布隆过滤器
Howlet 人气:0在Redis的缓存穿透中了解到布隆过滤器,不禁想来了解一番其奇妙之处
1. 布隆过滤器的作用
判断传入数据是否已经存在,由这个基本功能可以泛生出:
- 防止Redis缓存穿透
- 海里数据去重
- 垃圾邮件过滤
2. 什么是布隆过滤器
布隆过滤器(Bloom Filter)是1970年由一个叫布隆的人提出的,它本质是一个很长的二进制向量(位数组)和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。其优点是空间效率和查询时间都比一般的算法好太多,这是布隆过滤器的出名之处。缺点是有一定的误识别率和删除困难
在布隆过滤器的位数组中,每个元素占一个位(1bit)其内容只能是0或1。其占空间效率小体现:一亿个元素只占用约12MB(100000000bit / 8 / 1024 / 1024 = 11.92MB)
3. 实现原理
我们将传进来的数据进行多次不同的Hash,从而得到多个哈希值,然后将这多个哈希值对应的位数组下标设为1
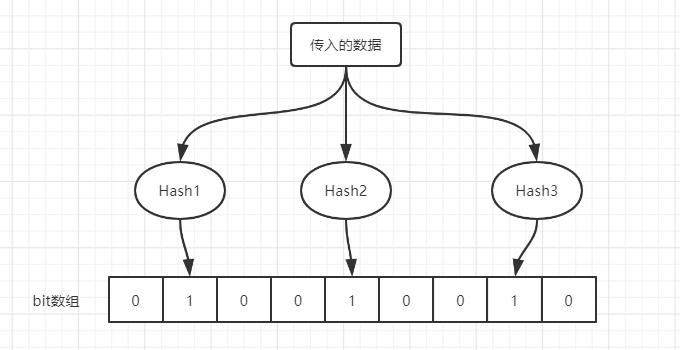
通过图示我们能大概了解其原理了,布隆过滤器存放的不是数据本身,而是数据的多个Hash值。这样当某个数据被 "存入" 布隆过滤器时,这个数据再次进来,可通过在位数组中查找多个对应的Hash值是否为1,都为1则表明已经存在
缺点也显而易见:1. Hash值计算可能会有冲突,不同的数据 "存入" 布隆过滤器的结果可能相同,也就是说布隆过滤器
只能判断数据不存在,而无法明确判断数据存在。2.存入的数据删除困难
实现关键:
- Hash函数
- 位数组长度
4. Google开源的布隆过滤器
1.导包
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>28.2-jre</version>
<https://img.qb5200.com/download-x/dependency>
2.使用
public class Test {
public static void main(String[] args) {
// 创建布隆过滤器,依次为:数据类型,预计数据条数,期望误判率
BloomFilter bloomFilter = BloomFilter.create(Funnels.integerFunnel(), 10000000, 0.02);
// "存入" 一千万条数据
for (int i = 0; i < 10000000; i++) {
bloomFilter.put(i);
}
// 记录误判个数
int count = 0;
for (int i = 10000000; i < 20000000; i++) {
if (bloomFilter.mightContain(i)){
count++;
}
}
System.out.println("误判总数:" + count);
System.out.println("误判率:" + (count / 10000000.0) + "%");
}
}
误判总数:200914
误判率:0.0200914%
5. Redis实现布隆过滤器
Redis4.0版本之后添加了Module模块,Modules可让Redis使用外部模块扩展其功能。Redis官网导航栏有Modules标签,然后找到RedisBloom下载
下载完后解压编译,记住里面的redisbloom.so路径
tar -zxvf RedisBloom-2.2.2.tar.gz
cd RedisBloom-2.2.2
make
pwd # /opt/RedisBloom-2.2.2
设置配置文件redis.conf
################################## MODULES #####################################
loadmodule /opt/RedisBloom-2.2.2/redisbloom.so
基本命令与使用:
- BF.ADD
- BF.EXISTS
127.0.0.1:6379> BF.ADD howl 007
(integer) 1
127.0.0.1:6379> BF.EXISTS howl 007
(integer) 1
127.0.0.1:6379> BF.EXISTS howl 008
(integer) 0
127.0.0.1:6379>
加载全部内容