Java多线程下解决资源竞争的7种方法详解
人气:1前言
一般情况下,只要涉及到多线程编程,程序的复杂性就会显著上升,性能显著下降,BUG出现的概率大大提升。
多线程编程本意是将一段程序并行运行,提升数据处理能力,但是由于大部分情况下都涉及到共有资源的竞争,所以修改资源
对象时必须加锁处理。但是锁的实现有很多种方法,下面就来一起了解一下在C#语言中几种锁的实现与其性能表现。
一、c#下的几种锁的运用方式
1、临界区,通过对多线程的串行化来访问公共资源或一段代码,速度快,适合控制数据访问。
private static object obj = new object();
private static int lockInt;
private static void LockIntAdd()
{
for (var i = 0; i < runTimes; i++)
{
lock (obj)
{
lockInt++;
}
}
}
你没看错,c#中的lock语法就是临界区(Monitor)的一个语法糖,这大概是90%以上的.net程序员首先想到的锁,不过大部分人都只是知道
有这么个语法,不知道其实是以临界区的方式处理资源竞争。
2、互斥量,为协调共同对一个共享资源的单独访问而设计的。
c#中有一个Mutex类,就在System.Threading命名空间下,Mutex其实就是互斥量,互斥量不单单能处理多线程之间的资源竞争,还能处理
进程之间的资源竞争,功能是比较强大的,但是开销也很大,性能比较低。
private static Mutex mutex = new Mutex();
private static int mutexInt;
private static void MutexIntAdd()
{
for (var i = 0; i < runTimes; i++)
{
mutex.WaitOne();
mutexInt++;
mutex.ReleaseMutex();
}
}
3、信号量,为控制一个具有有限数量用户资源而设计。
private static Semaphore sema = new Semaphore(1, 1);
private static int semaphoreInt;
private static void SemaphoreIntAdd()
{
for (var i = 0; i < runTimes; i++)
{
sema.WaitOne();
semaphoreInt++;
sema.Release();
}
}
4、事 件:用来通知线程有一些事件已发生,从而启动后继任务的开始。
public static AutoResetEvent autoResetEvent = new AutoResetEvent(true);
private static int autoResetEventInt;
private static void AutoResetEventIntAdd()
{
for (var i = 0; i < runTimes; i++)
{
if (autoResetEvent.WaitOne())
{
autoResetEventInt++;
autoResetEvent.Set();
}
}
}
5、读写锁,这种锁允许在有其他程序正在写的情况下读取资源,所以如果资源允许脏读,用这个比较合适
private static ReaderWriterLockSlim LockSlim = new ReaderWriterLockSlim();
private static int lockSlimInt;
private static void LockSlimIntAdd()
{
for (var i = 0; i < runTimes; i++)
{
LockSlim.EnterWriteLock();
lockSlimInt++;
LockSlim.ExitWriteLock();
}
}
6、原子锁,通过原子操作Interlocked.CompareExchange实现“无锁”竞争
private static int isLock;
private static int ceInt;
private static void CEIntAdd()
{
//long tmp = 0;
for (var i = 0; i < runTimes; i++)
{
