通俗易懂DenseNet
shine-lee 人气:1目录
- 写在前面
- Dense Block与Transition Layer
- DenseNet网络架构与性能
- 理解DenseNet
- Plain Net、ResNet与DenseNet
- 参考
博客:博客园 | CSDN | blog
写在前面
在博客《ResNet详解与分析》中,我们谈到ResNet不同层之间的信息流通隐含在“和”中,所以从信息流通的角度看并不彻底,相比ResNet,DenseNet最大的不同之处在于,并不对feature map求element-wise addition,而是通过concatenation将feature map拼接在一起,所以DenseNet中的卷积层知道前面每一步卷积发生了什么。
Crucially, in contrast to ResNets, we never combine features summation before they are passed into a layer; instead, we combine features by concatenating them.
同ResNet结构类似,DenseNet也是由多个Dense Block串联而成,如下图所示
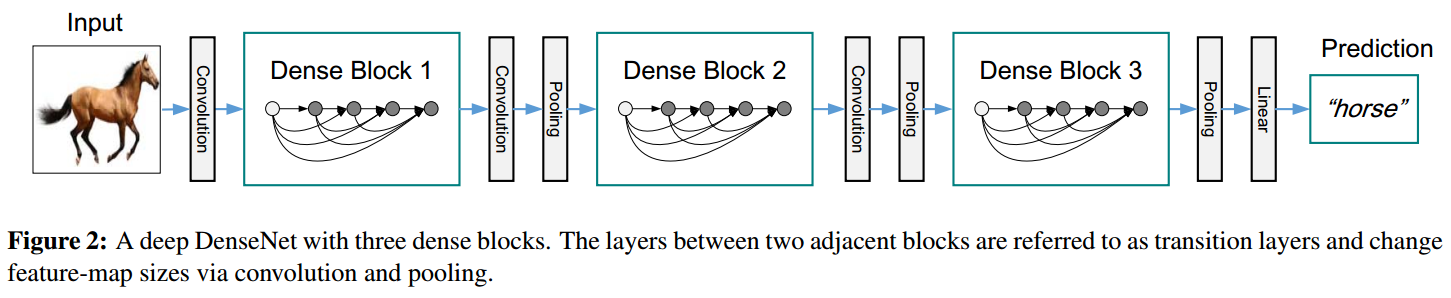
Dense Block与Transition Layer
在每个Dense Block内部,每个卷积层可以知道前面所有卷积层输出的feature map是什么,因为它的输入为前面所有卷积层输出的feature map拼接而成,换个角度说,每个卷积层得到的feature map要输出给它后面所有的卷积层。这里说“每个卷积层”并不准确,更准确的说法应该是“每组卷积”,后面将看到,一组卷积是由1个\(1\times 1\)卷积层和 1个\(3\times 3\)卷积层堆叠而成,即bottleneck结构。
to ensure maximum information flow between layers in the network, we connect all layers (with matching feature-map sizes) directly with each other. To preserve the feed-forward nature, each layer obtains additional inputs from all preceding layers and passes on its own feature-maps to all subsequent layers.
