你真的了解Innodb存储引擎?
上古伪神 人气:1前言
前几篇记录了如何查看SQL执行计划、数据库事务相关的知识点
除了这两个,数据库还有两个是非常重要的,必须要考的
就是存储引擎和索引
今天先记录以下InnoDB存储引擎相关的知识点
MySQL存储引擎
在MySQL存储引擎中,最为广知的存储引擎是InnoDB和MyISAM存储引擎
而这两个存储引擎的区别应该大家都清楚:
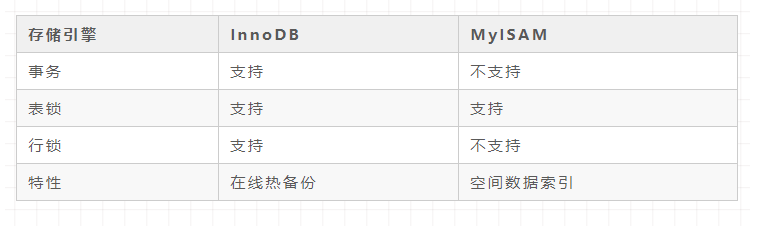
而MySQL目前默认的存储引擎就是InnoDB
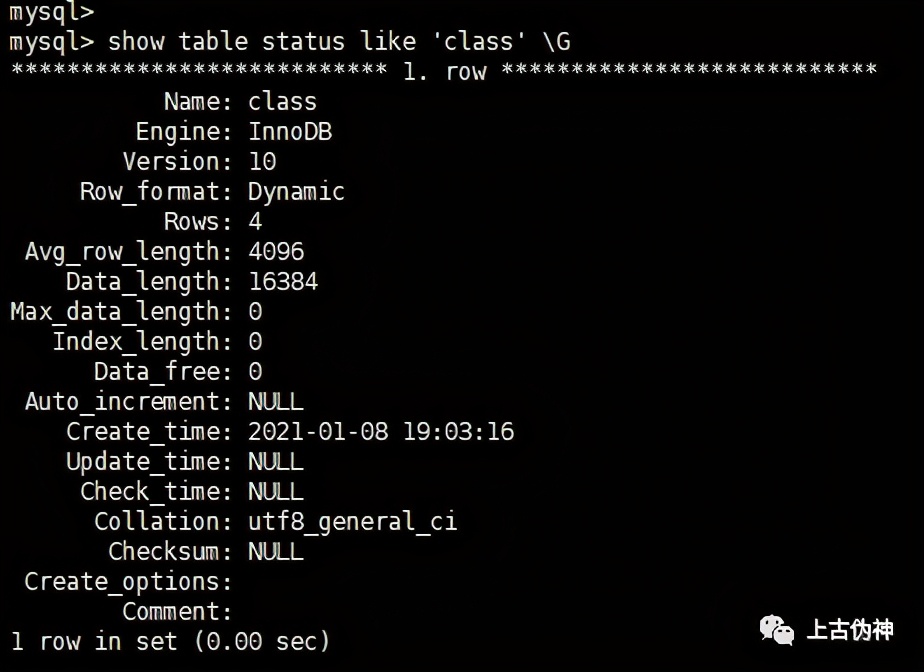
「如何查看表使用的是哪种存储引擎?」
show table status like 'table_name'\G
InnoDB
是MySQL的默认事务性存储引擎,最重要、使用最广泛。
用来处理大量的短期事务。
InnoDB的性能和自动崩溃恢复特性,使得它在非事务性存储的需求中也有广泛的应用。
采用MVVC来支持高并发,并实现了四个标准的隔离级别,默认隔离级别是RR(Repeatable Read可重复读),并通过间隙锁来防止幻读的出现。
InnoDB表是基于聚簇索引建立的,聚簇索引对主键查询由很高的性能,不过它的二级索引(非主键索引)必须包含主键列。
「具体架构图如下」
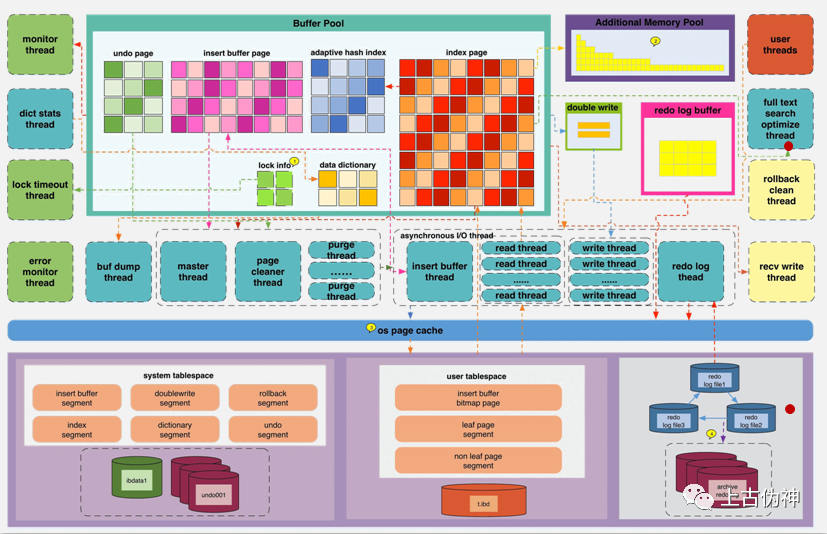
上半部分是实例层(计算层),位于内存中
下半部分是物理层,位于文件系统中
实例层
