C#数据结构与算法揭秘 C#数据结构与算法揭秘五 栈和队列
人气:0这节我们讨论了两种好玩的数据结构,栈和队列。
老样子,什么是栈, 所谓的栈是栈(Stack)是操作限定在表的尾端进行的线性表。表尾由于要进行插入、删除等操作,所以,它具有特殊的含义,把表尾称为栈顶(Top) ,另一端是固定的,叫栈底(Bottom) 。当栈中没有数据元素时叫空栈(Empty Stack)。这个类似于送饭的饭盒子,上层放的是红烧肉,中层放的水煮鱼,下层放的鸡腿。你要把这些菜取出来,这就引出来了栈的特点先进后出(First in last out)。 具体叙述,加下图。

栈通常记为:S= (a1,a2,…,an),S是英文单词stack的第 1 个字母。a1为栈底元素,an为栈顶元素。这n个数据元素按照a1,a2,…,an的顺序依次入栈,而出栈的次序相反,an第一个出栈,a1最后一个出栈。所以,栈的操作是按照后进先出(Last In First Out,简称LIFO)或先进后出(First In Last Out,简称FILO)的原则进行的, 因此, 栈又称为LIFO表或FILO表。 栈的操作示意图如图所示。

栈的形式化定义为:栈(Stack)简记为 S,是一个二元组,顾定义为S = (D, R)
其中:D 是数据元素的有限集合;
R 是数据元素之间关系的有限集合。
栈的一些基本操作的概述:由于栈只能在栈顶进行操作, 所以栈不能在栈的任意一个元素处插入或删除元素。因此,栈的操作是线性表操作的一个子集。栈的操作主要包括在栈顶插入元素和删除元素、取栈顶元素和判断栈是否为空等等方面的操作。
同样,我们以 C#语言的泛型接口来表示栈,接口中的方法成员表示基本操作。为表示的方便与简洁,把泛型栈接口取名为 IStack(实际上,在 C#中没有泛型接口 IStack<T>, 泛型栈是从 IEnumerable<T>和 ICollection 等接口继承而来,这一点与线性表有着本质的区别) 。
栈的接口定义源代码如下所示。
public interface IStack<T> {
//初始条件:栈存在;操作结果:返回栈中数据元素的个数。
int GetLength(); //求栈的长度 伪代码 index++
//初始条件:栈存在; 操作结果:如果栈为空返回 true,否则返回 false。伪代码 if(top==null) return true;else return false;
bool IsEmpty(); //判断栈是否为空
//初始条件:栈存在; 操作结果:使栈为空。伪代码 top=null;
void Clear(); //清空操作
//初始条件:栈存在; 操作结果:将值为 item 的新的数据元素添加到栈顶,栈发生变化。伪代码 top=item;index++;
void Push(T item); //入栈操作
//初始条件:栈存在且不为空; 操作结果:将栈顶元素从栈中取出,栈发生变化 伪代码:return top;index--;
T Pop(); //出栈操作
//初始条件:栈表存在且不为空; 操作结果:返回栈顶元素的值,栈不发生变化。伪代码 get top;
T GetTop(); //取栈顶元素
}
栈也分为两种的形式,一种是顺序栈,一种是链栈。
第一种 顺序栈(Sequence Stack):
用一片连续的存储空间来存储栈中的数据元素,这样的栈称为顺序栈(Sequence Stack)。类似于顺序表,用一维数组来存放顺序栈中的数据元素。栈顶指示器 top 设在数组下标为 0 的端,top 随着插入和删除而变化,当栈为空时,top=-1。下图是顺序栈的栈顶指示器 top与栈中数据元素的关系图。

