NLP(二十四)利用ALBERT实现命名实体识别
山阴少年 人气:1
本文将会介绍如何利用ALBERT来实现`命名实体识别`。如果有对`命名实体识别`不清楚的读者,请参考笔者的文章[NLP入门(四)命名实体识别(NER)](https://blog.csdn.net/jclian91/articlehttps://img.qb5200.com/download-x/details/84073265) 。
本文的项目结构如下:
其中,`albert_zh`为ALBERT提取文本特征模块,这方面的代码已经由别人开源,我们只需要拿来使用即可。data目录下为我们本次讲解所需要的数据,图中只有example开头的数据集,这是人民日报的标注语料,实体为人名(PER)、地名(LOC)和组织机构名(ORG)。数据集一行一个字符以及标注符号,标注系统采用`BIO`系统,我们以example.train的第一句为例,标注信息如下:
```
海 O
钓 O
比 O
赛 O
地 O
点 O
在 O
厦 B-LOC
门 I-LOC
与 O
金 B-LOC
门 I-LOC
之 O
间 O
的 O
海 O
域 O
。 O
```
在`utils.py`文件中,配置了一些关于文件路径和模型参数方面的信息,其中规定了输入的文本长度最大为128,代码如下:
```python
# -*- coding: utf-8 -*-
# author: Jclian91
# place: Pudong Shanghai
# time: 2020-03-11 21:12
# 数据相关的配置
event_type = "example"
train_file_path = ".https://img.qb5200.com/download-x/data/%s.train" % event_type
dev_file_path = ".https://img.qb5200.com/download-x/data/%s.dev" % event_type
test_file_path = ".https://img.qb5200.com/download-x/data/%s.test" % event_type
# 模型相关的配置
MAX_SEQ_LEN = 128 # 输入的文本最大长度
```
在`load_data.py`文件中,我们将处理训练集、验证集和测试集数据,并将标签转换为id,形成label2id.json文件,代码如下:
```python
# -*- coding: utf-8 -*-
# author: Jclian91
# place: Pudong Shanghai
# time: 2020-03-11 10:04
import json
from utils import train_file_path, event_type
# 读取数据集
def read_data(file_path):
# 读取数据集
with open(file_path, "r", encoding="utf-8") as f:
content = [_.strip() for _ in f.readlines()]
# 添加原文句子以及该句子的标签
# 读取空行所在的行号
index = [-1]
index.extend([i for i, _ in enumerate(content) if ' ' not in _])
index.append(len(content))
# 按空行分割,读取原文句子及标注序列
sentences, tags = [], []
for j in range(len(index)-1):
sent, tag = [], []
segment = content[index[j]+1: index[j+1]]
for line in segment:
sent.append(line.split()[0])
tag.append(line.split()[-1])
sentences.append(''.join(sent))
tags.append(tag)
# 去除空的句子及标注序列,一般放在末尾
sentences = [_ for _ in sentences if _]
tags = [_ for _ in tags if _]
return sentences, tags
# 读取训练集数据
# 将标签转换成id
def label2id():
train_sents, train_tags = read_data(train_file_path)
# 标签转换成id,并保存成文件
unique_tags = []
for seq in train_tags:
for _ in seq:
if _ not in unique_tags:
unique_tags.append(_)
label_id_dict = dict(zip(unique_tags, range(1, len(unique_tags) + 1)))
with open("%s_label2id.json" % event_type, "w", encoding="utf-8") as g:
g.write(json.dumps(label_id_dict, ensure_ascii=False, indent=2))
if __name__ == '__main__':
label2id()
```
运行代码,生成的example_label2id.json文件如下:
```
{
"O": 1,
"B-LOC": 2,
"I-LOC": 3,
"B-PER": 4,
"I-PER": 5,
"B-ORG": 6,
"I-ORG": 7
}
```
