大数据篇:Hbase
咘雷扎克 人气:0大数据篇:Hbase

- Hbase是什么
Hbase是一个分布式、可扩展、支持海量数据存储的NoSQL数据库,物理结构存储结构(K-V)。
- 如果没有Hbase
如何在大数据场景中,做到上亿数据秒级返回。(有条件:单条数据,范围数据)
hbase.apache.org
1 Hbase结构及数据类型
- 逻辑结构
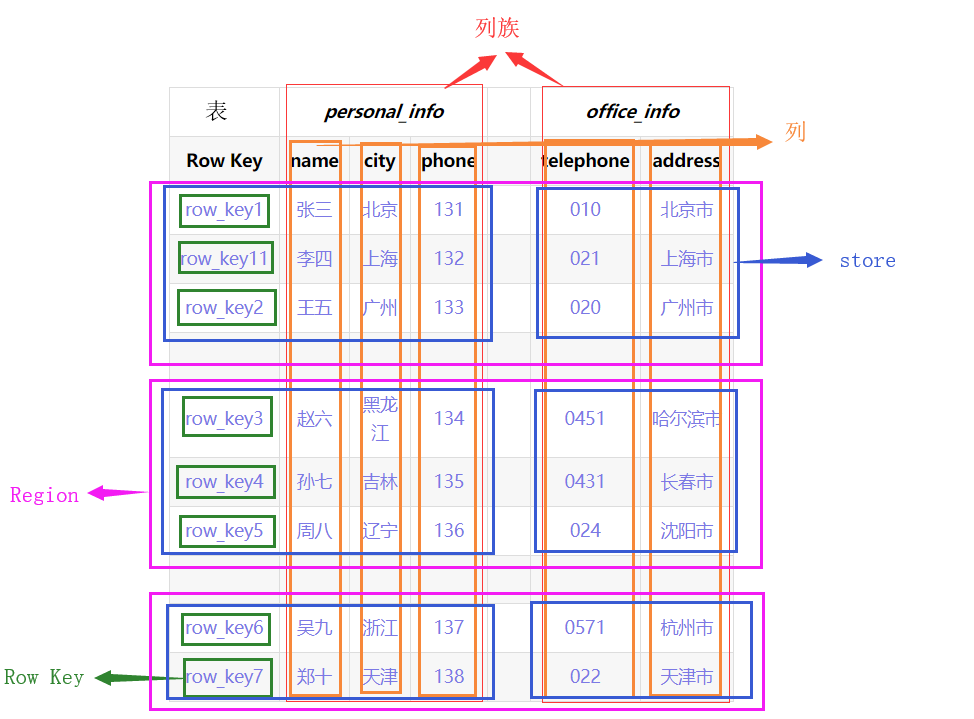
- 物理结构
整张表会按照水平方向按照Row Key切割(Region)。再按垂直方向按ColumnFamily切割(Store),
-
Name Space:命名空间
- 类似于关系型数据库中的database概念,每个命名空间下可以放多个表,默认存在2个命名空间:hbase和default,hbase存放Hbase内置的表,default表是用户默认使用的命名空间。(例如给order表赋予命名空间test,可以写为test:order)
-
Row:行
- Hbase中每行数据都由一个RowKey和多个列组成。
-
Column:列
- Hbase中的每个列都由ColumnFamily(列族)和ColumnQualifier(列限定符)进行限定,(例如:personal_info:name,personal_info:city)
-
Cell:单元
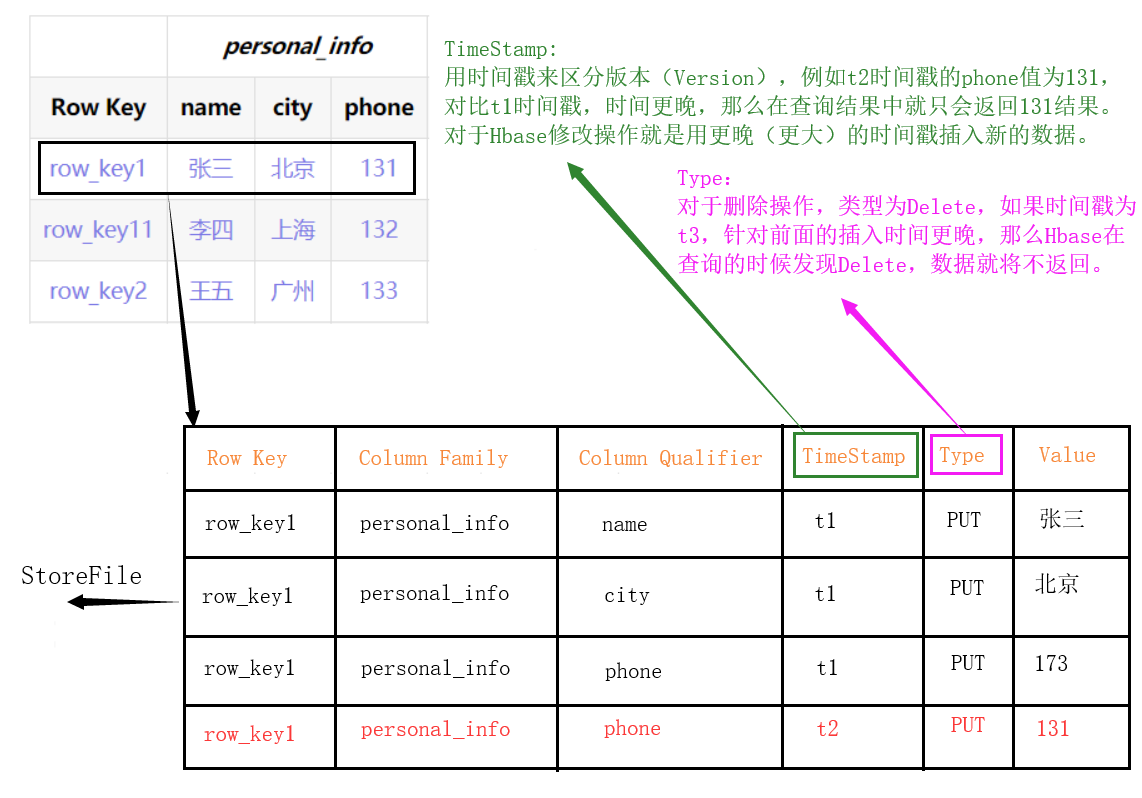
