Python中怎样将一个类方法变为多个方法
人气:0前一篇文章《Python 中如何实现参数化测试?》中,我提到了在 Python 中实现参数化测试的几个库,并留下一个问题:
它们是如何做到把一个方法变成多个方法,并且将每个方法与相应的参数绑定起来的呢?
我们再提炼一下,原问题等于是:在一个类中,如何使用装饰器把一个类方法变成多个类方法(或者产生类似的效果)?
# 带有一个方法的测试类
class TestClass:
def test_func(self):
pass
# 使用装饰器,生成多个类方法
class TestClass:
def test_func1(self):
pass
def test_func2(self):
pass
def test_func3(self):
pass
Python 中装饰器的本质就是移花接木,用一个新的方法来替代被装饰的方法。在实现参数化的过程中,我们介绍过的几个库到底用了什么手段/秘密武器呢?
1、ddt 如何实现参数化?
先回顾一下上篇文章中 ddt 库的写法:
import unittest
from ddt import ddt,data,unpack
@ddt
class MyTest(unittest.TestCase):
@data((3, 1), (-1, 0), (1.2, 1.0))
@unpack
def test(self, first, second):
pass
ddt 可提供 4 个装饰器:1 个加在类上的 @ddt,还有 3 个加在类方法上的 @data、@unpack 和 @file_data(前文未提及)。
先看看加在类方法上的三个装饰器的作用:
import unittest
from ddt import ddt,data,unpack
@ddt
class MyTest(unittest.TestCase):
@data((3, 1), (-1, 0), (1.2, 1.0))
@unpack
def test(self, first, second):
pass
它们的共同作用是在类方法上 setattr() 添加属性。至于这些属性在什么时候使用?下面看看加在类上的 @ddt 装饰器源码:
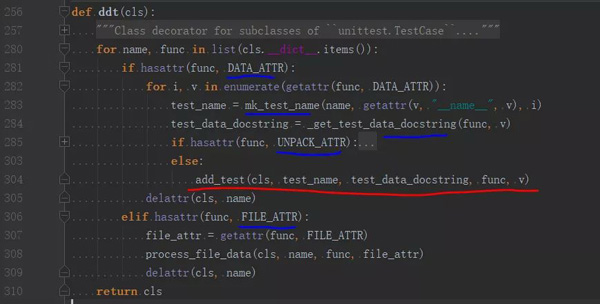
第一层 for 循环遍历了所有的类方法,然后是 if/elif 两条分支,分别对应 DATA_ATTR/FILE_ATTR,即对应参数的两种来源:数据(@data)和文件(@file_data)。
elif 分支有解析文件的逻辑,之后跟处理数据相似,所以我们把它略过,主要看前面的 if 分支。这部分的逻辑很清晰,主要完成的任务如下:
- 遍历类方法的参数键值对
- 根据原方法及参数对,创建新的方法名
- 获取原方法的文档字符串
- 对元组和列表类型的参数作解包
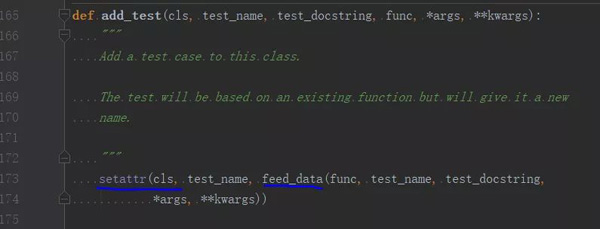
- 在测试类上添加新的测试方法,并绑定参数与文档字符串
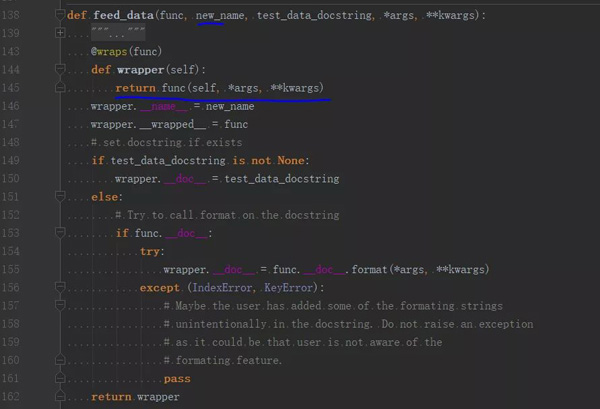
分析源码,可以看出,@data、@unpack 和 @file_data 这三个装饰器主要是设置属性并传参,而 @ddt 装饰器才是核心的处理逻辑。
这种将装饰器分散(分别加在类与类方法上),再组合使用的方案,很不优雅。为什么就不能统一起来使用呢?后面我们会分析它的难言之隐,先按下不表,看看其它的实现方案是怎样的?