while (Interlocked.CompareExchange(ref isLock, 1, 0) == 1) { Thread.Sleep(1); }
ceInt++;
Interlocked.Exchange(ref isLock, 0);
}
}
7、原子性操作,这是一种特例,野外原子性操作本身天生线程安全,所以无需加锁
private static int atomicInt;
private static void AtomicIntAdd()
{
for (var i = 0; i < runTimes; i++)
{
Interlocked.Increment(ref atomicInt);
}
}
8、不加锁,如果不加锁,那多线程下运行结果肯定是错的,这里贴上来比较一下性能
private static int noLockInt;
private static void NoLockIntAdd()
{
for (var i = 0; i < runTimes; i++)
{
noLockInt++;
}
}
二、性能测试
1、测试代码,执行1000,10000,100000,1000000次
private static void Run()
{
var stopwatch = new Stopwatch();
var taskList = new Task[loopTimes];
// 多线程
Console.WriteLine();
Console.WriteLine($" 线程数:{loopTimes}");
Console.WriteLine($" 执行次数:{runTimes}");
Console.WriteLine($" 校验值应等于:{runTimes * loopTimes}");
// AtomicIntAdd
stopwatch.Restart();
for (var i = 0; i < loopTimes; i++)
{
taskList[i] = Task.Factory.StartNew(() => { AtomicIntAdd(); });
}
Task.WaitAll(taskList);
Console.WriteLine($"{GetFormat("AtomicIntAdd")}, 总耗时:{stopwatch.ElapsedMilliseconds}毫秒, 校验值:{atomicInt}");
// CEIntAdd
taskList = new Task[loopTimes];
stopwatch.Restart();
for (var i = 0; i < loopTimes; i++)
{
taskList[i] = Task.Factory.StartNew(() => { CEIntAdd(); });
}
Task.WaitAll(taskList);
Console.WriteLine($"{GetFormat("CEIntAdd")}, 总耗时:{stopwatch.ElapsedMilliseconds}毫秒, 校验值:{ceInt}");
// LockIntAdd
taskList = new Task[loopTimes];
stopwatch.Restart();
for (var i = 0; i < loopTimes; i++)
{
taskList[i] = Task.Factory.StartNew(() => { LockIntAdd(); });
}
Task.WaitAll(taskList);
Console.WriteLine($"{GetFormat("LockIntAdd")}, 总耗时:{stopwatch.ElapsedMilliseconds}毫秒, 校验值:{lockInt}");
// MutexIntAdd
taskList = new Task[loopTimes];
stopwatch.Restart();
for (var i = 0; i < loopTimes; i++)
{
taskList[i] = Task.Factory.StartNew(() => { MutexIntAdd(); });
}
Task.WaitAll(taskList);
Console.WriteLine($"{GetFormat("MutexIntAdd")}, 总耗时:{stopwatch.ElapsedMilliseconds}毫秒, 校验值:{mutexInt}");
