汇编中的数组分配和指针的实现代码
人气:0数组简介
如果各位猿友是一路跟着LZ看到这里的,那么数组的定义就非常简单了,它就是一个相同数据类型的数据集合。数组存储在一系列逻辑上连续的内存块当中,之所以说是逻辑上连续,是因为整个内存或者说存储器本身就是逻辑上连续的一个大内存数组。如果我们用Java语言的类型来表示我们的存储器的话,可以看做是byte[] memory这样的类型。
数组的定义非常简单,它遵循以下这样简单的规则。
T N[L];
这当中T表示数据类型,N是变量名称,L是数组长度。这样的声明会做两件事,首先是在内存当中开辟一个长为L*length(T)的内存空间(其中length(T)是指数据类型的字节长度),然后将这块内存空间的起始地址赋给变量N。当我们使用N[index]去读取数组元素的时候,我们会去读N+index*length(T)的内存位置,这一点并不难理解。
指针操作数组
在C语言当中,*符号可以取一个指针指向的内存区域的值,而对于数组来说,*符号依然可以这样做。因此,我们可以很轻松地想到,对于上面的声明来说,*N就相当于N[0],类似的,*(N+1)就相当于N[1],以此类推。
在上面*(N+1)这样的方式当中,我们其实对指针进行了运算,即对数组的起始地址N加了上1。在这一过程中,编译器会帮我们自动乘上数据类型的长度(比如int为4),如此一来,我们的指针运算才算是正确了,比如对于*(N+1)来说,假设T为int类型,则 【实际地址(N+1)】 = N + 1 * 4。对于这一点,我们可以用以下这个小程序来验证一下,从这个程序可以很明显的看出来,当我们对指针进行加1操作的时候,实际的地址会被乘以数据类型的长度。
定长和变长数组
要理解定长和变长数组,我们必须搞清楚一个概念,就是说这个“定”和“变”是针对什么来说的。在这里我们说,这两个字是针对编译器来说的,也就是说,如果在编译时数组的长度确定,我们就称为定长数组,反之则称为变长数组。
比如上图当中的示例,就是一个定长数组,它的长度为10,它的长度在编译时已经确定了,因为长度是一个常量。之前的C编译器不允许在声明数组时,将长度定义为一个变量,而只能是常量,不过当前的C/C++编译器已经开始支持动态数组,但是C++的编译器依然不支持方法参数。另外,C语言还提供了类似malloc和calloc这样的函数动态的分配内存空间,我们可以将返回结果强转为想要的数组类型。
接下来,LZ和各位一起分析一个有关数组的C程序,我们先来一个简单的,也就是一个定长数组,我们看下在汇编级别是如何操作定长数组的。需要一提的是,由于数组的长度固定,所以有的时候编译器会根据实际情况作出一些优化,以下是一个简单的小程序。
int main(){
int a[5];
int i,sum;
for(i = 0 ; i < 5; i++){
a[i] = i * 3;
}
for(i = 0 ; i < 5; i++){
sum += a[i];
}
return sum;
}
以上这个小程序的功能LZ就不介绍了,如果哪位猿友看不懂,请自觉面壁吧。下面我们来看下-S和-O1下的汇编代码,如下所示。
