手把手教大家如何用scrapy爬虫框架爬取王者荣耀官网英雄资料
徐阶 人气:0之前被两个关系很好的朋友拉入了王者荣耀的大坑,奈何技术太差,就想着做一个英雄的随查手册,这样就可以边打边查了。菜归菜,至少得说明咱打王者的态度是没得说的,对吧?大神不喜勿喷!!!感谢!!废话不多说,开始上干货
一 .需要准备的工具
vscoede,安装好的scrapy框架,浏览器,PhantomJS无界面浏览器(或者chromedriver)
二 . 预期目标
爬取王者荣耀官网上77位英雄的ID,名字,皮肤名字,生存能力,攻击伤害,技能效果,上手难度(这四项均是百分制),技能信息,技能加点,铭文建议,推荐出装,英雄故事
三 . 制作过程
1.通过命令行创建scrapy文件夹,并且用vscode打开
2.创建基本流程
items文件

pipeline(管道)文件:

这里为了将python中的dict对象按照一定的格式写入文件,这里采用了json模块,关于这个问题,可以参考我的另一篇博文:
python如何将字典格式化写入文件当中:https://www.cnblogs.com/RosemaryJie/p/12449764.html
在写入文件的过程中,如果出现乱码的问题,请参考:
python编码的原理以及写入文件中乱码的问题:https://www.cnblogs.com/RosemaryJie/p/12364099.html
middleware文件:
配置浏览器User-Agent
如何配置请参考:
python基于scrapy框架的反爬虫机制破解之User-Agent伪装:https://www.cnblogs.com/RosemaryJie/p/12336662.html
写好这些文件之后一定要记得在settings文件中进行配置
3.页面分析(以孙尚香 香香为例)
导入的库:

技能加点部分:
浏览器所显示出来的XHTML文档部分(检查者工具):

网页源代码:

可以明显看到,检查者工具和网页源代码中关于技能加点部分的源代码是不一样的。这时候我们可以采用selenium模块驱动模拟浏览器来获得我们所需要XHTML文本内容(也就是检查者工具里所呈现出的)
为了此篇博客的简介,具体相关内容在这里不再赘述,感兴趣的同学可以移步参考此篇博文:
爬虫如何使用phantomjs无头浏览器解决网页源代码经过渲染的问题(以scrapy框架为例):https://www.cnblogs.com/RosemaryJie/p/12454190.html
这里采用的方法是重新用所获得XHTML文本构建一个新的HtmlResponse对象

解决了浏览器渲染问题之后,剩下的问题就很简单了,常规xpath提取信息而已,在这里就直接上原码了


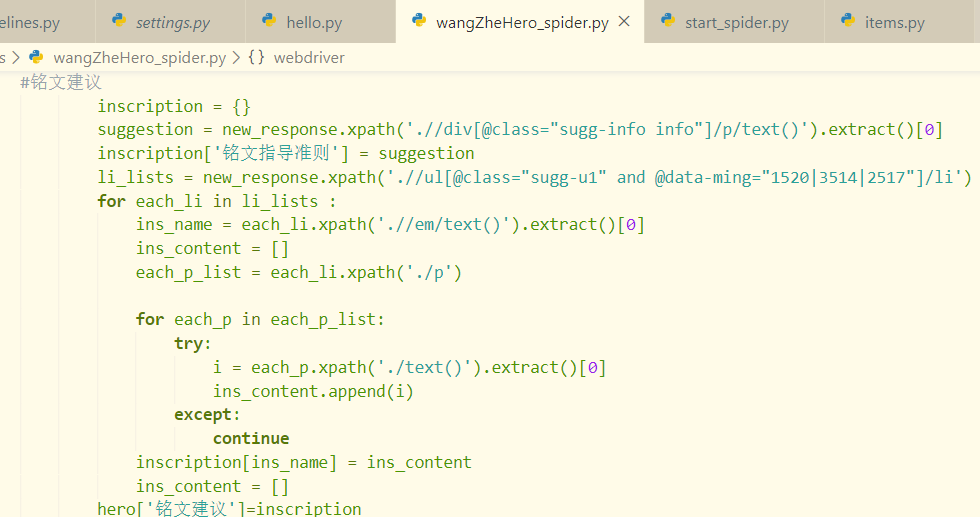



4.运行爬虫即可
至此,一个实用又装逼的爬虫程序就此大功告成
四 .效果图:


在做这个爬虫程序的时候,作为小白,也遇到了不少的坑,也算积攒了些许经验。如果有喜欢王者的同好碰到问题的话,也欢迎在评论区留言交流,我也会尽我所能地帮大家大家做一些解答。
码字不易,点个赞再走呗!
加载全部内容