- "D:/Documents/tina/Database" #设置路径
setwd(homedir)
temp = list.files(pattern="*.csv")
for (i in 1:length(temp)) {
filename <- substr(temp[i], 1, nchar(temp[i])-4);
assign(filename, read.csv(temp[i], header = T));
save(list = filename, file = paste(filename, ".Rdata", sep = ""))
}
有了这段代码,要循环读取xlsx里面的多个sheet就简单多了,毕竟xlsx的文件名都是一致的,只是sheetIndex不一样:
2、循环读取xlsx文件中的多个sheet:
library(xlsx)
sheet.index <- c(1:12)
data.list <- list()
for(i in sheet.index){
filename <- paste0("month",i)
data.list[[i]] <- read.xlsx("E:/某某中心年收入.xls", encoding = "UTF-8", sheetIndex = i)
assign(filename, data.list[[i]])
}
下面这面这段代码是抄来的,还没来得及尝试能不能循环写入sheet了。
3、循环创建xlsx中的多个sheet
library(XLConnect)
wb <- loadWorkbook('data.xlsx', create = TRUE) # 创建excel工作簿
# 创建sheet
for (name in paste0('sheet', 1:3)) {
createSheet(wb, name)
}
# 分别向3个sheet写入数据
writeWorksheet(wb, data_frame_1, 'sheet1')
writeWorksheet(wb, data_frame_2, 'sheet2')
writeWorksheet(wb, data_frame_3, 'sheet3')
saveWorkbook(wb)
今天尝试了第3部分的代码,发现循环写入的功能无法实现,于是使用openxlsx包解决该问题。
4、创建xlsx,写入多个sheet
首先按照网上的教程安装了openxlsx,并进行了实验:
library(openxlsx)
wb <- createWorkbook()
addWorksheet(wb, "Sheet 1")
c1 <- createComment(comment = "this is comment")
writeComment(wb, 1, col = "B", row = 10, comment = c1)
s1 <- createStyle(fontSize = 12, fontColour = "red", textDecoration = c("BOLD"))
s2 <- createStyle(fontSize = 9, fontColour = "black")
c2 <- createComment(comment = c("This Part Bold red\n\n", "This part black"), style = c(s1, s2))
c2
writeComment(wb, 1, col = 6 , row = 3, comment = c2)
addWorksheet(wb, "Sheet 1")
saveWorkbook(wb, file = "E:/信和资料/项目/门店绩效/湖南益阳/writeCommentExample.xlsx", overwrite = TRUE)
但在最后保存时报错,因为是在windows环境下,保存时提示安装Rtools,windows系统下安装完成后,需要添加系统变量D:\Rtools\bin;D:\Rtools\gcc-4.6.3\bin,添加完成后,重启电脑,发现保存成功。
下面,需要循环将多个sheet写入xlsx文件中:
wb <- createWorkbook() addWorksheet(wb,"xsjshouru12") addWorksheet(wb, "xsjshouru18") addWorksheet(wb, "xsjshouru24") addWorksheet(wb, "xsjshouru36") writeData(wb,"xsjshouru12",xsjshouru12) writeData(wb,"xsjshouru18",xsjshouru18) writeData(wb,"xsjshouru24",xsjshouru24) writeData(wb,"xsjshouru36",xsjshouru36) #保存到本地文件 saveWorkbook(wb,file = "E:/信和资料/项目/门店绩效/湖南益阳/薪水借.xlsx", overwrite = TRUE)
读入数据:
files = list.files(pattern='*.Rdata') fload = lapply(files, function(x) get(load(x)))
合并多个数据框
edata4 <- Reduce(function(x,y) merge(x = x, y = y, by = c('lon','lat')),list(dtr01, dtr02, dtr03))
补充:R语言:批量循环读取一系列excel文件
例如有20个excel文件分别代表20个亚组的数据,文件名为亚组名P01-P20,每个文件中的变量个数和名称等都是相同的,可通过以下命令实现一次性读取20个excel,并生成一个新变量提示来自哪个亚组(同时展示如何读取每个excel第二列数据的前11个字符生成一个新变量id)。
例如P01数据如下:

首先
读取excel文件先要安装package: XLConnect:
install.packages(XLConnect) library(XLConnect)
其次
生成代表亚组名称的新变量和第二列前11个字符的新变量:
temp<-list.files(pattern="*.xls") //生成一个新变量temp代表文件路径中所有后缀为xls的文件的文件名 head(temp) a=readWorksheetFromFile(temp[1],sheet=1) //读取temp1号excel即P01,命名为数据库a a$plate=substr(as.character(temp[1]),1,3) //生成变量plate,数值为temp里的plate名称(字符1到3) a$id=substr(a[,2],1,11) //生成变量id, 值为第二列数据的前11个字符 ncol(a) //看看a有多少个变量,新生成的plate和id变量为最后两个,假设为第58和59个变量 write.table(a[,c(58,59)],file = "newfile.txt",row.names=F, na="",col.names=FALSE, sep=" ",append = T,quote=F) //生成txt文件newfile.txt为p01文件中的plate和id,展示如下
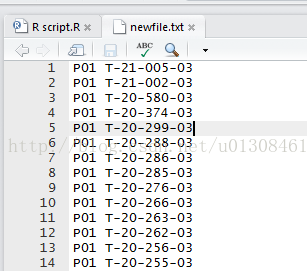
最后
对P02-20写一个for循环语句,导入进去即可
for (i in 2: length(temp)){
newfile=read.table("newfile.txt")
b=readWorksheetFromFile(temp[i],sheet=1)
b$row=substr(as.character(temp[i]),1,3)
b$extract=substr(b[,2],1,11)
write.table(b[,c(58,59)],file = "newfile.txt",row.names=F, na="",col.names=FALSE, sep=" ",append = T,quote=F)
}
命令翻译:对每一个i值,i从2到temp的最大值之间取值,生成一个文件newfile=之前P01的txt文件,下面四行是重复上面生成P01file的过程。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。如有错误或未考虑完全的地方,望不吝赐教。
加载全部内容
 爱之家商城
爱之家商城 氢松练
氢松练 Face甜美相机
Face甜美相机 花汇通
花汇通 走路宝正式版
走路宝正式版 天天运动有宝
天天运动有宝 深圳plus
深圳plus 热门免费小说
热门免费小说