main: pushl %ebp movl %esp, %ebp//到此准备好栈帧 subl $32, %esp//分配32个字节的空间 leal -20(%ebp), %edx//将帧指针减去20赋给%edx寄存器?为什么?你能猜到吗? movl $0, %eax//将%eax设置为0,这里的%eax寄存器是重点 .L2: movl %eax, (%edx)//将0放入帧指针减去20的位置? addl $3, %eax//第一次循环时,%eax为3,对于i来说,%eax=(i+1)*3。 addl $4, %edx//将%edx加上4,第一次循环%edx指向帧指针-16的位置 cmpl $15, %eax//比较%eax和15? jne .L2//如果不相等的话就回到L2 movl -20(%ebp), %eax//下面这五句指令已经出卖了leal指令,很明显从-20到-4,就是数组五个元素存放的地方。下面的就不解释了,直接依次相加然后返回结果。 addl -16(%ebp), %eax addl -12(%ebp), %eax addl -8(%ebp), %eax addl -4(%ebp), %eax leave ret
LZ这里就不再一个一个介绍这些指令的作用了,如果各位猿友是一路看过来的,这些指令其实难不倒各位。我们主要来看下跟数组相关的地方。上面其实并没有完全解释清楚数组的赋值操作那一部分,但是后面求和的部分却已经十分清楚了,现在LZ就帮各位串联一下赋值的那部分。为了更加清晰,LZ废话不多说,直接上图。我们看下循环过程中是怎么计算的。

看了这个图相信各位更加清楚程序的意图了,开始将%ebp减去20是为了依次给数组赋值。这里编译器用了非常变态的优化技巧,说真的,LZ编译之前也没想到。那就是编译器发现了a[i+1] = a[i] + 3的规律,因此使用加法(将%eax不断加3)代替了i*3的乘法操作,另外也使用了加法(即地址不断加4,而不使用起始地址加上索引乘以4的方式)代替了数组元素地址计算过程中的乘法操作。而循环条件当中的i<5,也变成了3*i<15,而3*i又等于a[i],因此当整个数组当中循环的索引i,满足a[i+1]=15(注意,在循环内的时候,%eax一直储存着a[i+1]的值,除了刚开始的0)的时候,说明循环该结束了,也就是coml和jne指令所做的事。
搞清楚了上面定长数组的实现,我们会发现,定长数组可以做很多的优化,想象一下,如果上面的数组长度是不定的,编译器还能算出15这个数值吗。接下来我们就来看一个和上面的代码几乎一模一样的程序,只不过这里将换成变长数组。
int sum(int n){
int a[n];
int i,sum;
for(i = 0 ; i < n; i++){
a[i] = i * 3;
}
for(i = 0 ; i < n; i++){
sum += a[i];
}
return sum;
}
可以看到,我们改了一下函数名称,并给函数加了个参数n并将a变为变长数组,其它没做任何改动。下面我们来看下-S和-O1下的汇编代码,看看与定长数组的差距在哪里。
.file "arr.c" .text .globl sum .type sum, @function sum: pushl %ebp movl %esp, %ebp pushl %esi pushl %ebx subl $16, %esp movl 8(%ebp), %ebx movl %gs:20, %edx movl %edx, -12(%ebp) xorl %edx, %edx leal 30(,%ebx,4), %edx andl $-16, %edx subl %edx, %esp leal 15(%esp), %esi andl $-16, %esi testl %ebx, %ebx jle .L2 movl $0, %ecx movl $0, %edx .L3: movl %ecx, (%esi,%edx,4) addl $1, %edx addl $3, %ecx cmpl %ebx, %edx jne .L3 movl $0, %edx .L4: addl (%esi,%edx,4), %eax addl $1, %edx cmpl %ebx, %edx jne .L4 .L2: movl -12(%ebp), %edx xorl %gs:20, %edx je .L6 call __stack_chk_fail .L6: leal -8(%ebp), %esp popl %ebx popl %esi popl %ebp .p2align 4,,1 ret .size sum, .-sum .ident "GCC: (Ubuntu 4.4.3-4ubuntu5.1) 4.4.3" .section .note.GNU-stack,"",@progbits
或许个别猿友看到这一段汇编代码会大吃遗精,因为它看起来比定长数组要复杂太多,不管是长度还是其中的指令。LZ猜测,动态数组的复杂性可能也是动态数组出现较晚的原因,更何况动态数组还有缓冲区溢出的危险。
接下来LZ带着各位猿友分步去看这一段汇编代码,首先我们分析第一部分,包括了栈帧的建立、被调用者保存寄存器的备份以及栈内存的分配。它包括了以下几个开头的指令。
pushl %ebp movl %esp, %ebp pushl %esi pushl %ebx subl $16, %esp
LZ使用一幅图来说明这个问题,我们来分别看看,在指令执行前后,寄存器以及存储器的状态。
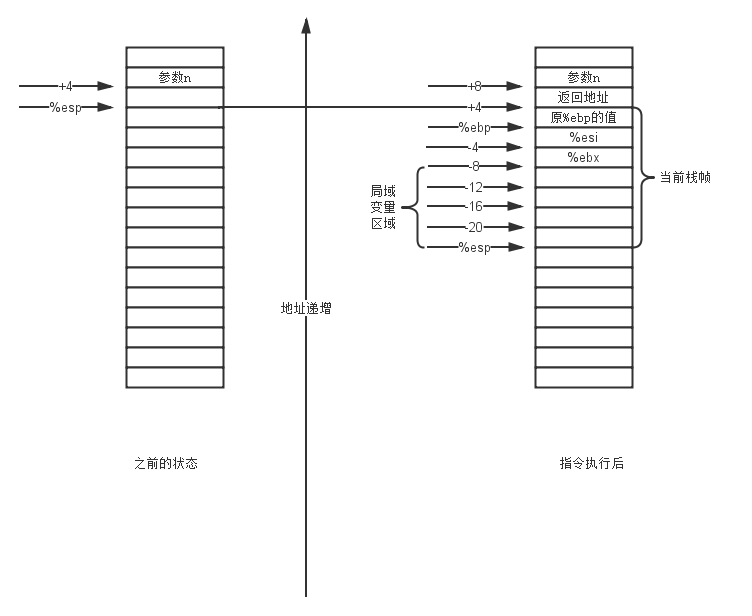
上面的这一过程是比较正常的栈帧建立过程,如果各位猿友看过过程实现那一章的话,那么上面这个过程并不复杂,因此LZ这里就不多说废话了,如果哪位猿友不清楚的话,可以去看看过程实现3.7的那一章。
接下来,我们看看比较复杂的一段代码,这一段代码的主要目的,是为动态数组分配内存。它们是如下的这些指令
movl 8(%ebp), %ebx movl %gs:20, %edx movl %edx, -12(%ebp) xorl %edx, %edx leal 30(,%ebx,4), %edx andl $-16, %edx subl %edx, %esp leal 15(%esp), %esi andl $-16, %esi
这一段代码相对于上一段就复杂了一点,接下来LZ还是先上一个指令执行前后的图,如下。
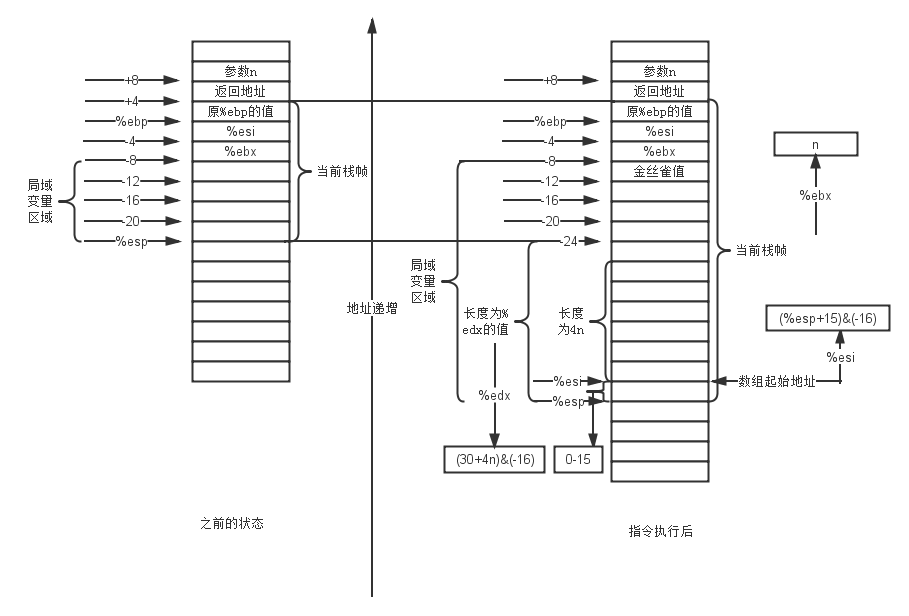
我们仔细对比一下左右两张图可以发现,这里面最主要的两个值,就存在%edx和%esi寄存器当中。其中%edx的值是为数组分配的内存字节数,而%esi当中存储的则是数组的起始地址。我们不难想到,对于一个int类型长度为n的数组,它占用的内存字节数肯定是4n。而这里特别的地方就是,为什么不直接分配4n个字节然后把栈顶作为数组起始位置,而是分配了(30+4n)&(-16)的字节,之后又把(%esp+15)&(-16)的位置作为数组的起始位置?
