一本正经的聊数据结构(2):数组与向量
极客挖掘机 人气:0
前文传送门:
一本正经的聊数据结构(1):时间复杂度
引言
这个系列没有死,我还在更新。
最近事情太多了,这篇文章也是断断续续写了好几天才凑完。
上一篇我们介绍了一个基础概念「时间复杂度」,这篇我们来看第一个真正意义上的数据结构「数组」。
那为什么题目中还会有一个向量呢?这个是什么东西?
不要急,且听我慢慢道来。
内存
在聊数组之前,需要先了解一个硬件,这个就是我们电脑上内存。
先了解一下内存的物理构造,一般内存的外形都长这样:

上面那一个一个的小黑块就是内存颗粒,我们的数据就是存放在那个内存颗粒里面的。
每一个内存颗粒叫做一个 chip 。每个 chip 内部,是由 8 个 bank 组成的。大致长这样(灵魂画手挖掘机老师开始上线):

而每一个 bank 是一个二维平面上的矩阵,矩阵中每一个元素中都是保存了 1 个字节,也就是 8 个 bit ,比如这样:

所以准确的来讲,我们的数据就是放在那一个一个的元素中的。
数组
在 C 、C++ 、Java ,都将数组作为一个基础的数据类型内置。
很可惜,在 Python 中未将数组作为一个基础的数据类型,虽然 Python 中的 list 和数组很像,但是我更愿意叫它列表,而不是数组。
那么数组究竟是啥呢,我这里借用下邓俊辉老师「数据结构」中的定义:
若集合 S 由 n 个元素组成,且各元素之间具有一个线性次序,则可将它们存放于起始于地址 A 、物理位置连续的一段存储空间,并统称作数组( array ) ,通常以 A 作为该数组的标识。具体地,数组 A[] 中的每一元素都唯一对应于某一下标编号,在多数高级程序设计语言中,一般都是从 0 开始编号,依次是 0 号、 1 号、 2 号、 ...、 n - 1 号元素。
其中,对于任何 0 <= i < j < n ,
A[i]都是A[j]的前驱( predecessor ) ,A[j]都是A[i]的后继( successor ) 。特别地,对于任何 i >= 1,A[i - 1]称作A[i]的直接前驱( intermediatep redecessor ) ;对于任何 i <= n - 2 ,A[i + 1]称作A[i]的直接后继( intermediate successor ) 。 任一元素的所有前驱构成其前缀( prefix ) ,所有后继构成其后缀( suffix ) 。

概念永远都是这么的枯燥、乏味以及看不懂。
没关系,继续我的非本职工作「灵魂画手」。
首先了解第一个知识点,数组是放在内存里的,内存的结构我们前面介绍过了,那么数组简单理解就是放在一个一个格子里的,就像这样:

实际上不是这么放的哈,简单理解可以先这么理解,这个涉及到内存对齐的知识,有兴趣的同学可以度娘了解下。
便于理解,我在字母 A 后面加上了数字,这个数字理解为编号,并且是从 0 开始的。
这个结构让我想起了糖葫芦:

数组中的数字就像是穿在棍子上的山楂,大晚上的看的有点流口水。
前驱和后继可以看下面这张图:

A3 是 A4 的直接前驱, A5 是 A4 的直接后继,而排在 A4 前面的都叫 A4 的前驱,排在 A4 后面的都叫 A4 的后继。
向量
那么啥是向量( vector )呢?
这个东西可以简单理解为数组的升级版,在各种编程语言中,大多数都对向量的实现做了内置,不过很可惜,在 Python 中,向量未成为一个基础的数据结构。
那么我就只能对照着 Java 来聊了,向量这个数据结构在 Java 中的实现是:java.util.Vector ,用过 Vector 的应该都是上古程序员了,这个工具类是伴随 JDK1.0 就有的,但是后面逐渐的弃用,原因我们后面有机会再聊,就不在这多说了。
第一个要聊的问题是,我们在使用数组的时候有什么不方便的地方?这个问题换一种问法,其实就是为什么我们需要使用向量(vector)。
首先,我们在使用数组的时候,需要声明数组的大小,因为程序需要根据我们声明的数组大小去向内存申请空间,这就很尴尬了,如果在一个我并不清楚后续可能会用多少空间的场景中,我就没有办法去声明一个数组,因为数组是定长的。
然后就是数组需要是同一数据类型,比如我一个数组如果放入了数组,那么就不能再放入字符串,就不提更加复杂的数据结构,这完全都是因为数组的特性决定的,因为数组在内存上是连续的。
那么遇到了上面的问题怎么办,当然是解决问题咯,这样,数组的第一个升级版 Vector 就出来了,在创建的时候不需要声明大小,然后放入的数据不一定都要是同一个数据类型,比如我想放数字就放数字,想放集合就放集合,想放字符串就放字符串。
声明一点,向量( Vector )的实现是通过数组来实现的。
在 Java 的 Vector 的源代码中可以很清楚的找到证据:
protected Object[] elementData;
动态扩容
这里就会出现第一个问题,数组是定长的,那么向量为什么可以不定长?