2、parameterized 如何实现参数化?
先回顾一下上篇文章中 parameterized 库的写法:
import unittest
from parameterized import parameterized
class MyTest(unittest.TestCase):
@parameterized.expand([(3,1), (-1,0), (1.5,1.0)])
def test_values(self, first, second):
self.assertTrue(first > second)
它提供了一个装饰器类 @parameterized,源码如下(版本 0.7.1),主要做了一些初始的校验和参数解析,并非我们关注的重点,略过。
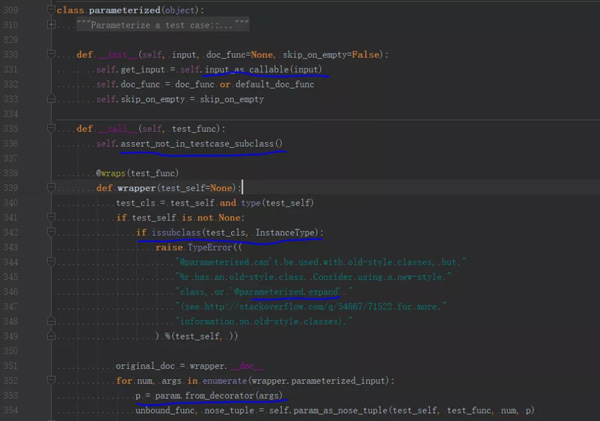
我们主要关注这个装饰器类的 expand() 方法,它的文档注释中写到:
A "brute force" method of parameterizing test cases. Creates new test cases and injects them into the namespace that the wrapped function is being defined in. Useful for parameterizing tests in subclasses of 'UnitTest', where Nose test generators don't work.
关键的两个动作是:“creates new test cases(创建新的测试单元)”和“inject them into the namespace…(注入到原方法的命名空间)”。
关于第一点,它跟 ddt 是相似的,只是一些命名风格上的差异,以及参数的解析及绑定不同,不值得太关注。
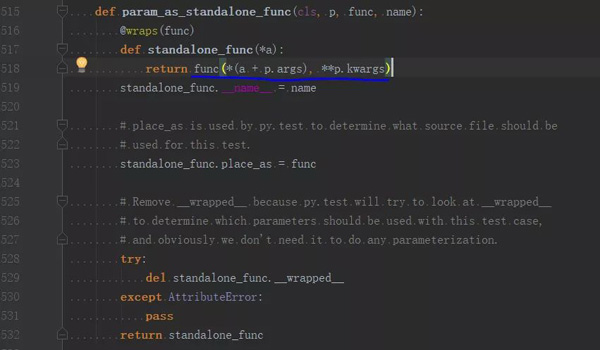
最不同的则是,怎么令新的测试方法生效?
parameterized 使用的是一种“注入”的方式:
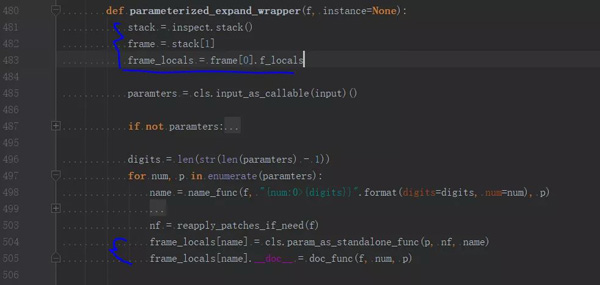
inspect 是个功能强大的标准库,在此用于获取程序调用栈的信息。前三句代码的目的是取出 f_locals,它的含义是“local namespace seen by this frame”,此处 f_locals 指的就是类的局部命名空间。
说到局部命名空间,你可能会想到 locals(),但是,我们之前有文章提到过“locals() 与 globals() 的读写问题”,locals() 是可读不可写的,所以这段代码才用了 f_locals。
3、pytest 如何实现参数化?