// LockSlimIntAdd
taskList = new Task[loopTimes];
stopwatch.Restart();
for (var i = 0; i < loopTimes; i++)
{
taskList[i] = Task.Factory.StartNew(() => { LockSlimIntAdd(); });
}
Task.WaitAll(taskList);
Console.WriteLine($"{GetFormat("LockSlimIntAdd")}, 总耗时:{stopwatch.ElapsedMilliseconds}毫秒, 校验值:{lockSlimInt}");
// SemaphoreIntAdd
taskList = new Task[loopTimes];
stopwatch.Restart();
for (var i = 0; i < loopTimes; i++)
{
taskList[i] = Task.Factory.StartNew(() => { SemaphoreIntAdd(); });
}
Task.WaitAll(taskList);
Console.WriteLine($"{GetFormat("SemaphoreIntAdd")}, 总耗时:{stopwatch.ElapsedMilliseconds}毫秒, 校验值:{semaphoreInt}");
// AutoResetEventIntAdd
taskList = new Task[loopTimes];
stopwatch.Restart();
for (var i = 0; i < loopTimes; i++)
{
taskList[i] = Task.Factory.StartNew(() => { AutoResetEventIntAdd(); });
}
Task.WaitAll(taskList);
Console.WriteLine($"{GetFormat("AutoResetEventIntAdd")}, 总耗时:{stopwatch.ElapsedMilliseconds}毫秒, 校验值:{autoResetEventInt}");
// NoLockIntAdd
taskList = new Task[loopTimes];
stopwatch.Restart();
for (var i = 0; i < loopTimes; i++)
{
taskList[i] = Task.Factory.StartNew(() => { NoLockIntAdd(); });
}
Task.WaitAll(taskList);
Console.WriteLine($"{GetFormat("NoLockIntAdd")}, 总耗时:{stopwatch.ElapsedMilliseconds}毫秒, 校验值:{noLockInt}");
Console.WriteLine();
}
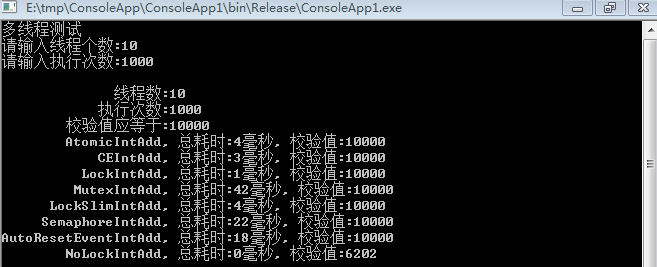
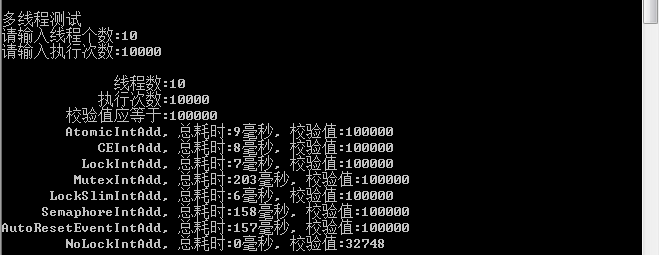
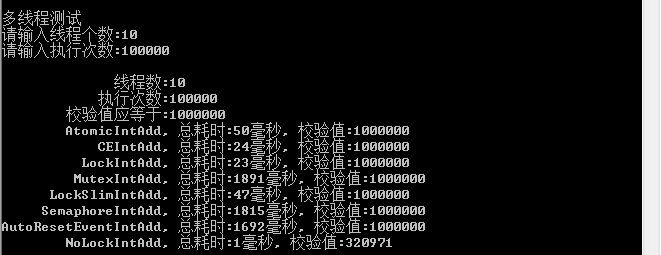
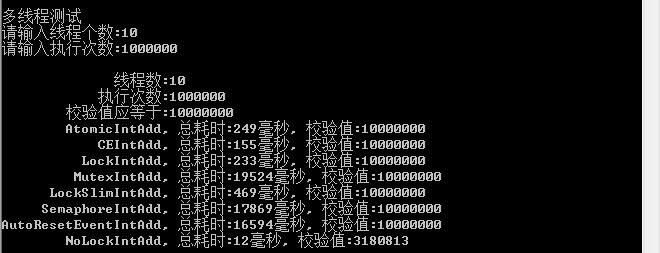
2、线程:10
3、线程:50
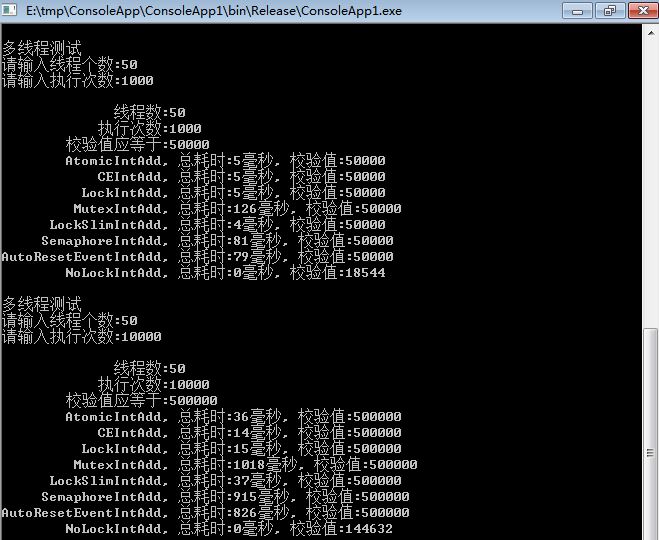

三、总结
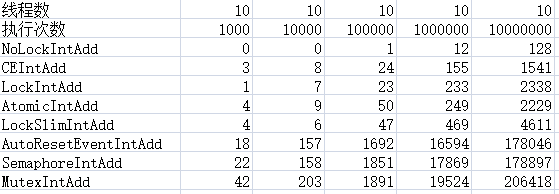
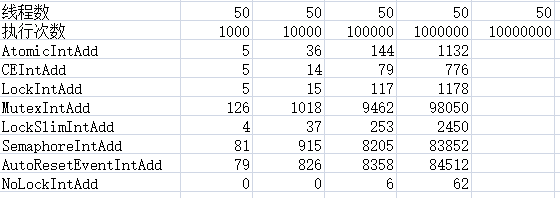
1)在各种测试中,不加锁肯定是最快的,所以尽量避免资源竞争导致加锁运行
2)在多线程中Interlocked.CompareExchange始终表现出优越的性能,排在第二位
3)第三位lock,临界区也表现出很好的性能,所以在别人说lock性能低的时候请反驳他
4)第四位是原子性变量(Atomic)操作,不过目前只支持变量的自增自减,适用性不强
5)第五位读写锁(ReaderWriterLockSlim)表现也还可以,并且支持无所读,实用性还是比较好的
6)剩下的信号量、事件、互斥量,这三种性能最差,当然他们有各自的适用范围,只是在处理资源竞争这方面表现不好
您可能感兴趣的文章:
加载全部内容