生成该文件是为了方便我们后边的模型训练和预测的时候调用。
接着就是最重要的模型训练部分了,模型的结构图如下:
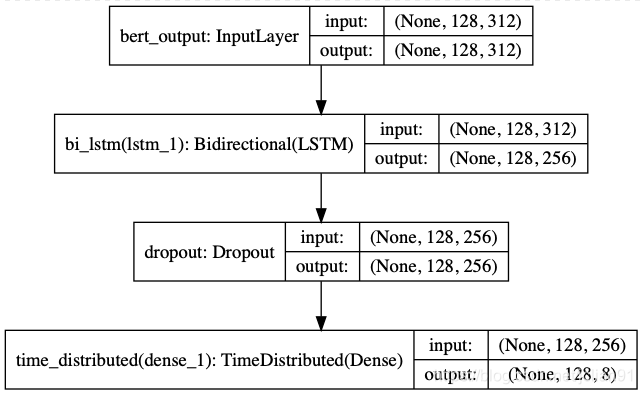
我们采用ALBERT作为文本特征提取,后接经典的序列标注算法——Bi-LSTM算法。`albert_model_train.py`的完整代码如下:
```python
# -*- coding: utf-8 -*-
import json
import numpy as np
from keras.models import Model, Input
from keras.layers import Dense, Bidirectional, Dropout, LSTM, TimeDistributed, Masking
from keras.utils import to_categorical, plot_model
from seqeval.metrics import classification_report
import matplotlib.pyplot as plt
from utils import event_type
from utils import MAX_SEQ_LEN, train_file_path, test_file_path, dev_file_path
from load_data import read_data
from albert_zh.extract_feature import BertVector
# 利用ALBERT提取文本特征
bert_model = BertVector(pooling_strategy="NONE", max_seq_len=MAX_SEQ_LEN)
f = lambda text: bert_model.encode([text])["encodes"][0]
# 读取label2id字典
with open("%s_label2id.json" % event_type, "r", encoding="utf-8") as h:
label_id_dict = json.loads(h.read())
id_label_dict = {v:k for k,v in label_id_dict.items()}
# 载入数据
def input_data(file_path):
sentences, tags = read_data(file_path)
print("sentences length: %s " % len(sentences))
print("last sentence: ", sentences[-1])
# ALBERT ERCODING
print("start ALBERT encding")
x = np.array([f(sent) for sent in sentences])
print("end ALBERT encoding")
# 对y值统一长度为MAX_SEQ_LEN
new_y = []
for seq in tags:
num_tag = [label_id_dict[_] for _ in seq]
if len(seq) < MAX_SEQ_LEN:
num_tag = num_tag + [0] * (MAX_SEQ_LEN-len(seq))
else:
num_tag = num_tag[: MAX_SEQ_LEN]
new_y.append(num_tag)
# 将y中的元素编码成ont-hot encoding
y = np.empty(shape=(len(tags), MAX_SEQ_LEN, len(label_id_dict.keys())+1))
for i, seq in enumerate(new_y):
y[i, :, :] = to_categorical(seq, num_classes=len(label_id_dict.keys())+1)
return x, y
# Build model
def build_model(max_para_length, n_tags):
# Bert Embeddings
bert_output = Input(shape=(max_para_length, 312, ), name="bert_output")
# LSTM model
lstm = Bidirectional(LSTM(units=128, return_sequences=True), name="bi_lstm")(bert_output)
drop = Dropout(0.1, name="dropout")(lstm)
out = TimeDistributed(Dense(n_tags, activation="softmax"), name="time_distributed")(drop)
model = Model(inputs=bert_output, outputs=out)
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 模型结构总结
model.summary()
plot_model(model, to_file="albert_bi_lstm.png", show_shapes=True)
return model
# 模型训练
def train_model():
# 读取训练集,验证集和测试集数据
train_x, train_y = input_data(train_file_path)
dev_x, dev_y = input_data(dev_file_path)