分为线程和内存,Innodb重要的线程有Master Thread,此线程是Innodb的主线程,负责调度其他各线程。
Master Thread 的优先级最高, 其内部包含几个循环:
主循环(loop)
后台循环(background loop)
刷新循环(flush loop)
暂停循环(suspend loop)。
Master Thread 会根据其内部运行的相关状态在各循环间进行切换
大部分操作在主循环(loop)中完成,其包括1s和10s两种操作:
「1s操作:」
日志缓冲刷新到磁盘
最多刷新100个新脏页到磁盘
执行并改变缓冲的操作
若当前没有用户活动,可能切换到后台循环等
「10s操作:」
最多刷新100个新脏页到磁盘
合并至多5个被改变的缓冲
日志缓冲刷新到磁盘
删除无用的Undo页
刷新 100 个或者 10 个脏页到磁盘(总是)产生一个检查点(总是)等。
「buf dump thread:」
将缓存池中内容dump到磁盘中,实现MySQL热启动
「page_cleaner_thread:」
将缓存池的脏页刷新到磁盘
「purge thread:」
将不再使用的Undo页回收
「read_thread:」
处理读请求,并负责将数据页从磁盘中读取出来
「write_thread:」
负责将数据页从缓冲区写入磁盘,page_cleaner 线程发起刷脏页操作后就开始工作了。
「redo_log_thread:」
负责将日志缓冲区中的内容刷新到Redo log文件中
「insert_buffer_thread:」