这个问题的答案就是:为了效率。
为了提高内存的读取速度,一般都会将字节对齐,而针对栈内存的分配,则大部分会保持为16字节的倍数。比如,如果处理器总是一次性从存储器中读取16个字节,则地址必须为16的倍数才行,也就是说地址的后4位必须为0。这样的话我们就好理解了,因为栈帧操作是从栈顶开始,直到帧指针或者备份着被调用者寄存器的内存位置为止(也就是上图中局域变量区域的范围),因此我们需要保证分配的字节数是16的倍数。
如此一来,分配(30+4n)&(-16)个字节,就可以保证上图中-24的位置到%esp依然是16的倍数。因为对于任意一个正整数i来讲,都有i - 15 =< i&(-16) <= i,并且i&(-16)是16的倍数。因此对于(30+4n)&(-16)来说,就有以下结果。
4n + 15 =<(30+4n)&(-16) <= 4n + 30
这就保证了新分配的栈内存大小既是16的倍数,又能装下n个整数,因为它大于4n。不过这里很明显至少多了15个字节,这15个字节会被数组的起始地址消除掉。从图中可以看出,数组的起始地址并不是从栈顶开始的(从%esi指向的位置开始),这是因为数组的起始地址等于(%esp+15)&(-16),而不是%esp。这样做的目的也是为了对齐,只不过这里是地址对齐,将数组的起始地址对齐到16倍数的位置。由上面的结论我们知道。
%esp =<(%esp+15)&(-16) <= %esp + 15
上面的地址保证了数组的起始地址不会逃出栈顶,这也是%esp要加上15的原因。由于数组的起始地址可能上移15位,因此原本预留的空间将可能再次缩小15个字节(位于%esi和%esp之间的那一小段)。因此我们就能得出实际可用的空间stack有如下范围。
4n <= stack <= 4n + 15
这下各位就明白了,为什么4n要加上30,而不是加上15。是因为两次与-16的“与”运算,可能让空间浪费30个字节。所以加上30之后,就可以保证在满足栈内局部变量长度和数组起始位置都为16的倍数的前提下,还能至少留出4n的空间供数组使用。
还有一点需要一提的是,上图当中还出现了一个“金丝雀值”,这个家伙是为了防止栈缓冲区溢出。这当中的值是存储器当中的一个随机值,倘若这个值在函数返回时改变了,那么就代表缓冲区溢出了,就会终止程序的运行。
到此动态数组占用的内存区域就分配好了,接下来的就相对来说比较简单了,基本上与定长数组是一样的。下面是接下来所有的汇编代码,LZ直接加入了详细的注释,相信各位猿友不难看懂。
testl %ebx, %ebx//测试n是否大于0 jle .L2//如果n小于等于0,就跳过两个循环,跳到L2 movl $0, %ecx//%ecx与定长数组中的%eax作用一样,先初始化为0,后面逐渐+3赋给数组元素 movl $0, %edx//%edx就是i,这里是i=0 .L3: movl %ecx, (%esi,%edx,4)//对于i=0的时候来说,这里则相当于a[0]=0,因为%esi是数组起始地址。对于i来说,这里则代表a[i]=%ecx,a[i]的地址为a+4*i。 addl $1, %edx//i自增 addl $3, %ecx//将%eax加3,对于i=0的时候来说,%ecx就是a[1]的值。对于i来说,%ecx就是a[i+1]的值。 cmpl %ebx, %edx//比较n和i jne .L3//如果i和n不相等则继续循环。 movl $0, %edx//再次将i清0,即i=0 .L4: addl (%esi,%edx,4), %eax//%eax就相当于sum,这里其实就是sum = sum + a[i],其中a[i]的地址为a+4*i。 addl $1, %edx//i自增 cmpl %ebx, %edx//比较n和i jne .L4//如果n和i不相等则继续循环 .L2: movl -12(%ebp), %edx//取出金丝雀值 xorl %gs:20, %edx//比较金丝雀值是否改变 je .L6//如果金丝雀值与原来的值相等,则代表缓冲区没溢出,跳到L6继续执行。 call __stack_chk_fail//如果不相等,则代表缓冲区溢出,产生一个栈检查错误。 .L6: leal -8(%ebp), %esp//让栈顶指向备份的%ebx,回收内存。 popl %ebx//还原备份的%ebx值 popl %esi//还原备份的%esi值 popl %ebp//恢复原来的帧指针 .p2align 4,,1//对齐地址为16的倍数 ret//函数返回