顺序栈类 SeqStack<T>源代码的实现如下所示。
public class SeqStack<T> : IStack<T> {
private int maxsize; //顺序栈的容量 最大的存储空间
private T[] data; //数组,用于存储顺序栈中的数据元素 存储数据的多少
private int top; //指示顺序栈的栈顶 栈顶指针
//索引器
public T this[int index]
{
get
{
return data[index];
}
set
{
data[index] = value;
}
}
//容量属性
public int Maxsize
{
get
{
return maxsize;
}
set
{
maxsize = value;
}
}
//栈顶属性
public int Top
{
get
{
return top;
}
}
//构造器 进行相应初始化的工作 进行赋值
public SeqStack(int size)
{
data = new T[size];
maxsize = size;
top = -1;
}
//求栈的长度 用头指针来加一
public int GetLength()
{
return top+1;
}
如图所示:

//判断顺序栈是否为空
//就是判断头指针是否为-1 为就为空 不为就为假
public bool IsEmpty()
{
if (top == -1)
{
return true;
}
else
{
return false;
}
}
具体如下图所示:

//判断顺序栈是否为满 或最大尺寸相比较 相等 返回真 不相等返回假
public bool IsFull()
{
if (top == maxsize-1)
{
return true;
}
else
{
return false;
}
}
相应情况,一切尽在图例中。

//入栈 将其放入顶部 top 加加
public void Push(T item)
{
//如果满了 就不进行添加
if(IsFull())
{
Console.WriteLine("Stack is full");
return;
}
//进行加入到顶部
data[++top] = item;
}
具体情况,一切尽在图例中

//出栈 进行出栈后 头指针减减
public T Pop()
{
T tmp = default(T);
if (IsEmpty())
{
Console.WriteLine("Stack is empty");
return tmp;
}
tmp = data[top];
--top;
return tmp;
具体情况,一切尽在图例中。

//获取栈顶数据元素 把头指针指向的元素进行弹出的操作
public T GetTop()
{
//如果是空 就返回一个默认值
if (IsEmpty())
{
Console.WriteLine("Stack is empty!");
return default(T);
}
return data[top];
具体情况,一切尽在图例中:

}
}
}
这就是对顺序栈的相应的介绍。
下面,我们就来到了另一种栈——链栈的介绍
什么是链栈了,所谓链栈是栈的另外一种存储方式是链式存储,这样的栈称为链栈(Linked Stack)。链栈通常用单链表来表示,它的实现是单链表的简化。所以,链栈结点的结构与单链表结点的结构一样,如图所示。由于链栈的操作只是在一端进行,为了操作方便,把栈顶设在链表的头部,并且不需要头结点。

链栈结点类(Node<T>)源代码的实现如下:
public class Node<T>
{
private T data; //数据域
private Node<T> next; //引用域
//构造器
public Node(T val, Node<T> p)
{
data = val;
next = p;
}
//构造器
public Node(Node<T> p)
{
next = p;
}
//构造器
public Node(T val)
{
data = val;
next = null;
}
//构造器
public Node()
{
data = default(T);
next = null;
}
//数据域属性
public T Data
{
get
{
return data;
}
set
{
data = value;
}
}
//引用域属性
public Node<T> Next
{
get
{
return next;
}
set
{
next = value;
}
}
}
下图是链栈示意图。