负责把 Insert Buffer 中的内容刷新到磁盘
缓存结构

缓冲池中缓存的数据页类型有:
- 索引页
- 数据页
- undo页
- 插入缓冲(insert buffer)
- 自适应哈希索引(adaptive hash index)
- InnoDB存储的锁信息(lock info)
- 数据字典信息(data dictionary)

Redo log 日志缓存
InnoDB存储引擎会首先将重做日志信息先放入重做日志缓冲中,然后再按照一定频率将其刷新到重做日志文件
「缓冲页管理算法:」
页:磁盘管理的最小单位,默认16K。类型有:数据页,undo页,系统页
一般缓冲的管理算法就是LRU(Least recently used)。
一般是把刚如缓冲页的放在LRU的头部,作为最近访问的元素,最后的一个元素被淘汰。
(1)页已经在缓冲池里,那就只做“移至”LRU头部的动作,而没有页被淘汰;
(2)页不在缓冲池里,除了做“放入”LRU头部的动作,还要做“淘汰”LRU尾部页的动作;
比如:有一个LRU链
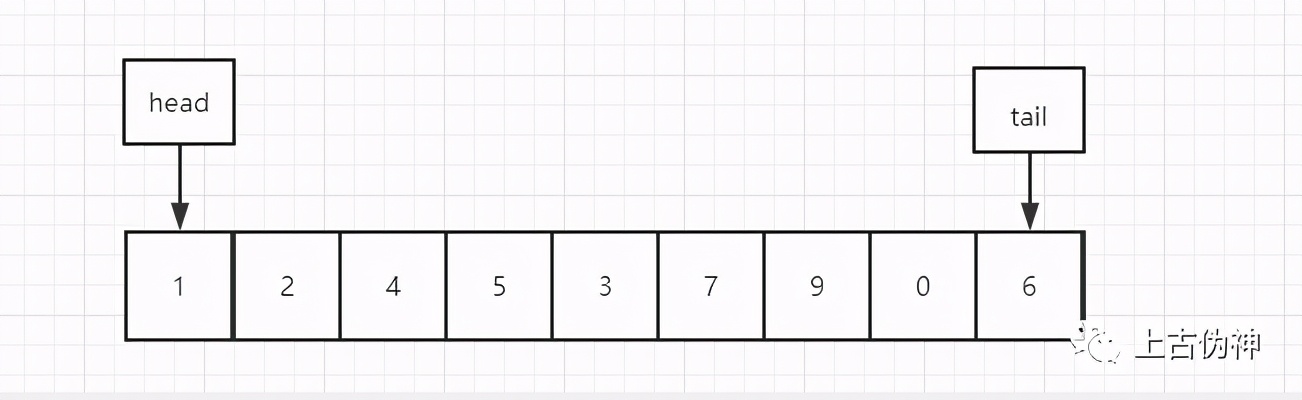
「第一种情况:」
查找元素为0的,那么链表就变成下面这样子

「第二种情况:」
查找元素为10的,但10不在链中,所以将10添加到head,而tail节点6去除

MySQL在此基础上进行了改造,原因是:
(1)预读失效:
「预读:」
磁盘读写,并不是按需读取,而是按页读取,一次至少读一页数据(一般是16K),如果未来要读取的数据就在页中,就能够省去后续的磁盘IO,提高效率。
