MySQL InnoDB中的锁机制深入讲解
人气:0写在前面
数据库本质上是一种共享资源,因此在最大程度提供并发访问性能的同时,仍需要确保每个用户能以一致的方式读取和修改数据。锁机制(Locking)就是解决这类问题的最好武器。
首先新建表 test,其中 id 为主键,name 为辅助索引,address 为唯一索引。
CREATE TABLE `test` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` int(11) NOT NULL, `address` int(11) NOT NULL, PRIMARY KEY (`id`), UNIQUE KEY `idex_unique` (`address`), KEY `idx_index` (`name`) ) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8mb4;
INSERT 方法中的行锁

可见,如果两个事务先后对主键相同的行记录执行 INSERT 操作,因为事务 A 先拿到了行锁,事务 B 只能等待直到事务 A 提交后行锁被释放。同理,如果针对唯一索引字段 address 进行插入操作,也需要获取行锁,图同主键插入过程类似,不再重复。
但是,如果两个事务都针对辅助索引字段 name 进行插入,不需要等待获取锁,因为辅助索引字段即使值相同,在数据库中也是操作不同的记录行,不会冲突。
Update 方法与 Insert 方法结果类似。
SELECT FOR UPDATE 下的表锁与行锁
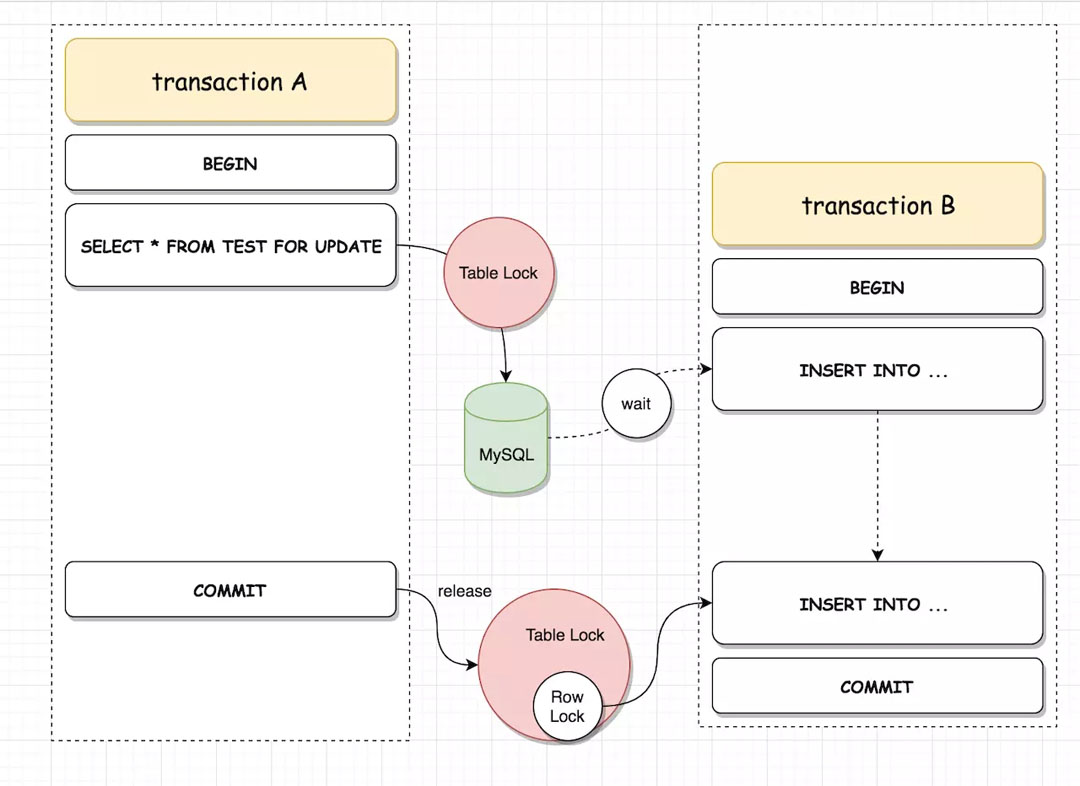
事务 A SELECT FOR UPDATE 语句会拿到表 test 的 Table Lock,此时事务 B 去执行插入操作会阻塞,直到事务 A 提交释放表锁后,事务 B 才能获取对应的行锁执行插入操作。
但是如果事务 A 的 SELECT FOR UPDATE 语句紧跟 WHERE id = 1 的话,那么这条语句只会获取行锁,不会是表锁,此时不阻塞事务 B 对于其他主键的修改操作
辅助索引下的间隙锁
先看下 test 表下的数据情况:
mysql> select * from test; +----+------+---------+ | id | name | address | +----+------+---------+ | 3 | 1 | 3 | | 6 | 1 | 2 | | 7 | 2 | 4 | | 8 | 10 | 5 | +----+------+---------+ 4 rows in set (0.00 sec)
间隙锁可以说是行锁的一种,不同的是它锁住的是一个范围内的记录,作用是避免幻读,即区间数据条目的突然增减。解决办法主要是:
- 防止间隙内有新数据被插入,因此叫间隙锁
