用Python爬取QQ音乐评论并制成词云图的实例
人气:0环境:Ubuntu16.4 python版本:3.6.4 库:wordcloud
这次我们要讲的是爬取QQ音乐的评论并制成云词图,我们这里拿周杰伦的等你下课来举例。
第一步:获取评论
我们先打开QQ音乐,搜索周杰伦的《等你下课》,直接拉到底部,发现有5000多页的评论。

这时候我们要研究的就是怎样获取每页的评论,这时候我们可以先按下F12,选择NetWork,我们可以先点击小红点清空数据,然后再点击一次,开始监控,然后点击下一页,看每次获取评论的时候访问获取的是哪几条数据。最后我们就能看到下图的样子,我们发现,第一条数据就是我们所要找的内容,点击第一条数据,打开它的response拉到最下面,发现他的最后一条评论rootcommentcontent跟我们网页中最后一条评论是一致的,那这时候已经成功了一般了,我们接下来只需要研究这条数据获取的规律就可以获取到所有的评论了。
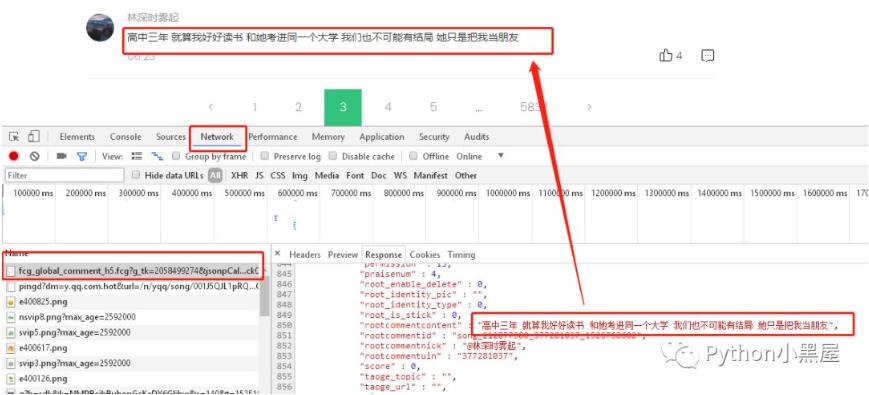
我们先查看这条数据的Headers分析下Request URL,通过点开不同的页码进行比较,发现每次发出的情况网址大部分内容是相同,不同的地方有两个,就是pagenum跟JsonCallBack,pagenum从英文上很明显能看出来就是页码,JsonCallBack又是啥呢?
https://c.y.qq.com/base/fcgi-bin/fcg_global_comment_h5.fcg?g_tk=2058499274&jsonpCallback=jsoncallback7494258674829413&loginUin=2230661779&hostUin=0&format=jsonp&inCharset=utf8&outCharset=GB2312¬ice=0&platform=yqq&needNewCode=0&cid=205360772&reqtype=2&biztype=1&topid=212877900&cmd=8&needmusiccrit=0&pagenum=4&pagesize=25&lasthotcommentid=song_212877900_23831021_1526748144&callback=jsoncallback7494258674829413&domain=qq.com&ct=24&cv=101010

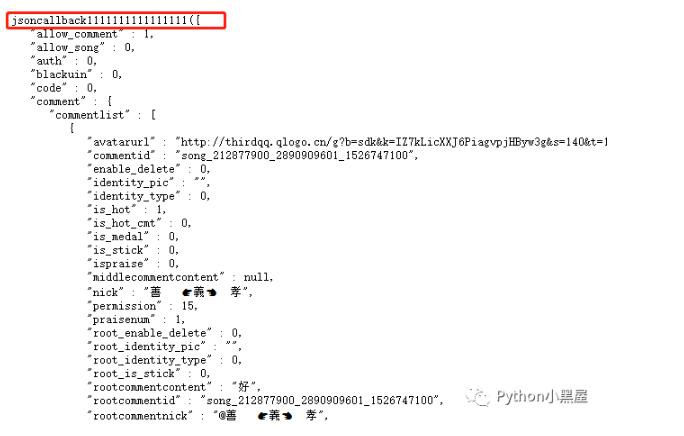
我们不妨将网址直接放在地址栏打开看看是怎样。我们可以发现是直接返回一个不正规的json格式,为什么说是不正规呢?因为他在开头多了个
jsoncallback7494258674829413
这个就是我们上面那个不知道怎么来的参数,我们尝试在把这个数据改一下后再打开网址,结果发现,获取的json内容是没有变化,唯一变的是开头jsoncallback1111111111
变成了我们输入的那个数值,所以我们可以猜测这是一个随机数,无论你输入什么,都不会影响我们要获取的内容。那这样就好办多了。