当然是向量会自动扩容啦~~~~~
说到自动扩容,不禁让我想起来上面那个糖葫芦,当棍子放不下山楂还想往上放怎么办,当然是把棍子变长点咯:
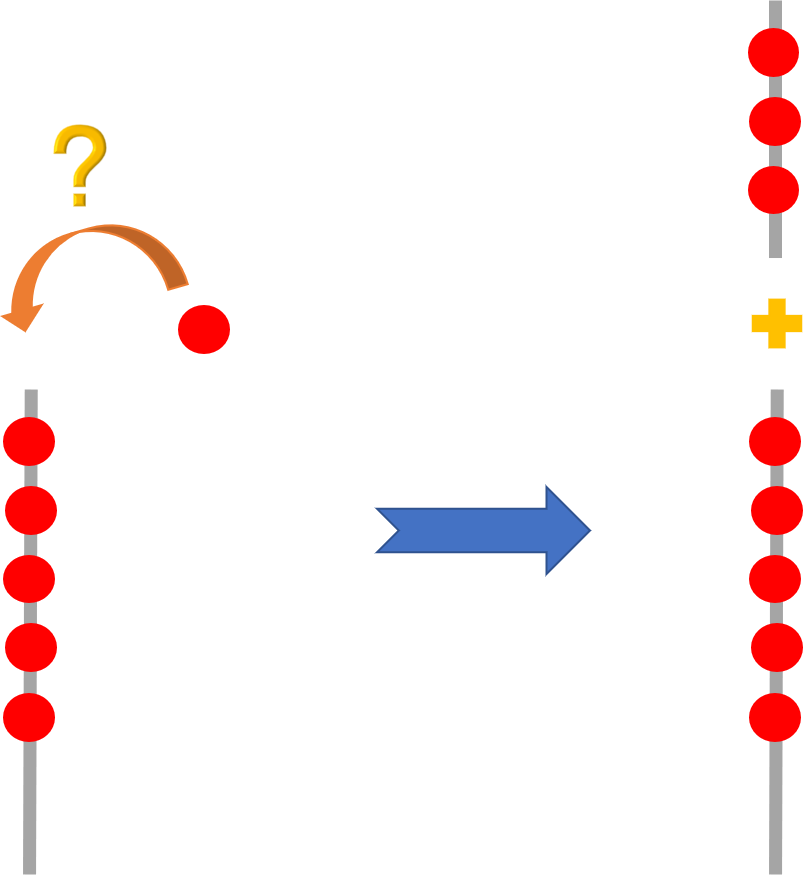
当然,我们在程序中扩容并不是直接把原有数组加长,因为数组的要求是物理空间必须地址连续,而我们却无法保证,其尾部总是预留了足够空间可供拓展。
所以能想到的做法就是另行申请一个容量更大的数组,并将原数组中的成员集体搬迁至新的空间,比如这样:
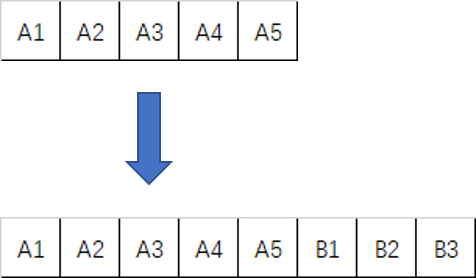
那么,问题又产生一个,每次变长(扩容)的时候,变长(扩容)多少合适呢?
因为每次扩容的时候,元素的搬迁都需要花费额外的时间,这对性能是一个损耗,我们并不希望这个损耗过大,那么是不是可以一次扩容扩的足够大呢?当然也不行,这样会造成内存的浪费,虽然内存便宜,但也不是这么浪费的。
比如初始长度是 10 ,第一次扩容直接扩容到 100 ,第二次到 1000 ,这个就太夸张了,这里可以直接参考 JDK 的源码,看下大神是怎么扩容的。
篇幅原因我就不带大家在这看 Java 的源码了,直接说结果,照顾下学 Python 的同学:
在 Java 中 Vector 的初始长度定义为 10 ,当元素个数超过原有容量长度 1 时,进行扩容,每次扩容的大小是原容量的 1 倍,那么就是第一次扩容是从 10 变成了 20 。
至于为什么是扩大 1 倍而不是其他这里就不展开讨论了,实际上 Java 在另一个数据结构列表( List )中扩容的大小是 0.5 倍 + 1 。
不同数据类型
还是拿上面的糖葫芦举例子,如果一个杆上只能穿山楂,那么它是一个糖葫芦(数组),但是,只想穿山楂的糖葫芦不是一个好糖葫芦。
但我在吃山楂的同时还想吃臭豆腐,小龙虾,扇贝,生蚝,帝王蟹,成年人的世界,就是我全都要这么朴实无华。

然后糖葫芦开启了超进化模式:

变成了下面这玩意:

这个功能在 Java 中的实现是通过 Object 数组来实现的,因为 Object 在 Java 中是所有类的超类,这个接触过 Java 的同学应该都清楚,如果没有接触过 Java ,可以这么理解,借用道德经里一句话:
道生一,一生二,二生三,三生万物
而这个 Object 就是那个一,由这个一才产生了丰富多彩的 Java 世界,所以 Object 数组是可以转化为任何类型的。
小结
小结一下吧,我们聊了一个最简单的数据结构,数组,还从数组中引申出来了向量( Vector ),很遗憾,Python 中没有这两个基础数据结构。
在向量( Vector )中,我们介绍了向量( Vector )的两个不同于数组的特性,一个是动态扩容,还有一个是向量中可以放不同的数据类型,这对比数组极大的方便了我们日常的使用。
顺便说一句,虽然很多数据结构都是基于数组的,包括本文介绍的 Vector ,还有后面会介绍到的列表 List ,但是我们在实际的使用中是很少会直接使用数组的,基本上都是使用数组的超进化体。
参考
https://zhuanlan.zhihu.com/p/83449008
加载全部内容