- 防止已存在的数据,在更新操作后成为间隙内的数据(例如更新 id = 7 的 name 字段为 1,那么 name = 1 的条数就从 2 变为 3)
InnoDB 自动使用间隙锁的条件为:
- Repeatable Read 隔离级别,这是 MySQL 的默认工作级别
- 检索条件必须有索引(没有索引的话会走全表扫描,那样会锁定整张表所有的记录)
当 InnoDB 扫描索引记录的时候,会首先对选中的索引行记录加上行锁,再对索引记录两边的间隙(向左扫描扫到第一个比给定参数小的值, 向右扫描扫描到第一个比给定参数大的值, 以此构建一个区间)加上间隙锁。如果一个间隙被事务 A 加了锁,事务 B 是不能在这个间隙插入记录的。
我们这里所说的 “间隙锁” 其实不是 GAP LOCK,而是 RECORD LOCK + GAP LOCK,InnoDB 中称之为 NEXT_KEY LOCK
下面看个例子,我们建表时指定 name 列为辅助索引,目前这列的取值有 [1,2,10]。间隙范围有 (-∞, 1]、[1,1]、[1,2]、[2,10]、[10, +∞)
Round 1:
- 事务 A SELECT ... WHERE name = 1 FOR UPDATE;
- 对 (-∞, 2) 增加间隙锁
- 事务 B INSERT ... name = 1 阻塞
- 事务 B INSERT ... name = -100 阻塞
- 事务 B INSERT ... name = 2 成功
- 事务 B INSERT ... name = 3 成功
Round 2:
- 事务 A SELECT ... WHERE name = 2 FOR UPDATE;
- 对 [1, 10) 增加间隙锁
- 事务 B INSERT ... name = 1 阻塞
- 事务 B INSERT ... name = 9 阻塞
- 事务 B INSERT ... name = 10 成功
- 事务 B INSERT ... name = 0 成功
Round 3:
- 事务 A SELECT ... WHERE name <= 2 FOR UPDATE;
- 对 (-∞, +∞) 增加间隙锁
- 事务 B INSERT ... name = 3 阻塞
- 事务 B INSERT ... name = 300 阻塞
- 事务 B INSERT ... name = -300 阻塞
InnoDB 锁机制总结
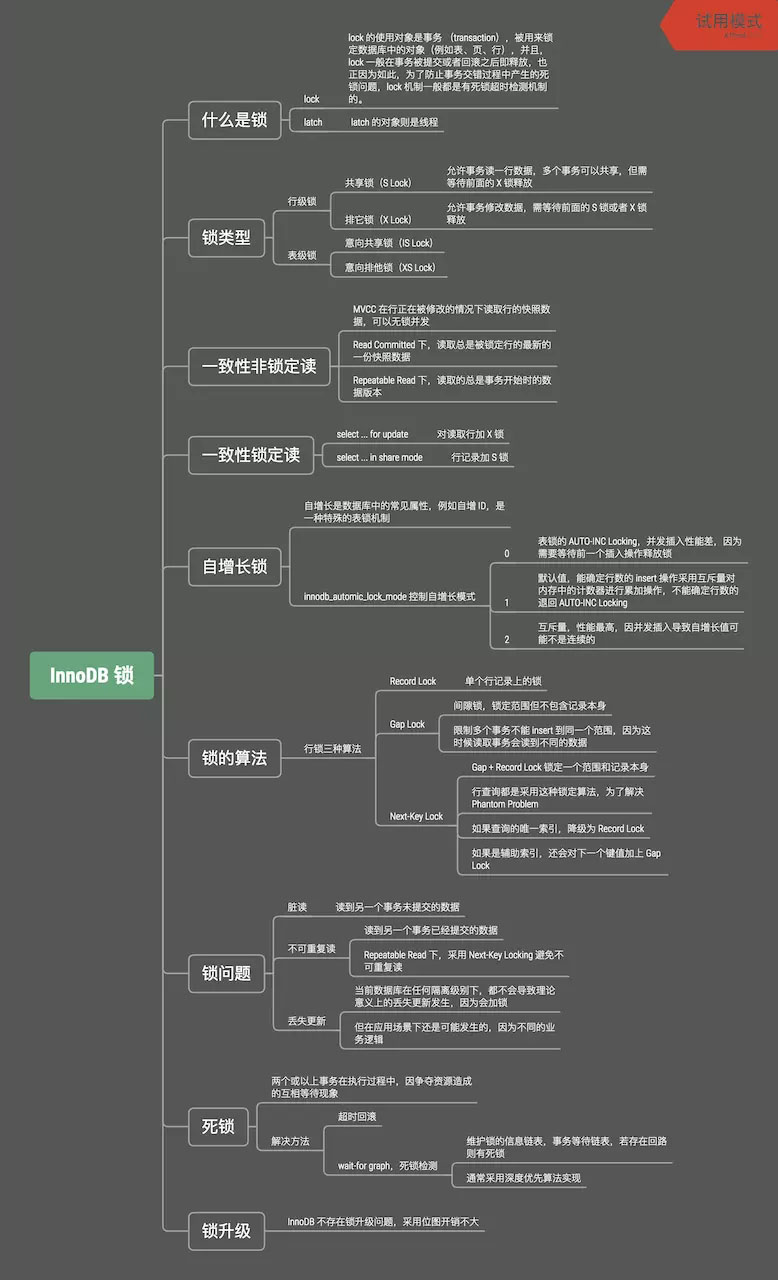
参考资料
- 《MySQL 技术内幕 InnoDB 存储引擎》第二版 姜承尧著
- About MySQL InnoDB's Lock
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对的支持。
您可能感兴趣的文章:
加载全部内容