上面的这些指令相对来讲就比前面的简单了许多,相信各位猿友看注释就能理解的八九不离十了,唯一特别一点的指令就是最后一个p2align指令。其实之前LZ也没见过这个指令,但是从名字上也能大概看出来是干嘛的,不过最终LZ还是很快google到了这个指令的简单说明。它会将地址对齐为16(也就是第一个参数4,表示2的4次方的意思)的倍数,并最多跳过1个字节(也就是最后的参数1)。如果对齐需要跳过多于1个字节,则会忽略这个指令。
异质结构与数据对齐
异质结构是指不同数据类型的数组组合,比如C语言当中的结构(struct)与联合(union)。在理解数组的基础上,这两种数据结构都非常好理解。我们先来看一个结构的例子,比如下面的这个结构。
#include <stdio.h>
struct {
int a;
int b;
char c;
} mystruct;
int main(){
printf("%d\n",sizeof mystruct);
}
这是一个非常简单的结构体,这个程序在LZ的32位windows系统上,输出结果是12,或许有的猿友还可以得到10或者16这样的结果。或许有的猿友会奇怪,为什么不是4+4+1=9呢。
这正是因为上面我们提到过的对齐的原因,只不过这里的对齐不是地址对齐也不是栈分配空间对齐,而是数据对齐。为了提高数据读取的速度,一般情况下会将数据以2的指数倍对齐,具体是2、4、8还是16,得根据具体的硬件设施以及操作系统来决定。
这样做的好处是,处理器可以统一的一次性读取4(也可能是其它数值)个字节,而不再需要针对特殊的数据类型读取做特殊处理。在这个例子来说,也就是说在读取a、b、c时,都可以统一的读取4个字节。特殊的,这里0-3的位置用于存储a,4-7的位置用于存储b,8的位置用于存储c,而9-11则用于填充,其中都是空的。
与结构体不同的是,联合会复用内存空间,以节省内存,比如我们看下面这个例子。
#include <stdio.h>
union {
int a;
int b;
char c;
} myunion;
int main(){
printf("%d\n",sizeof myunion);
}
这段程序输出的结果是4,依旧是LZ的32位windows操作系统的结果。这是因为a、b、c会共用4个字节,这样做的目的不言而喻,是为了节省内存空间,显然它比结构体节省了8个字节的空间。它与结构体最大的区别就在于,对a、b、c赋值时,联合会覆盖掉之前的赋值,而结构体则不会,结构体可以同时保存a、b、c的值。
对于结构体和联合,LZ这里就不再列举具体的例子了,如果各位掌握了数组的汇编级操作,那么这两个各位猿友完全可以私底下自己分析了。对于对齐来说,LZ还想多说几句。首先各位猿友要分清地址对齐、数据对齐和栈分配对齐的区别。另外一点就是地址对齐的大致规则,一般会依据数据类型的长度来对齐(比如int为4位对齐,double为8位对齐等等),但最低为2。不过这些都不是绝对的,比如double也可能会依据4位对齐,因此具体的对齐规则还是需要根据硬件设施和操作系统决定。
最后一点需要各位明白的是,对齐是在拿空间换时间,也就是说,对齐浪费了存储空间,但提高了运行速度。这有点类似于算法的时间复杂度和空间复杂度,两者大部分情况下总是矛盾的。
浅谈数组与指针
从上面的汇编分析来看,我们可以很轻松的得到一个结论,那就是数组变量其实就是数组的起始地址,就像动态数组例子当中的%esi寄存器一样,它代表着数组a变量,同时也是数组的起始地址。而对于指针的运算,在计算实际地址时,会根据数据类型进行伸缩,比如动态数组一例中,每次在取数组元素时,总有一个权重值是4(比如这个在上面出现过的内存地址(%esi,%edx,4),它就是在读取数组元素),这正是int类型的长度。
您可能感兴趣的文章:
加载全部内容