test_x, test_y = input_data(test_file_path)
# 模型训练
model = build_model(MAX_SEQ_LEN, len(label_id_dict.keys())+1)
history = model.fit(train_x, train_y, validation_data=(dev_x, dev_y), batch_size=32, epochs=10)
model.save("%s_ner.h5" % event_type)
# 绘制loss和acc图像
plt.subplot(2, 1, 1)
epochs = len(history.history['loss'])
plt.plot(range(epochs), history.history['loss'], label='loss')
plt.plot(range(epochs), history.history['val_loss'], label='val_loss')
plt.legend()
plt.subplot(2, 1, 2)
epochs = len(history.history['acc'])
plt.plot(range(epochs), history.history['acc'], label='acc')
plt.plot(range(epochs), history.history['val_acc'], label='val_acc')
plt.legend()
plt.savefig("%s_loss_acc.png" % event_type)
# 模型在测试集上的表现
# 预测标签
y = np.argmax(model.predict(test_x), axis=2)
pred_tags = []
for i in range(y.shape[0]):
pred_tags.append([id_label_dict[_] for _ in y[i] if _])
# 因为存在预测的标签长度与原来的标注长度不一致的情况,因此需要调整预测的标签
test_sents, test_tags = read_data(test_file_path)
final_tags = []
for test_tag, pred_tag in zip(test_tags, pred_tags):
if len(test_tag) == len(pred_tag):
final_tags.append(test_tag)
elif len(test_tag) < len(pred_tag):
final_tags.append(pred_tag[:len(test_tag)])
else:
final_tags.append(pred_tag + ['O'] * (len(test_tag) - len(pred_tag)))
# 利用seqeval对测试集进行验证
print(classification_report(test_tags, final_tags, digits=4))
if __name__ == '__main__':
train_model()
```
模型训练过程中的输出结果如下(部分输出省略):
```
sentences length: 20864
last sentence: 思想自由是对自我而言,用中国传统的说法是有所为;兼容并包是指对待他人,要有所不为。
start ALBERT encding
end ALBERT encoding
sentences length: 2318
last sentence: 良性肿瘤、恶性肿瘤虽然只是一字之差,但两者有根本性的差别。
start ALBERT encding
end ALBERT encoding
sentences length: 4636
last sentence: 因此,村民进行民主选举的心态是在这样一种背景映衬下加以表现的,这无疑给该片增添了几分厚重的历史文化氛围。
start ALBERT encding
end ALBERT encoding
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
bert_output (InputLayer) (None, 128, 312) 0
_________________________________________________________________
bi_lstm (Bidirectional) (None, 128, 256) 451584
_________________________________________________________________
dropout (Dropout) (None, 128, 256) 0
_________________________________________________________________
time_distributed (TimeDistri (None, 128, 8) 2056
=================================================================
Total params: 453,640
Trainable params: 453,640
Non-trainable params: 0
_________________________________________________________________
Train on 20864 samples, validate on 2318 samples
......
......
......