- 由{RowKey,ColumnFamily,ColumnQualifier,TimeStamp}唯一确定的单元,Cell中的数据是没有类型的,全部为字节码形式储存。
-
Row Key:行键
- Row Key在表中必须是唯一的而且必须存在的。
- Row Key是 按照字典序一位一位比较有序排列的(有值比没有值大)。例如row_key11 排列在row_key1和row_ley2之间。
- 所有对表的访问都要通过Row Key 。(单个RowKey访问,或RowKey范围访问,或全表扫描)
-
ColumnFamily:列族
- 创建Hbase表时,只需要给定CF即可,在插入数据时,列(字段)可以动态、按需增加。
- 每个CF可以有一个或多个列成员(ColumnQualifier)。
- 不同列族放在hdfs不同文件夹中存储。
-
TimeStamp:时间戳
- 用于标识数据的不同版本,如果不指定时间戳,Hbase在写入数据时会自动加上当前系统时间戳为该字段值。
2 Hbase架构
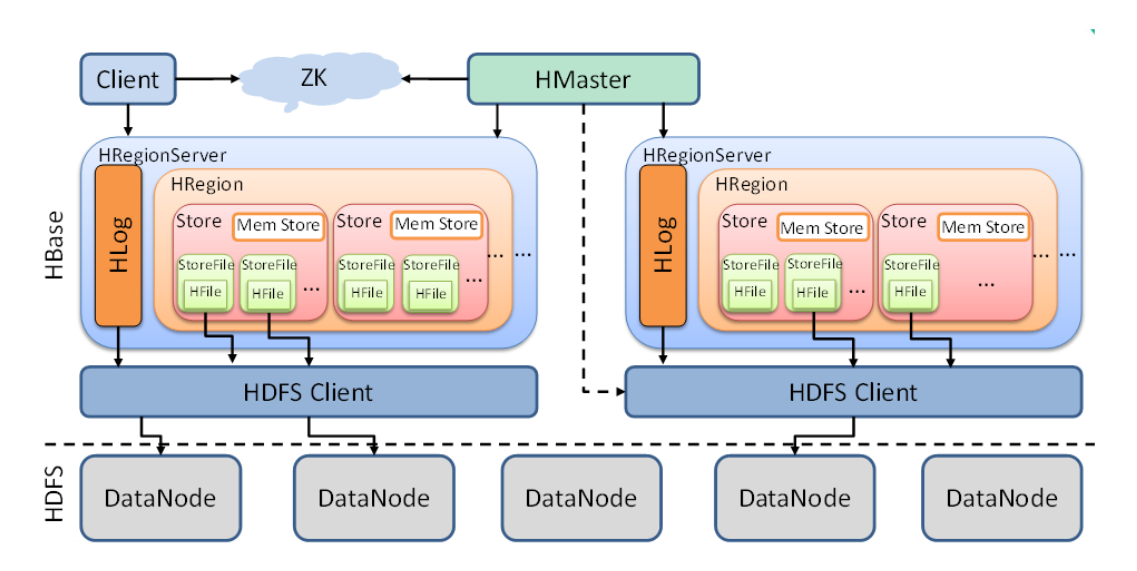
下面从小到大解释上图中的各组件中的功能。
-
StoreFile
- StoreFile为HBase真正存储的文件,最终通过HDFS客户端存入DataNode。(也就是linux磁盘中)
-
Store
- 可以理解为一个切片Region中的一组列族。(如上图一个Region中有多个Store)
- Store中包含Mem Store(内存存储),StoreFile(由内存刷入的数据,数量多了会合并,数据大了会切分)
-
Region
- Region可以理解为一张表的切片,Region按照数据量大小阀值和Row key进行切分。
- HBase自动把表水平(按行)划分成多个区域(region),每个region会保存一个表里面某段连续的数据。
- 每个表一开始只有一个region,随着数据不断插入,region不断增大,当增大到一个阀值的时候,region就会根据Row key等分为两个新的region,以此类推。
- Table中的行不断增多,就会有越来越多的region,一张表数据就被保存在多个Region 上。
-
HLog
- Hbase的预写日志,防止特殊情况下的数据丢失。
-
RegionServer
- 数据的操作(DML):get,put,delete
- 管理Region:SplitRegion(切分),CompactRegion(合并)
-
Master
- 表级别操作(DDL):create,delete,alter
- 管理RegionServer:监控RegionServer状态,分配Regions到RegionServer,(如有机器rs1,rs2,rs3,数据写入rs1,rs2上的Region,r3空闲--->这时rs1被大量写入数据达到Region上限,rs1将Region等分后,就会通知Master将其中一份发往rs3管理。)
3 命令行操作
3.1 链接hbase
- 链接hbase
hbase shell
- 查看帮助命令或命令详细使用
help
help '命令'
3.2 命名空间操作
3.2.1 查询命名空间
list_namespace