我们就直接放代码获取:
import requests
import json
def get_comment():
for i in range(1,7000):
# 打印页码
print(i)
# headers头部
headers = {'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:59.0) Gecko/20100101 Firefox/59.0',
'Referer': "https://y.qq.com/n/yqq/song/0031TAKo0095np.html"}
# 请求的url
url = 'https://c.y.qq.com/base/fcgi-bin/fcg_global_comment_h5.fcg?g_tk=2058499274&jsonpCallback=jsoncallback06927647062927766&loginUin=2230661779&hostUin=0&format=jsonp&inCharset=utf8&outCharset=GB2312¬ice=0&platform=yqq&needNewCode=0&cid=205360772&reqtype=2&biztype=1&topid=212877900&cmd=8&needmusiccrit=0&pagenum=%s&pagesize=25&lasthotcommentid=song_212877900_3035803620_1526783365&callback=jsoncallback06927647062927766&domain=qq.com&ct=24&cv=101010' %i
# 打印当前访问的url地址
print (url)
# 将请求得到的页面赋值为req
req = requests.get(url,headers=headers,verify=False)
# 对获取到的内容进行utf-8编码
html = str(req.content,'UTF-8')
# 对非正规的json进行处理,去掉头部跟尾部多余的部分
html= html.strip("jsoncallback06927647062927766(")
html = html.replace(")","")
# 去掉两边的空格
html = html.strip()
# 将处理后的json转为python的json
data = json.loads(html)
# 获取json中评论的部分
list = data['comment']['commentlist']
# 每次都重新定义一个列表来存储每一页的评论
content = []
# 遍历当前页的评论并通过调用write()函数来保存
for i in list:
# 偶尔也会有一页的评论获取不到,这时候如果报错了可以直接忽略那一页,继续运行
try:
content.append(i['rootcommentcontent'].replace("[em]","").replace("[/em]","").replace("e400",""))
except KeyError:
content = []
break
write(content)
# 将当前页面的评论传递过来
def write(content):
# 打开一个文件,将列表的内容一行一行的存储下来
with open('comments.txt', 'a', encoding = 'UTF-8') as f:
for i in range(len(content)):
# 因为转为json后\n不胡自动换行,所以我们这里将\n给手换行
string = content[i].split("\\n")
for i in string:
# 因为出现了很多评论被删除的情况,所有我们把这句给过滤掉
i = i.replace("该评论已经被删除", "")
# 打印每条评论
print (i)
# 将评论写入文本
f.writelines(i)
# 给评论换行
f.write("\n")
if __name__ == "__main__":
get_comment()
写入文档的内容大概就是这样:

获取完之后我们就能用wordcloud来进行词云图的制作了:
# -*- coding: utf-8 -*-
import jieba
from wordcloud import WordCloud, STOPWORDS
from os import path
from scipy.misc import imread
# 读取mask/color图片
d = path.dirname(__file__)
color_mask = imread("cyx.png")
#将爬到的评论放在string中
with open('nbzd.txt', 'r', encoding = 'UTF-8') as f:
string = f.read()
word = " ".join(jieba.cut(string))
wordcloud = WordCloud(background_color='white',
mask=color_mask,
max_words=100,
stopwords=STOPWORDS,
font_path='/home/azhao/桌面/素材/simsun.ttc',
max_font_size=100,
random_state=30,
margin=2).generate_from_text(word)
import matplotlib.pyplot as plt
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()
最后展示的结果是这样的:

以上这篇用Python爬取QQ音乐评论并制成词云图的实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持。
您可能感兴趣的文章:
加载全部内容