「预读失效:」
预读(Read-Ahead)提前把页放入了缓冲池,但最终MySQL并没有从页中读取数据,称为预读失效。
「如何优化?」
(1)让预读失效的页,停留在缓冲池LRU里的时间尽可能短;
(2)让真正被读取的页,才挪到缓冲池LRU的头部;
所以MySQL将LRU分成两部分,分别是:
- 新生代
- 老生代
新老生代首位相连。
新页加入缓冲池时,只加入老生代的头部,
「如果数据真正被读取(预读成功),才会加入到新生代的头部」
「如果数据没有被读取,则会比新生代里的“热数据页”更早被淘汰出缓冲池」
新生代跟老生代的比例是 5 : 3
例如:绿色的是新生代,黄色是老生代
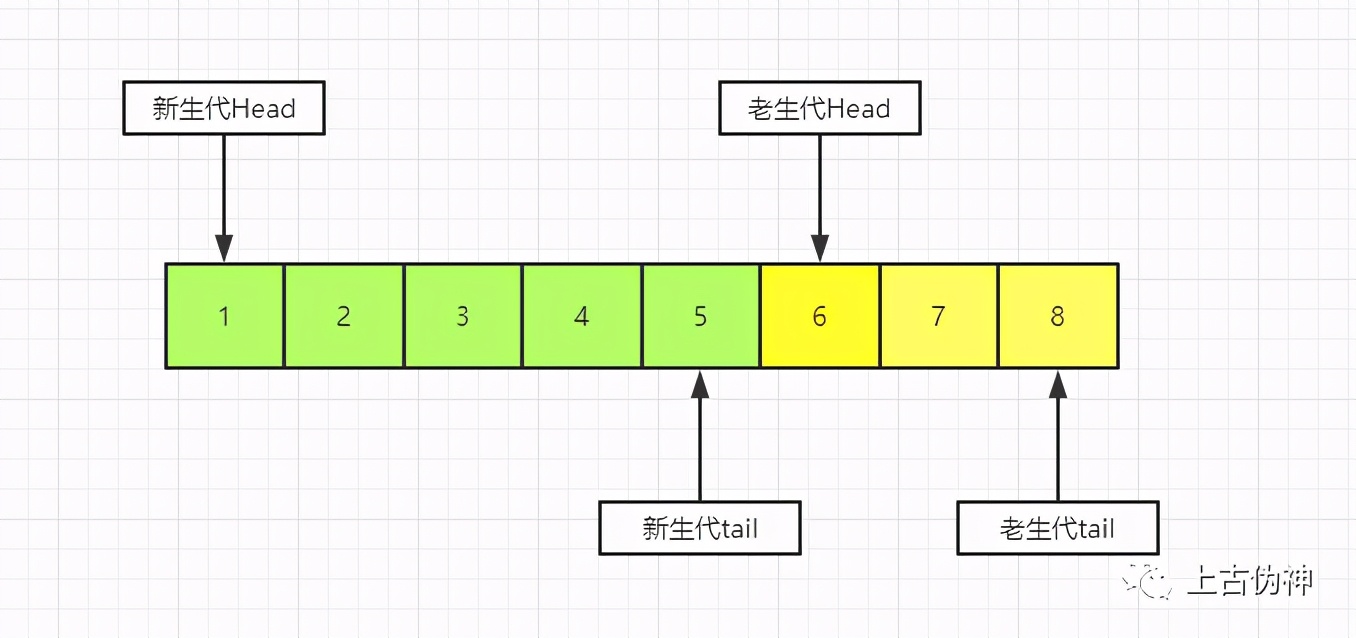
如果插入一个9的页,就是如下图:
老年代最后一个被淘汰
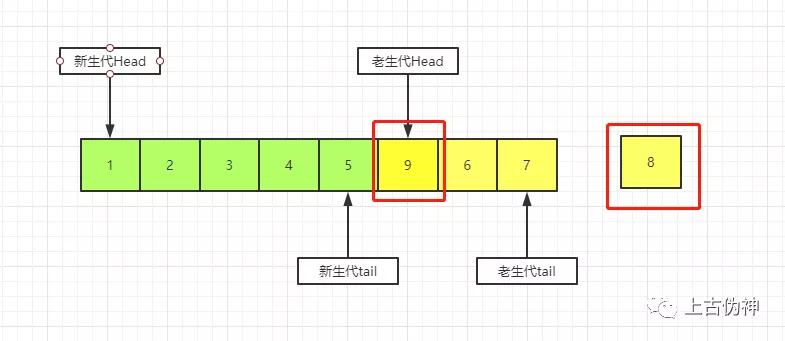
如果此时9被读取,那么就变成如下:
9称为新生代head节点,而原先新生代的tail节点5就变成老年代的head节点
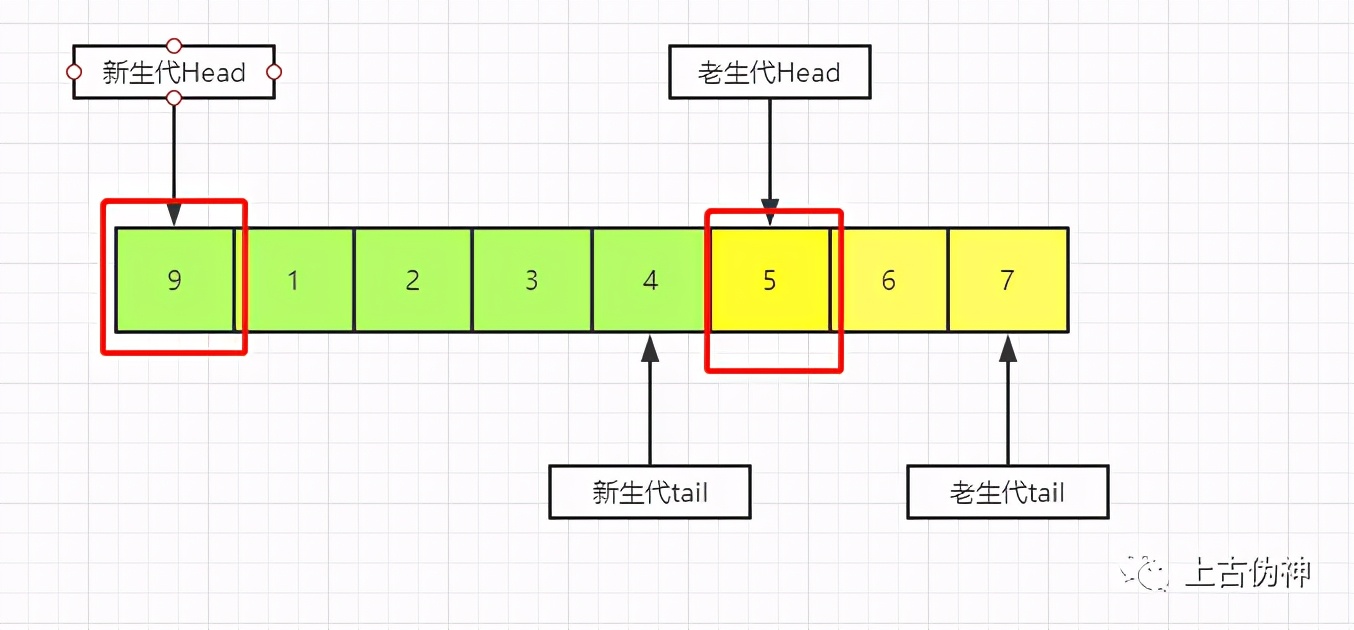
(2)缓冲池污染
当一个SQL查询要扫描大量数据,导致把缓冲池中所有页全部替换,导致大量热数据被换出去,这就是缓冲池污染
MySQL在老生代中添加了停留时间窗口
如果数据被读取了并且在老身代中停留时间超过这个窗口,那么才会被加入新生代头部