3.2.2 查询命名空间下的表
list_namespace_tables '命名空间名'

3.2.3 创建命名空间
create_namespace '命名空间名'

3.2.4 删除命名空间(需要namespace是空的)
drop_namespace '命名空间名'
3.3 DDL操作
3.3.1 查询所有用户表
list
3.3.2 创建表
create '命名空间:表', '列族1', '列族2', '列族3','列族4'...


如图发现有一串乱乱序文件夹,这串乱序就代表了Region号

3.3.3 查看表详情
describe '命名空间:表'

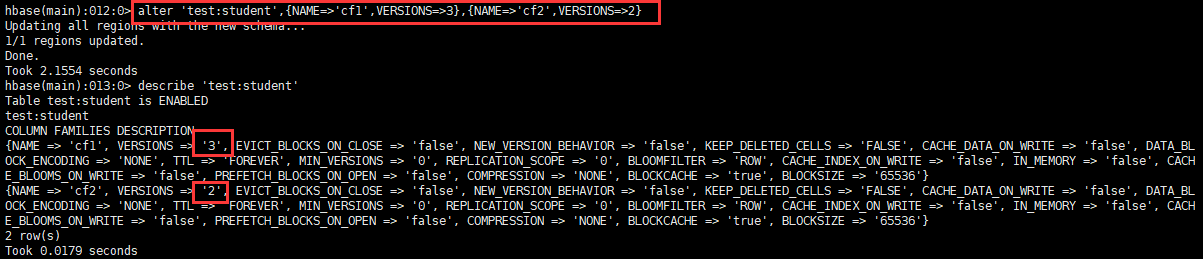
可以看出VERSIONS为1,代表这个表只能存放一个版本的数据。
3.3.4 变更表信息
主要用于修改表的版本保存信息,也可以创建表的时候指定,但是shell命令复杂,故一般使用变更命令。
alter '命名空间:表',{NAME=>'列族名',VERSIONS=>3}

3.3.5 修改表状态(删除前必须失效表)
- 失效表
disable '表'
- 启用表
enable '表'
3.3.6 删除表
delete '表'
3.4 DML操作
3.4.1 插入数据
put '命名空间:表','RowKey','列族:列','值'
put '命名空间:表','RowKey','列族:列','值',时间戳(版本控制)


如图发现并没有数据文件生成,因为数据在内存中,需要flush '表',而后就可以看见数据落地了。(flush一次就是生成一个StoreFile)

3.4.2 扫描表
#全表扫描
scan '命名空间:表'
#范围扫描(左闭右开)
scan '命名空间:表',{STARTROW => 'RowKey',STOPROW=>'RowKey'}
#扫描N个版本的数据
scan '命名空间:表',{RAW=>true,VERSIONS=>10}
3.4.3 Flush刷写

flush '命名空间:表'
- 数据版本保留机制
从上面知道flush一次就是生成一个StoreFile,那么数据就会根据建表保留版本个数来存储最近个数的数据。
比如:保留版本个数为2,那么如果插入v1,v2,v3三条数据,flush后,就只剩下v2,v3两条数据,这时再插入v4,v5,v6三条数据,flush后,剩下的为v2,v3,v5,v6四个版本的数据(此时是2个StoreFile文件),如果发生Region合并或者分裂,那么StoreFile文件会被合并后在放入对应的Region中,这时数据就又会根据保留版本个数删除,v2,v3,v5,v6,就变成了v5,v6。(如果没有手动flush,或者到设置的自动flush时间,那么数据不会根据版本个数删除)(默认超过3个StoreFile文件则会进行大合并)
- 一个列族对应一个MemStore
- 每个MemStore在刷写到HDFS时,生成的StoreFile是独立的
- RegionServer全局MemStore刷写时机:hbase.regionserver.global.memstore.size
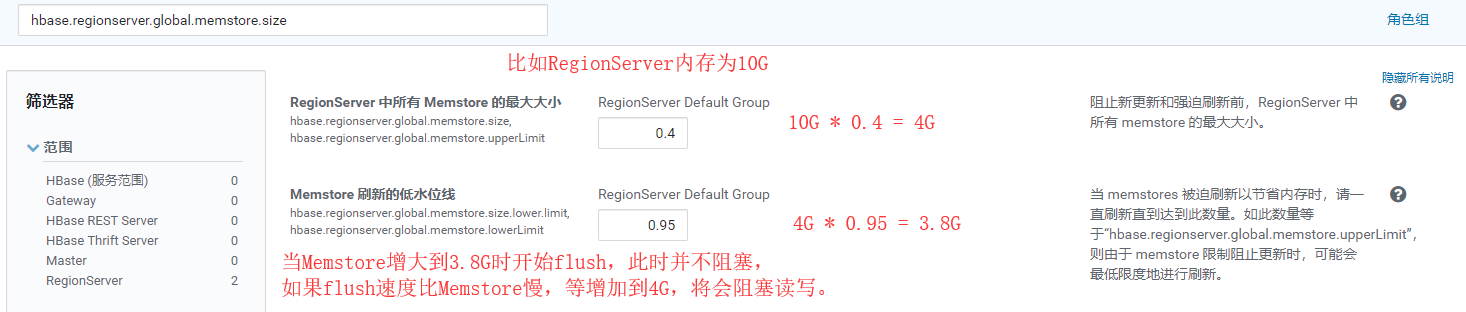
- 单个Memstore刷写时机:hbase.hregion.memstore.flush.size