按惯例先看看上篇文章中的写法:
import pytest
@pytest.mark.parametrize("first,second", [(3,1), (-1,0), (1.5,1.0)])
def test_values(first, second):
assert(first > second)
首先看到“mark”,pytest 里内置了一些标签,例如 parametrize、timeout、skipif、xfail、tryfirst、trylast 等,还支持用户自定义的标签,可以设置执行条件、分组筛选执行,以及修改原测试行为等等。
用法也是非常简单的,然而,其源码可复杂多了。我们这里只关注 parametrize,先看看核心的一段代码:

根据传入的参数对,它复制了原测试方法的调用信息,存入待调用的列表里。跟前面分析的两个库不同,它并没有在此创建新的测试方法,而是复用了已有的方法。在 parametrize() 所属的 Metafunc 类往上查找,可以追踪到 _calls 列表的使用位置:
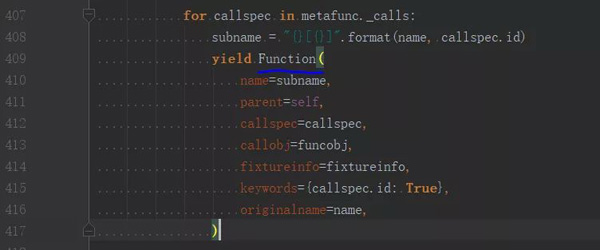
最终是在 Function 类中执行:

好玩的是,在这里我们可以看到几行神注释……
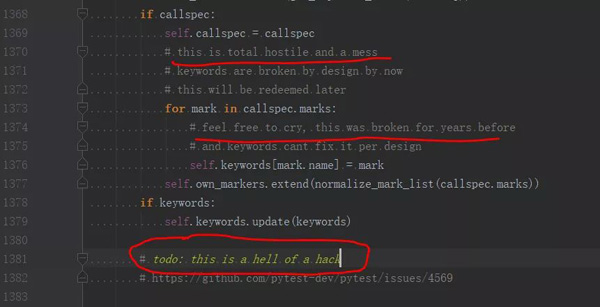
阅读(粗浅涉猎) pytest 的源码,真的是自讨苦吃……不过,依稀大致可以看出,它在实现参数化时,使用的是生成器的方案,遍历一个参数则调用一次测试方法,而前面的 ddt 和 parameterized 则是一次性把所有参数解析完,生成 n 个新的测试方法,再交给测试框架去调度。
对比一下,前两个库的思路很清晰,而且由于其设计单纯是为了实现参数化,不像 pytest 有什么标记和过多的抽象设计,所以更易读易懂。前两个库发挥了 Python 的动态特性,设置类属性或者注入局部命名空间,而 pytest 倒像是从什么静态语言中借鉴的思路,略显笨拙。
4、最后小结
回到标题中的问题“如何将一个方法变为多个方法?”除了在参数化测试中,不知还有哪些场景会有此诉求?欢迎留言讨论。
本文分析了三个测试库的装饰器实现思路,通过阅读源码,我们可以发现它们各有千秋,这个发现本身还挺有意思。在使用装饰器时,表面看它们差异不大,但是真功夫的细节都隐藏在底下。
源码分析的意义在于探究其所以然,在这次探究之旅中,读者们可有什么收获啊?一起来聊聊吧!希望对大家的学习有所帮助,也希望大家多多支持。
您可能感兴趣的文章:
加载全部内容