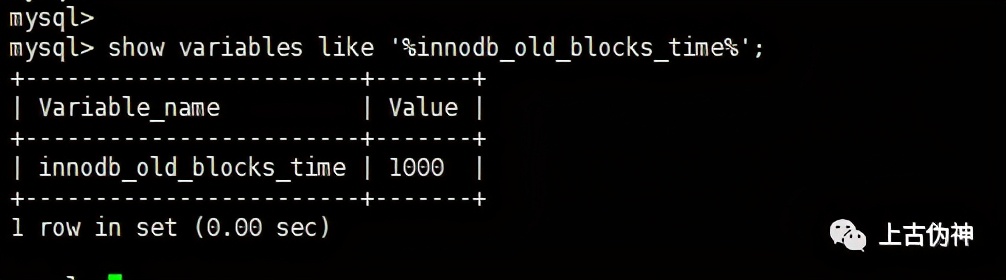
「如何查看这个停留时间:」
参数innodb_old_blocks_time
「缓冲池相关参数:」
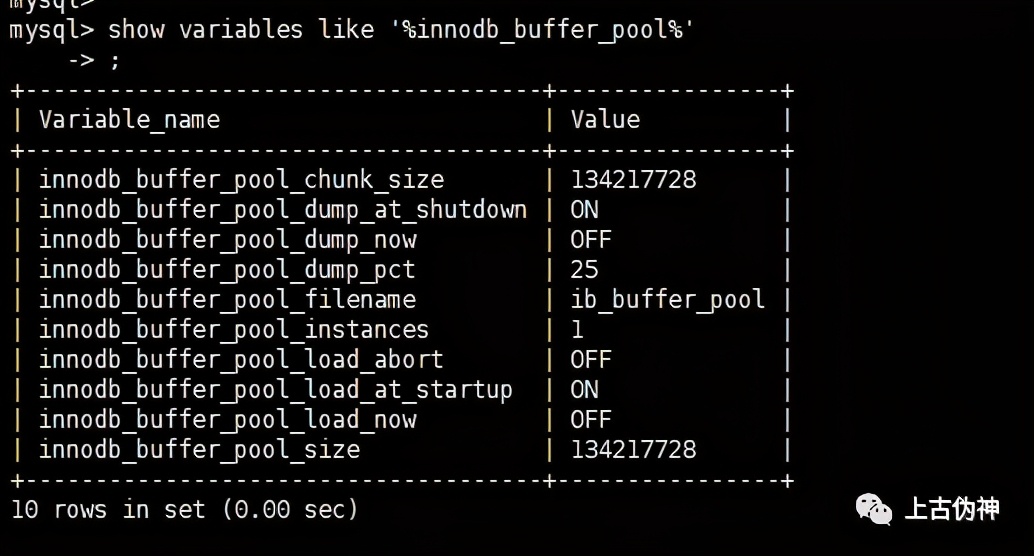
物理层
物理层在逻辑上分为
- 系统表空间
- 用户表空间
- Redo日志。
系统表空间里有 ibdata 文件和一些 Undo,ibdata 文件里有 insert buffer 段、double write段、回滚段、索引段、数据字典段和 Undo 信息段。
用户表空间是指以 .ibd 为后缀的文件,文件中包含 insert buffer 的 bitmap 页、叶子页(这里存储真正的用户数据)、非叶子页。InnoDB 表是索引组织表,采用 B+ 树组织存储,数据都存储在叶子节点中,分支节点(即非叶子页)存储索引分支查找的数据值。
Redo 日志中包括多个 Redo 文件,这些文件循环使用,当达到一定存储阈值(0.75)时会触发checkpoint 刷脏页操作,同时也会在 MySQL 实例异常宕机后重启,InnoDB 表数据自动还原恢复过程中使用。

用户读取或者写入的最新数据都存储在 Buffer Pool 中
如果 Buffer Pool 中没有找到则会读取物理文件进行查找,之后存储到 Buffer Pool 中并返回给 MySQL Server。Buffer Pool 采用LRU 机制。
Buffer Pool 决定了一个 SQL 执行的速度快慢,如果查询结果页都在内存中则返回结果速度很快,否则会产生物理读(磁盘读),返回结果时间变长,性能远不如存储在内存中。