3.4.3 查询数据
get '命名空间:表','RowKey'
get '命名空间:表','RowKey','列族'
get '命名空间:表','RowKey','列族:列'
#获取N个版本的数据
get '命名空间:表','RowKey',{COLUMN=>'列族:列',VERSIONS=>10}

3.4.4 清空表
truncate '命名空间:表'
3.4.5 删除数据
#delete '命名空间:表','RowKey','列族'(此命令行删除有问题,但是API可以)
delete '命名空间:表','RowKey','列族:列'
deleteall '命名空间:表','RowKey'
4 读写流程
4.1 写流程

- 客户端通过ZK查询元数据存储表的所在RegionServer所在位置并返回


- 查询元数据,返回需要表的RegionServer


-
客户端缓存信息,方便下次使用
-
发送PUT请求到RegionServer,写操作日志(WAL),再写入内存,然后同步wal到HDFS,则结束。(此步骤由事务回滚保证日志、内存都写入成功)
4.2 读流程

在读取数据时候,MemStore和StoreFile一起读取,将StoreFile中的数据放入BlockCache,然后在将内存数据和BlockCache比较时间戳做Merge,取最新的数据返回。
5 合并切分
- 合并Compaction
由于Memstore每次刷写都会生成一个新的HFile,且同一个字段的不同版本和不同类型有可能会分布在不同的HFile中,因此查询时需要遍历所有的HFile。为了减少HFile的个数,以及清理掉过期和删除的数据,会进行StoreFile合并。
Compaction分为Minor Compaction和Major Compaction。
Minor Compaction会将临近的若干个较小的HFile合并成一个较大的HFile,但不会清理过期和删除的数据。
Major Compaction会将一个Store下的所有HFile合并成一个大的HFile,并且会清理掉过期和删除的数据。
参数设置:
hbase.hregion.majorcompaction=0
hbase.hregion.majorcompaction.jitter=0
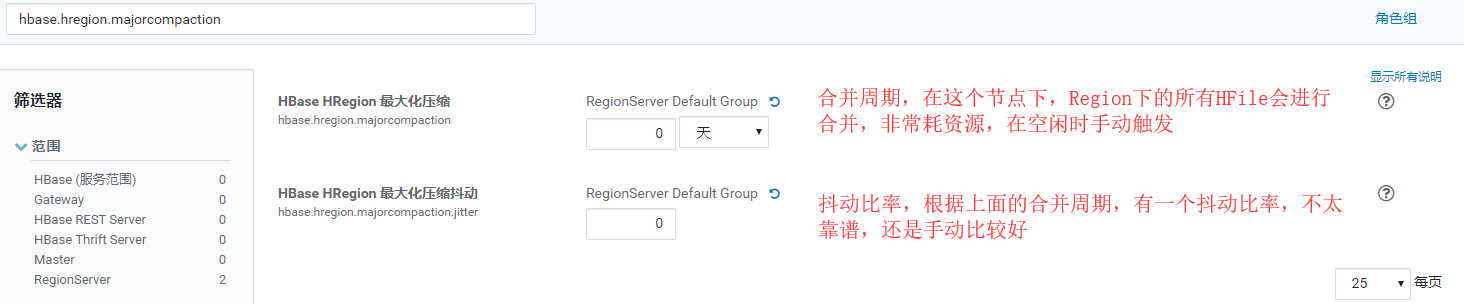
hbase.hstore.compactionThreshold=3