下面看一个Dense Block的示例,
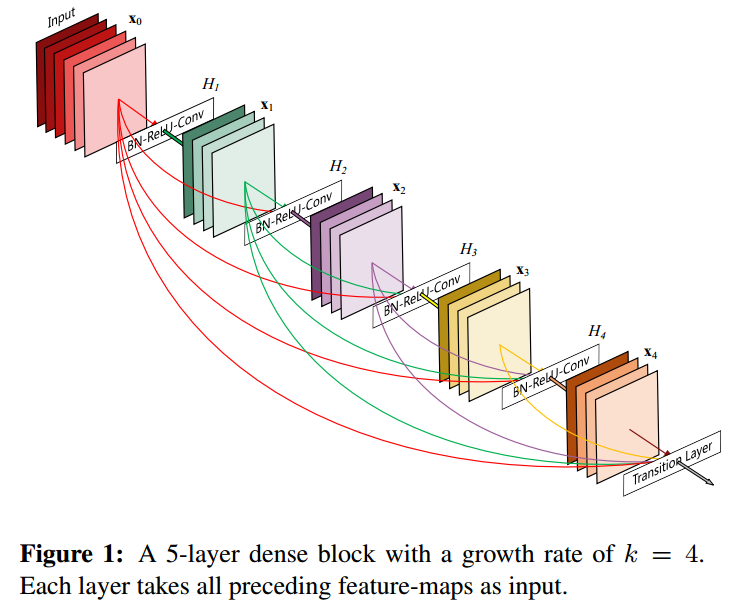
图中的\(x\)为feature map,特别地,\(x_0\)为网络输入,\(H\)为一组卷积,同Identity Mappings in Deep Residual Networks采用了pre activation方式,即BN-ReLU-\(1\times 1\)Conv-BN-ReLU-\(3\times 3\)Conv的bottleneck结构。\(x_i\)为\(H_i\)输出的feature map,\(H_i\)的输入为concatenation of \([x_0, x_1, \dots, x_{i-1}]\)。定义每个\(H\)输出的 channel数为growth rate \(k =4\),则\(H_i\)的输入feature map有 \(k_0 + k\times (i-1)\)个channel,特别地,\(k_0\)为\(x_0\)的channel数。所以,对于越靠后的\(H\),其输入feature map的channel越多,为了控制计算复杂度,将bottleneck中\(1\times 1\)卷积的输出channel数固定为\(4k\)。对于DenseNet的所有 Dense Block,growth rate均相同。
相邻Dense Block 之间通过Transition Layer衔接,Transition Layer由1个\(1\times 1\)卷积和\(2\times 2\)的average pooling构成,前者将输入feature map的channel数压缩一半,后者将feature map的长宽尺寸缩小一半。
可见,bottleneck和Transition Layer的作用都是为了提高计算效率以及压缩参数量。
DenseNet网络架构与性能
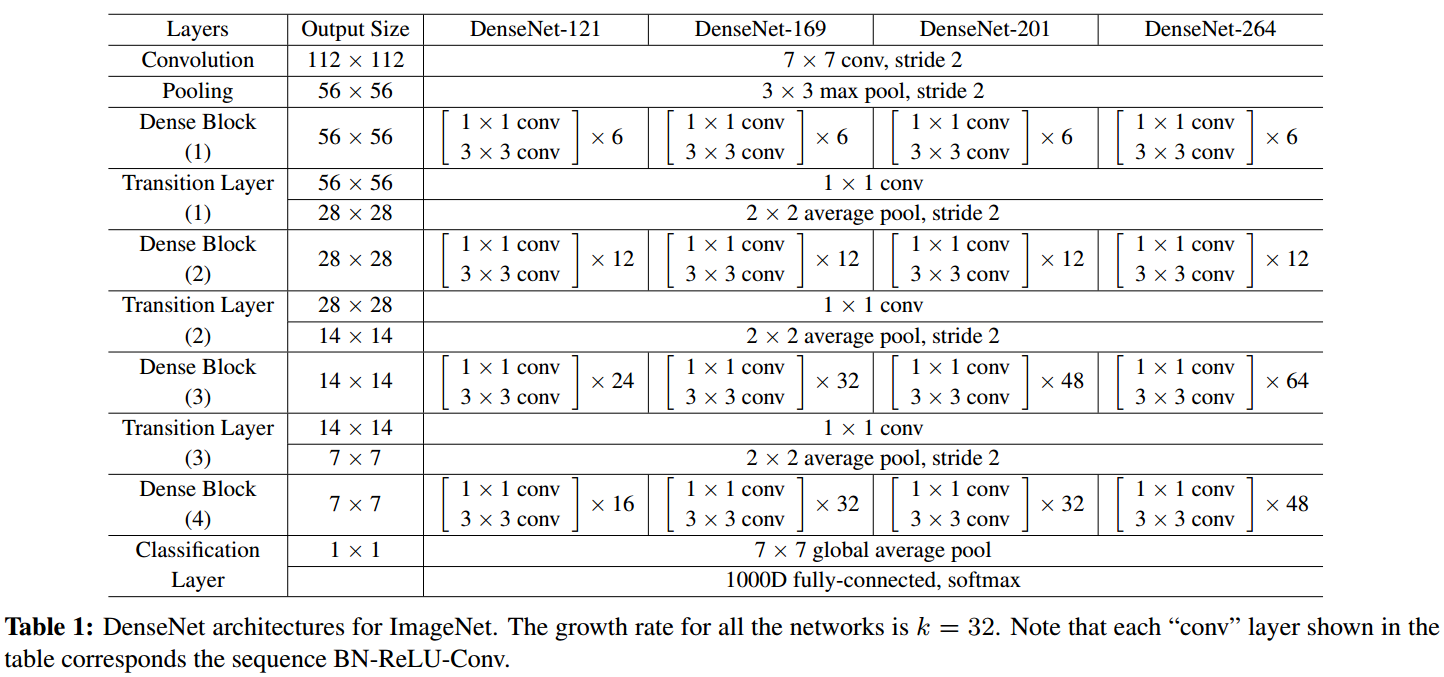
DenseNet用于ImageNet的网络架构如下,通过上面的介绍,这里的架构不难理解。
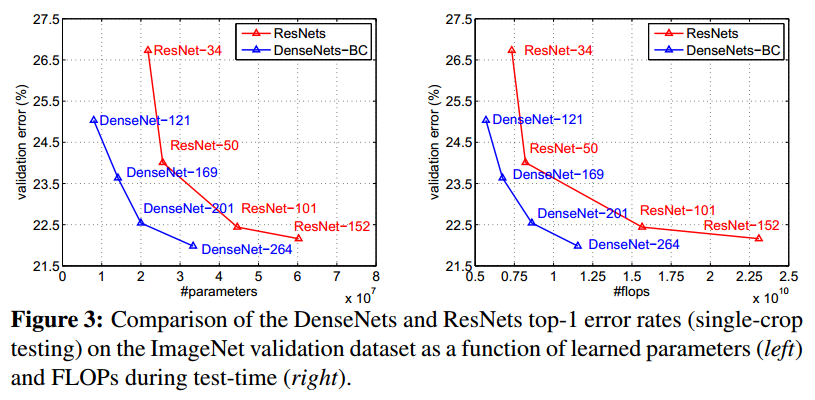
DenseNet的Parameter Efficiency很高,可以用少得多的参数和计算复杂度,取得与ResNet相当的性能,如下图所示。
理解DenseNet
DenseNet最终的输出为前面各层输出的拼接,在反向传播时,这种连接方式可以将最终损失直接回传到前面的各个隐藏层,相当于某种Implicit Deep Supervision,强迫各个隐藏层学习到更有区分里的特征。
