C#数据结构 C#数据结构揭秘一
人气:0这里,我们 来说一说C#的数据结构了。
①什么是数据结构。数据结构,字面意思就是研究数据的方法,就是研究数据如何在程序中组织的一种方法。数据结构就是相互之间存在一种或多种特定关系的数据元素的集合。 程序界有一点很经典的话,程序设计=数据结构+算法。用源代码来体现,数据结构,就是编程。他有哪些具体的关系了,
(1) 集合(Set):如图 1.1(a)所示,该结构中的数据元素除了存在“同属于一个集合”的关系外,不存在任何其它关系。 集合与数学的集合类似,有无序性,唯一性,确定性。
(2) 线性结构(Linear Structure):如图 1.1(b)所示,该结构中的数据元素存在着一对一的关系。我们.net程序员做的最多的工作就是对数据库的表crud,二表的最小的数据单元是行。每行数据是最明显的线性结构。
(3) 树形结构(Tree Structure):如图 1.1(c)所示,该结构中的数据元素存在着一对多的关系。现实中,家族关系中是最明显的树形结构。如图所示

而对于我们.net程序员来说,操作的树形控件是也是最明显的树形结构
(4) 图状结构(Graphic Structure):如图 1.1(d)所示,该结构中的数据元素存在着多对多的关系。在现实中,图应用的太多了,如图所示:

对于我们。net程序员应用的较少,当你用C++作一些底层应用,如搜索引擎,地图导航应用的蛮多的。
以上是针对数据结构的介绍。
做过开发的人员都知道这个道理,算法与数据结构和程序的关系非常密切。 进行程序设计时,先确定相应的数据结构,然后再根据数据结构和问题的需要设计相应的算法。
②那什么是算法了?算法,就是计算的方法了,就是解决问题的方案,就是对某一特定类型的问题的求解步骤的一种描述, 是指令的有限序列。 用源代码体现,算法就是编程的体现。一个算法应该具备以下 5个特性:
1、有穷性(Finity):一个算法总是在执行有穷步之后结束,即算法的执行时间是有限的。我们初学.net时候,经常写着死循环,这不是算法,因为这是无穷的。
2、确定性(Unambiguousness):算法的每一个步骤都必须有确切的含义,即无二义,并且对于相同的输入只能有相同的输出。对于我们.net程序员写出二义性的源代码,编译器根本让你通不过。
3、输入(Input):一个算法具有零个或多个输入。它即是在算法开始之前给出的数据结构这些输入是某数据结构中的数据对象。编程是解决问题的,如果不能输入的话,怎么解决问题了。
4、 输出(Output):一个算法具有一个或多个输出,并且这些输出与输入之间存在着某种特定的关系。 编程就是解决了生活中问题,你不让用户看到最后的结果,这就失去了编程的意义。
5、 能行性(realizability):算法中的每一步都可以通过已经实现的基本运算的有限次运行来实现。这与有穷性息息相关。
那算法的评价标准又是什么了?
评价一个算法优劣的主要标准如下:1、 正确性(Correctness)。2、可读性(Readability)3、健壮性(Robustness)。4、运行时间(Running Time)。5、占用空间(Storage Space)。
前3个性质,我们很好拿捏。与我们程序员息息相关的是运行时间与占用空间。然而,随着硬件越来越便宜,面对占用空间,我们无非增加硬件。面对海量数据,我们尤为关心是运行时间(Running Time)。这此时的计算机的运行时间由以下因素决定:
1、硬件条件。包括所使用的处理器的类型和速度(比如,使用双核处理器还是单核处理器) 、可使用的内存(缓存和 RAM)以及可使用的外存等。
2、实现算法所使用的计算机语言。实现算法的语言级别越高,其执行效率相对越低。
3、所使用的语言的编译器/解释器。一般而言,编译的执行效率高于解释,但解释具有更大的灵活性。
4、所使用的操作系统软件。操作系统的功能主要是管理计算机系统的软件和硬件资源,为计算机用户方便使用计算机提供一个接口。各种语言处理程序如编译程序、解释程序等和应用程序都在操作系统的控制下运行。
评价运行时间就是一个算法时间复杂度, 一个算法的时间复杂度(Time Complexity)是指该算法的运行时间与问题规模的对应关系。
算法中的基本操作一般是指算法中最深层循环内的语句,因此,算法中基本操作语句的频度是问题规模n的某个函数f(n),记作:T(n)=O(f(n))。其中“O”表示随问题规模n的增大,算法执行时间的增长率和f(n)的增长率相同,或者说,用“O”符号表示数量级的概念。 这些 都只是一些理论的概念,我们这里用计时器来证明这个理论概念。
如:
①x=n; /*n>1*/
y=0;
while(y < x)
{
y=y+1; ①
}
从理论上分析这是一重循环的程序,while 循环的循环次数为 n,所以,该程序段中语句①的频度是 n,则程序段的时间复杂度是 T(n)=O(n) 。
从程序上验证,当n=10时,运行结果如图所示:

当n=100000时,运行结果如图所示
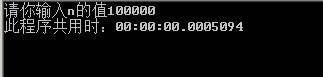
由此证明,其中算法的时间复杂度确实是接近于O(n)
②
for(i=1;i<n;++i) {
for(j=0;j<n;++j)
{
A[i][j]=i*j; ①
}
}
理论上解释为这是二重循环的程序,外层for循环的循环次数是n,内层for循环的循环次数为n,所以,该程序段中语句①的频度为n*n,则程序段的时间复杂度
为T(n)=O(n²) 。
从程序上证明,当n=10,其运行效果如图所示:

当n=100000,其运行效果如图所示:

由此证明,其中算法的时间复杂度确实是接近于O(n²)
③x=n; /*n>1*/
y=0;
while(x >= (y+1)*(y+1))
{
y=y+1; ①
}
这是一重循环的程序,while 循环的循环次数为 n,所以,该程序段中语句①的频度是 n,则程序段的时间复杂度是 T(n)=O(√n) 。
从程序证明:当n=10时,运行效果如图所示:

当n=100000时,运行效果如图所示:

由此证明,其中算法的时间复杂度确实是接近于O(√n)
本文一介绍了数据结构的基本概念 而介绍了算法的基本概念,并且重点讨论了算法时间复杂度,并且用程序予以证明。
加载全部内容