- 切分
默认情况下,每个Table起初只有一个Region,随着数据的不断写入,Region会自动进行拆分,刚拆分时,两个子Region都位于当前Region Server,但处于负载均衡的考虑,HMaster有可能会将某个Region转移给其他的Region Server。
参数设置:
hbase.hregion.max.filesize=5G (如下公式中为Max1)(可以减小该值,提高并发)
hbase.hregion.memstore.flush.size=258M (如下公式中为Max2)
每次切分将会比较Max1和Max2的值,取小的。[min(Max1,Max2 * Region个数 * 2)],其中Region个数为当前Region Server中数据该Table的Region个数。
由于自动切分无法避免热点问题,所以在生产中我们常常使用预分区和设计RowKey避免出现热点问题


6 优化
6.1 尽量不要使用多个列族
为了避免flush时产生多个小文件。
6.2 内存优化

主要作用来缓存Table数据,但是flush时会GC,不要太大,根据集群资源,一般分配整个Hbase集群内存的70%,16->48G就可以了
6.3 允许在HDFS中追加内容
dfs.support.append=true (hdfs-site.xml、hbase-site.xml)
6.4 优化DataNode允许最大文件打开数
dfs.datanode.max.transfer.threads=4096 (HDFS配置)
在Region Server级别的合并操作中,Region Server不可用,可以根据集群资源调整该值,增加并发。
6.5 调高RPC监听数量
hbase.regionserver.handler.count=30
根据集群情况,可以适当增加该值,主要决定是客户端的请求数。
6.6 优化客户端缓存
hbase.client.write.buffer=100M (写缓存)
调高该值,可以减少RPC调用次数,单数会消耗更多内存,根据集群资源情况设定。
6.7 合并切分优化
参考5合并切分
6.8 预分区
- 创建表时候加入参数SPLITS
create '命名空间:表', '列族1', '列族2', '列族3','列族4'...,SPLITS=>['分区号','分区号','分区号','分区号']


根据数据量预估半年到一年的数据量,和Region最大值来选择预分区数。
6.9 RowKey
- 散列性:均匀分部到不同的Region里
- 唯一性:不会重复
- 长度:70-100位
方案一:随机数,hash值,但是这种不能范围查询,没有数据的集中性。
方案二:字符串反转,比如时间戳反转后就达到了散列性,但是在查看的时候集中性只是优于第一种。
- 生产方案推荐:
#设计预分区键(如比如200个区) | ASCLL码为124只有 } 和 ~ 比它大,那么不管以后的RowKey使用什么字符,都是小于这个字符的,所以可以有效的得到RowKey规律
000|
001|
......
199|
# 1 设计RowKey键_ASCLL码为95
000_
001_
......
199_
# 2 根据业务唯一标识(如用户ID,手机号,SFZ)和时间维度(比如按月:202004)计算后根据分区数取余(13408657784^202004)%199=分区号
# 想以什么时间进行查询就把什么往前提,如下数据需要查1月数据范围就是 000_13408657784_2020-04 -> 000_13408657784_2020-04|
000_13408657784_2020-04-01 12:12:12
......
199_13408657784_2020-04-01 24:12:12
加载全部内容