python 从pdf文件中提取文本,并自动翻译 python实现从pdf文件中提取文本,并自动翻译的方法
PlPyRbC 人气:0针对Python 3.5.2 测试
首先安装两个包:
$ pip install googletrans
$ pip install pdfminer3k
googletrans会提供一个命令translate,这个命令会调用google translate api执行自动翻译:
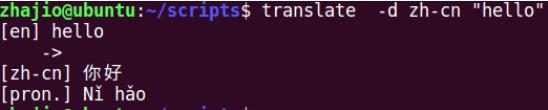


pdfminer3k会提供一个工具脚本pdf2txt.py:
$ pdf2txt.py xxx.pdf
从stackoverflow搜索到可以去除页眉和页脚的命令(强烈推荐):
使用Ubuntu提供的pdftotext工具:
$ pdftotext -y 50 -H 650 -W 1000 -nopgbrk sva.pdf $ pdftotext -f 147 -l 166 -y 50 -H 650 -W 1000 -nopgbrk sva.pdf
谷歌翻译并不能识别段落或者整句,如果一个整句中出现换行符,会发现翻译就不完整了,以网页版谷歌翻译测试:
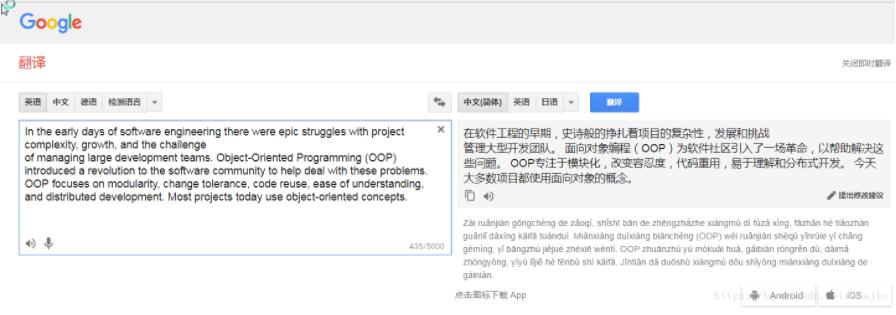
因此需要将pdf转换好的文本文件进行拼接,借用linux args 命令,实现此功能,将整个文件的换行符全部去掉。
但是问题又出现了,整个文件变成一行,我们的段落结构都消失了,那么我们需要手动添加delimiter,设置为一个特殊字符@。
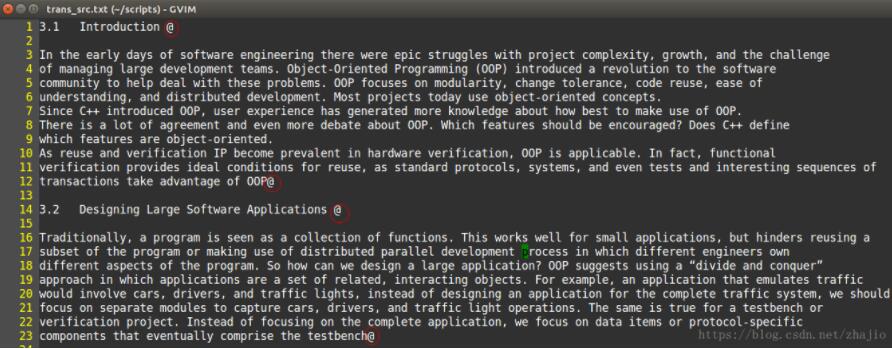
执行如下命令:
cat trans_src.txt |xargs |xargs -0 -d '@' -i{} translate -d zh-cn {} |tee trans_dst.txt
cat sva_src_1to2.txt |xargs |xargs -0 -d '&' -i{} translate -d zh-cn {} |xargs -d'\n' -n4 | awk -F'zh-cn' '{print $2}' | awk -F'[][]' '{print $2}' | tee sva_dst_1to2.txt
将翻译后的文本重定向到一个文件,然后对文件进行简单的后处理,就可以了。
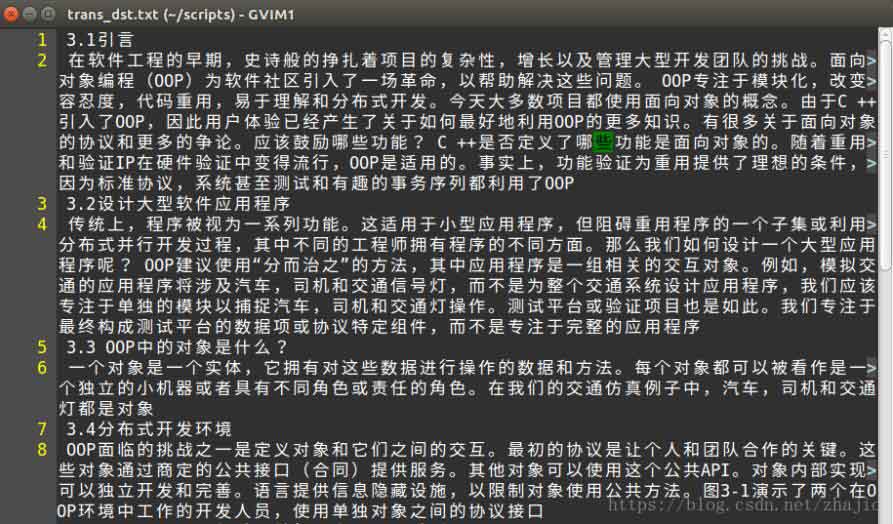
以上这篇python实现从pdf文件中提取文本,并自动翻译的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持。
加载全部内容