20864/20864 [==============================] - 97s 5ms/step - loss: 0.0091 - acc: 0.9969 - val_loss: 0.0397 - val_acc: 0.9900
precision recall f1-score support
ORG 0.9001 0.9112 0.9056 2185
LOC 0.9383 0.8898 0.9134 3658
PER 0.9543 0.9415 0.9479 1864
micro avg 0.9310 0.9084 0.9196 7707
macro avg 0.9313 0.9084 0.9195 7707
```
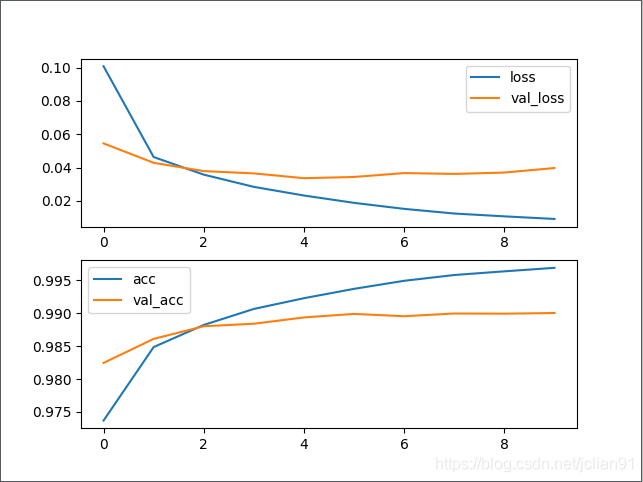
在测试集上的F1值为91.96%。同时,训练过程中的loss和acc曲线如下图:
模型预测部分的代码(脚本为model_predict.py)如下:
```python
# -*- coding: utf-8 -*-
# author: Jclian91
# place: Pudong Shanghai
# time: 2020-03-11 13:16
import json
import numpy as np
from albert_zh.extract_feature import BertVector
from keras.models import load_model
from collections import defaultdict
from pprint import pprint
from utils import MAX_SEQ_LEN, event_type
# 读取label2id字典
with open("%s_label2id.json" % event_type, "r", encoding="utf-8") as h:
label_id_dict = json.loads(h.read())
id_label_dict = {v: k for k, v in label_id_dict.items()}
# 利用ALBERT提取文本特征
bert_model = BertVector(pooling_strategy="NONE", max_seq_len=MAX_SEQ_LEN)
f = lambda text: bert_model.encode([text])["encodes"][0]
# 载入模型
ner_model = load_model("%s_ner.h5" % event_type)
# 从预测的标签列表中获取实体
def get_entity(sent, tags_list):
entity_dict = defaultdict(list)
i = 0
for char, tag in zip(sent, tags_list):
if 'B-' in tag:
entity = char
j = i+1
entity_type = tag.split('-')[-1]
while j < min(len(sent), len(tags_list)) and 'I-%s' % entity_type in tags_list[j]:
entity += sent[j]
j += 1
entity_dict[entity_type].append(entity)
i += 1
return dict(entity_dict)
# 输入句子,进行预测
while 1:
# 输入句子
text = input("Please enter an sentence: ").replace(' ', '')
# 利用训练好的模型进行预测
train_x = np.array([f(text)])
y = np.argmax(ner_model.predict(train_x), axis=2)
y = [id_label_dict[_] for _ in y[0] if _]
# 输出预测结果
pprint(get_entity(text, y)
```
随机在网上找几条新闻测试,结果如下:
>Please enter an sentence: 昨天进行的女单半决赛中,陈梦4-2击败了队友王曼昱,伊藤美诚则以4-0横扫了中国选手丁宁。
{'LOC': ['中国'], 'PER': ['陈梦', '王曼昱', '伊藤美诚', '丁宁']}
Please enter an sentence: 报道还提到,德国卫生部长延斯·施潘在会上也表示,如果不能率先开发出且使用疫苗,那么60%至70%的人可能会被感染新冠病毒。
{'ORG': ['德国卫生部'], 'PER': ['延斯·施潘']}
Please enter an sentence: “隔离结束回来,发现公司不见了”,网上的段子,真发生在了昆山达鑫电子有限公司员工身上。
{'ORG': ['昆山达鑫电子有限公司']}
Please enter an sentence: 真人版的《花木兰》由新西兰导演妮基·卡罗执导,由刘亦菲、甄子丹、郑佩佩、巩俐、李连杰等加盟,几乎是全亚洲整容。
{'LOC': ['新西兰', '亚洲'], 'PER': ['妮基·卡罗', '刘亦菲', '甄子丹', '郑佩佩', '巩俐', '李连杰']}
本项目已经开源,Github网址为:[https://github.com/percent4/ALBERT_NER_KERAS](https://github.com/percent4/ALBERT_NER_KERAS) 。
本文到此结束,感谢大家阅读,欢迎关注笔者的微信公众号:`Python爬虫与算法`。
加载全部内容