把链栈看作一个泛型类,类名为 LinkStack<T>。LinkStack<T>类中有一个字段 top表示栈顶指示器。由于栈只能访问栈顶的数据元素,而链栈的栈顶指示器又不能指示栈的数据元素的个数。所以,求链栈的长度时,必须把栈中的数据元素一个个出栈, 每出栈一个数据元素, 计数器就增加 1, 但这样会破坏栈的结构。为保留栈中的数据元素, 需把出栈的数据元素先压入另外一个栈, 计算完长度后,再把数据元素压入原来的栈。但这种算法的空间复杂度和时间复杂度都很高,所以, 以上两种算法都不是理想的解决方法。 理想的解决方法是 LinkStack<T>类增设一个字段 num表示链栈中结点的个数。
链栈类 LinkStack<T>的实现说明如下所示。
public class LinkStack<T> : IStack<T> {
private Node<T> top; //栈顶指示器
private int num; //栈中结点的个数
//栈顶指示器属性
public Node<T> Top
{
get
{
return top;
}
set
{
top = value;
}
}
//元素个数属性 进行了计数
public int Num
{
get
{
return num;
}
set
{
num = value;
}
}
//构造器 进行了函数的初始化
public LinkStack()
{
top = null;
num = 0;
}
//求链栈的长度 返回计算的复杂度 此算法的复杂度是O(1)
public int GetLength()
{
return num;
}
//清空链栈 进行清空的操作 此算法的复杂度是O(1)
public void Clear()
{
top = null;
num = 0;
}
//判断链栈是否为空 判断 计数的变量和头指针是否是空 返回为真 否则 为假 此算法的复杂度是O(n)
public bool IsEmpty()
{
if ((top == null) && (num == 0))
{
return true;
}
else
{
return false;
}
}
//入栈 进行栈内 入栈的操作
public void Push(T item)
{
Node<T> q = new Node<T>(item);
if (top == null)
{
top = q;
}
else
{
q.Next = top;
top = q;
}
++num;
}
//出栈 进行出栈的操作 头指针相减。此算法的复杂度为1
public T Pop()
{
if (IsEmpty())
{
Console.WriteLine("Stack is empty!");
return default(T);
}
Node<T> p = top;
top = top.Next;
--num;
return p.Data;
}
//获取栈顶结点的值 返回头指针的值 此算法的复杂度为一。
public T GetTop()
{
if (IsEmpty())
{
Console.WriteLine("Stack is empty!");
return default(T);
}
return top.Data;
}
}
这就是链栈的介绍的。还介绍一个栈的明显的应用,这就是简易万能计算器的应用。
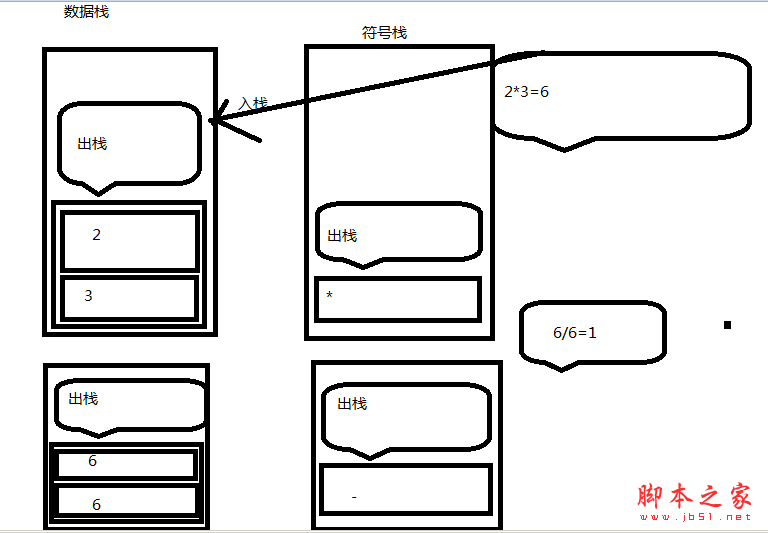
我们都知道在使用算符优先文法时必须使用两个基本栈,数栈(operand stack)和运算符栈(operator stack),来完成计算工作,然而单单使用这两个栈有一定的局限性,因此在设计时,我引入了第三个栈(op stack),下面我们就来分析一下。
在使用两个栈时,如果遇到表达式 2-3*/6#,会发生什么呢?
此时,错误信息为:在minus附近可能存在错误。但实际上问题出在*或/号附近,这种报错的定位结果是不能令人满意的。
于是让我们看看如果引入第三个栈作符号栈会如何?符号栈的功能是保存所有分析过程中的符号,包括数符和运算符两种。
错误定位在/号,错误信息为:在divide附近存在错误。这样将使用户更有可能找到表达式中的问题所在。我们通过每次运算时(对应于SemanticAnalyzer.FakeCalculate()方法),利用了绝对相邻优先级表对符号栈的弹出符号进行相邻性检查,只要发现栈顶的两个符号不能相邻,则马上报错。具体情况,如图所示:
什么是队列,所谓的队列是队列(Queue)是插入操作限定在表的尾部而其它操作限定在表的头部进行的,线性表。把进行插入操作的表尾称为队尾(Rear),把进行其它操作的头部称为队头(Front)。当对列中没有数据元素时称为空对列(Empty Queue)。队列通常记为:Q= (a1,a2,…,an),Q是英文单词queue的第 1 个字母。a1为队头元素,an为队尾元素。这n个元素是按照a1,a2,…,an的次序依次入队的,出对的次序与入队相同,a1第一个出队,an最后一个出队。所以,对列的操作是按照先进先出(First In First Out)或后进后出( Last In Last Out)的原则进行的,这就像 排队买票 ,买完就做。因此,队列又称为FIFO表或LILO表。队列Q的操作示意图如图所示。具体情况,如图所示:

