python识别文字(基于tesseract)代码实例
人气:0这篇文章主要介绍了python识别文字(基于tesseract)代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下
Ubuntu版本:
1.tesseract-ocr安装
sudo apt-get install tesseract-ocr
2.pytesseract安装
sudo pip install pytesseract
3.Pillow 安装
sudo pip install pillow
开始写代码:
from PIL import Image
from pytesseract import pytesseract
image = Image.open('test.png')
code = pytesseract.image_to_string(image,lang='chi_sim')
print(code)
报错了:

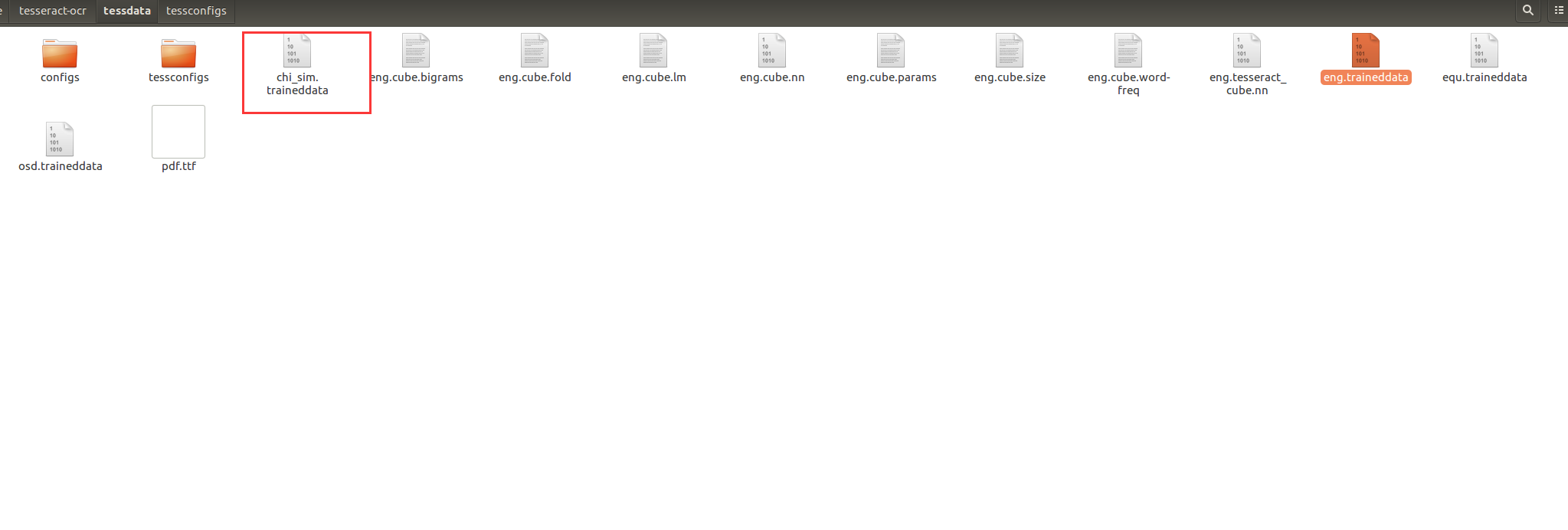
找到路径,发现没有chi_sim.traineddata这个训练包
# 安装训练数据(equ为数学公式包) sudo apt-get install tesseract-ocr-eng tesseract-ocr-chi-sim tesseract-ocr-equ
安装之后就会有训练包了,可以正常运行。
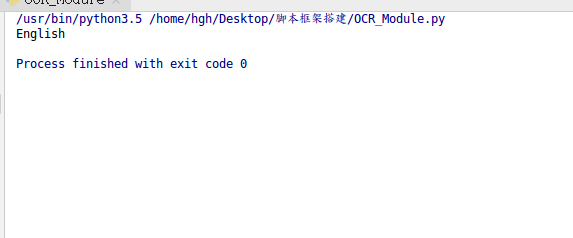
英文识别正确率较高,中文就比较鸡肋了。
您可能感兴趣的文章:
加载全部内容