「Redo 和 Undo」
Redo log 是一个循环复用的文件集,负责记录 InnoDB 中所有对 Buffer Pool的物理修改日志,当 Redo log文件空间中,检查点位置的 LSN 和最新写入的 LSN 差值(checkpoint_age)达到 Redo log 文件总空间的 75% 后,InnoDB 会进行异步刷新操作,直到降至 75% 以下,并释放 Redo log 的空间;当 checkpoint_age 达到文件总量大小的 90% 后,会触发同步刷新,此时 InnoDB 处于挂起状态无法操作。
Redo记录变更后的数据。
Undo记录事务数据变更前的值,用于回滚和其他事务多版本读。
「ARIES 三原则」
ARIES 三原则,是指 Write Ahead Logging(WAL)。
先写日志后写磁盘,日志成功写入后事务就不会丢失,后续由 checkpoint 机制来保证磁盘物理文件与 Redo 日志达到一致性;
利用 Redo 记录变更后的数据,即 Redo 记录事务数据变更后的值;
利用 Undo 记录变更前的数据,即 Undo 记录事务数据变更前的值,用于回滚和其他事务多版本读。
===============================
我是Liusy,一个喜欢健身的程序员。
获取更多干货以及最新消息,请关注_公_众_号:上古伪神
如果对您有帮助,点个关注、转发就是对我最大的支持!!!谢谢
加载全部内容