DenseNet对feature map的使用方式可以看成是某种多尺度特征融合,文中称之为feature reuse,也可以看成是某种“延迟决定”,综合前面各环节得到的信息再决定当前层的行为。文中可视化了同block内每层对前面层的依赖程度,
For each convolutional layer ‘ within a block, we compute the average (absolute) weight assigned to connections with layers. Figure 5 shows a heat-map for all three dense blocks. The average absolute
weight serves as a surrogate for the dependency of a convolutional layer on its preceding layers.
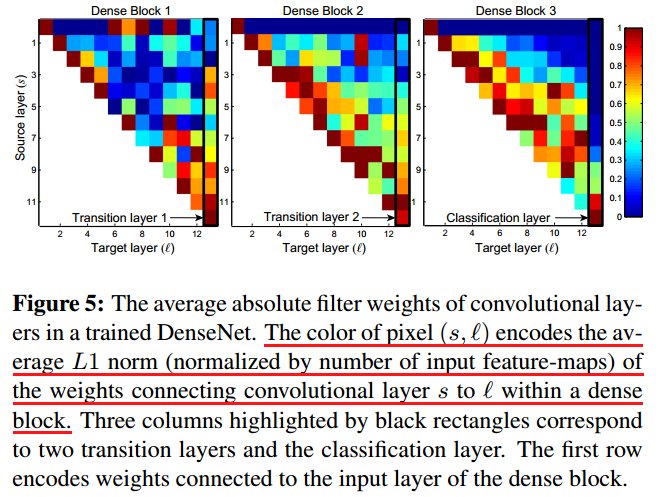
图中可见每个Dense Block中每层对前面层的依赖程度,约接近红色表示依赖程度越高,可以看到,
- Dense Block内,每个层对其前面的feature map利用方式(依赖程度)是不一样的,相当于某种“注意力”
- Transition Layer 以及最后的Classification Layer对其前面相对宏观的特征依赖较高,这种趋势越深越明显
Plain Net、ResNet与DenseNet
这里做一个可能并不恰当的比喻,对比一下Plain Net、ResNet 与 DenseNet。
如果将网络的行为比喻成作画,已知最终希望画成的样子,但要经过N个人之手,每个人绘画能力有限,前面一个人画完交给后面的人。
Plain Net:前面一个人画完,后面一个人只能参照前一个人画的自己重新绘制一张,尽管他能力有限,但他必须得画。
ResNet:前面一个人画完,后面一个人在其基础上作画,他更多地关注当前画与最终画的差异部分,同时他还有不画的权利。
DenseNet:当前作画的人可以看到前面所有人的画,同时他还知道大家绘画的顺序以及谁的画工相对更好更可靠,他参照前面所有的画自己重新绘制一张,然后连同前面所有的画一同交给后面的人。
不难看出,ResNet和DenseNet的侧重点不太一样,但大概率应该都比Plain Net画的更好。
所以,要是综合ResNet和DenseNet的能力是不是会画得更好呢?
以上。
参考
- paper: Densely Connected Convolutional Networks
- code: pytorch-densenet.py
- Densely Connected Networks (DenseNet)
加载全部内容