队列的形式化定义为:队列(Queue)简记为 Q,是一个二元组, Q = (D, R) 其中:D 是数据元素的有限集合; 是数据元素之间关系的有限集合。 在实际生活中有许多类似于队列的例子。比如,排队取钱,先来的先取,后来的排在队尾。
同样,我们以 C#语言的泛型接口来表示队列,接口中的方法成员表示基本操作。为了表示的方便与简洁,把泛型队列接口取名为 IQueue<T>(实际上,在C#中泛型队列类是从 IEnumerable<T>、 ICollection 和 IEnumerable 接口继承而来,没有 IQueue<T>泛型接口) 。队列接口 IQueue<T>源代码的定义如下所示。
public interface IQueue<T> {
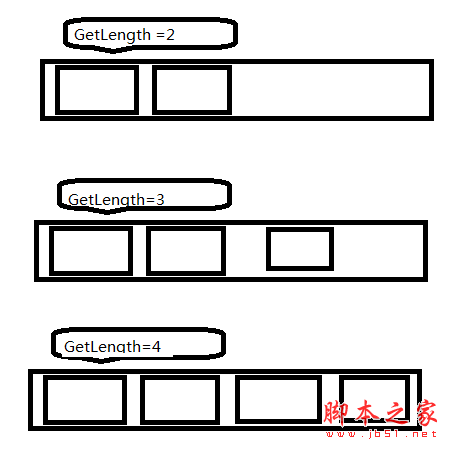
int GetLength(); //求队列的长度;初始条件:队列存在; 操作结果:返回队列中数据元素的个数。一切开始,如图所示:
bool IsEmpty(); //判断对列是否为空;初始条件:队列存在; 操作结果:如果队列为空返回 true,否则返回 false。 一切情况,如图所示:

void Clear(); //清空队列;初始条件:队列存在; 操作结果:使队列为空。
void In(T item); //入队 初始条件:队列存在;操作结果:将值为 item 的新数据元素添加到队尾,队列发生变化.

T Out(); //出队 进行出队的操作 返回头结点 具体情况 如图所示
此算法复杂度是O(1)
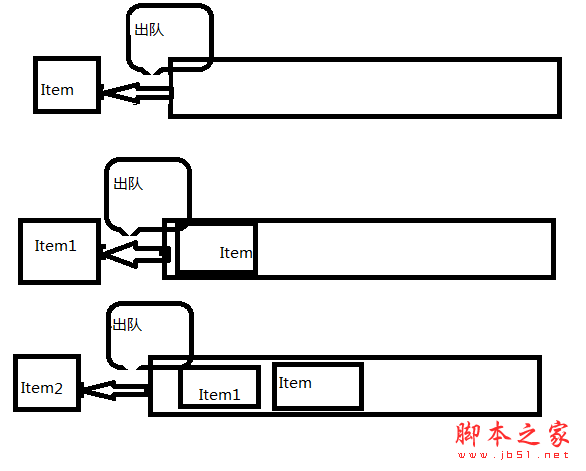
T GetFront(); //取对头元素 取头元素 具体情况 如图所示
此算法的复杂度是O(1)

此算法复杂度是O(1)
}
这就是队列是 基本介绍。
下面我介绍了的队列的应用,我就是在五子棋,用与保存棋谱,悔棋的操作。这就很好的利用了队列先进特点保存了,当你悔棋了,就把棋子的位置拉出来。
这就是队列和栈的介绍。
加载全部内容