为什么一个星期工作量的工作,我做了一个多月,还没结束
秋荷雨翔 人气:0为什么一个星期工作量的工作,我做了一个多月,还没结束
为什么一个星期工作量的代码,我写了一个多月,还在写
这是一个HIK平台WIFI数据接入的工作,先看下我的代码提交记录:
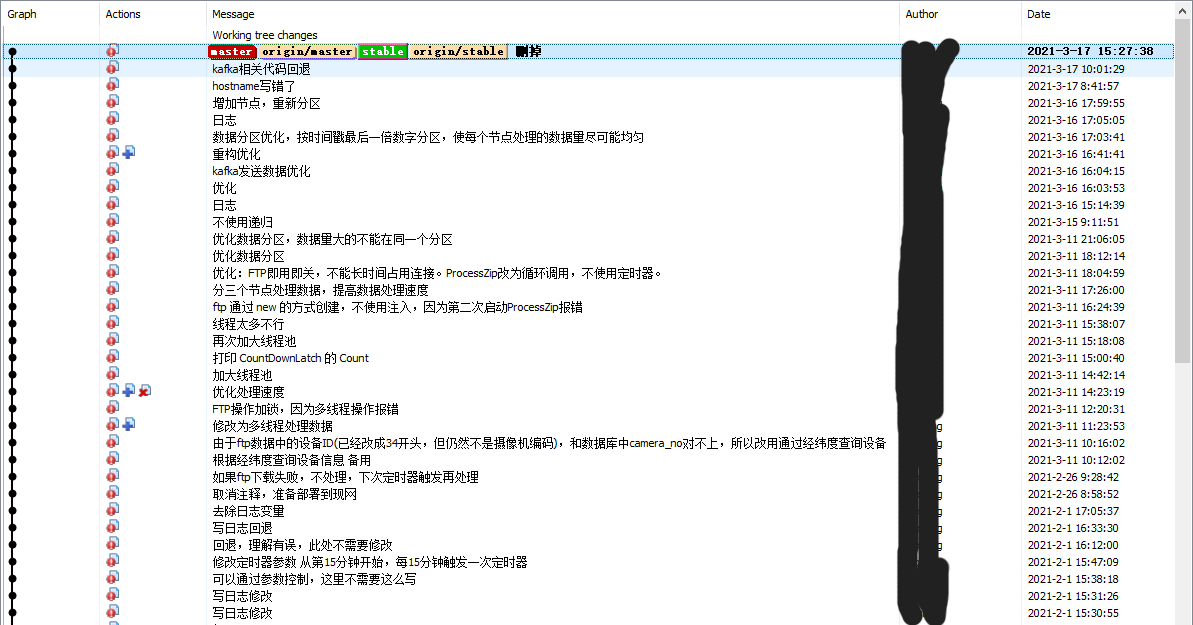

首先有这两方面的原因:1、初学Java时间不长,不够熟练,这个原因浪费的时间并不多。2、与数据提供方沟通浪费的时间,因数据有问题,即DeviceId和数据库中的DeviceId对不上,导致程序筛选不到数据,需要对方修改相关配置,由于我感觉事情并不急,所以是隔几天催一下,浪费了不少天的时间,最后DeviceId依然对不上,我是怎么解决的呢?由于基本上是一个设备布在一个地点,所以我是根据数据中的经纬度来筛选数据的,这种办法其实还是有一点点问题的。
再说写代码花费的时间,服务部署到现网后,就开始发现BUG了,程序处理数据的速度不够,导致FTP上的ZIP包处理不完大量积压,因为我用的是单线程处理数据,遂改成多线程处理数据。
经过优化和测试,发现数据处理速度还是不够,FTP上数据产生的速度大约是380条每秒,可能会更多,而单机每秒最多只能处理200多条数据,继续尝试优化,但还是不行。所以我面临第一个重要问题:把程序部署到多台机器,提高数据处理速度,程序该怎么写?
对于这个问题,经过探索,我最终的解决办法是:把程序部署在5台机器上,程序跑起来后,能拿到机器名称,FTP上的ZIP文件名带有时间戳,根据机器名和时间戳的最后一位,把ZIP文件分配到5台机器处理,这样就解决了数据处理速度不够的问题。
我想解决的第二个重要问题是:由于我目前做的是大数据维护,学了点Spark和Flink知识,所以我想用Spark改写,已经写好的程序是SpringBoot的,所以我要做的是SpringBoot整合Spark。周末我在家搭了一个Hadoop+Spark的分布式集群环境,写了个纯Spark的Demo跑,正常。然后写了个SpringBoot整合Spark的Demo,本地模式跑,即.setMaster("local[3]"),正常。但是提交到集群跑,web api和swagger在线文档正常,任务跑起来后在Spark Web页面可以看到,但日志报错。我试了3种方式,一种是打war包部署在tomcat里,一种是用命令java -jar运行jar包,一种是用spark-submit命令运行jar包,任务跑起来后都报错了,三种方式错误也不相同,搞到凌晨4点多,没有解决,放弃。不过,就算我成功了,接下来的问题,可能依然无法解决,就是数据处理完后,要推送到Kafka,网上的教学都是教Spark怎么处理Kafka流数据,Kafka数据是作为数据源的,不是作为目的地的,所以我的想法可能本身就是个问题。
解释一下为什么要SpringBoot整合Spark,只用Spark不用SpringBoot不行吗?实际上之前同事就是这么干的,要么用SpringBoot,要么用Spark或Flink,没有把SpringBoot和二者在一起用过,为什么我要这么做?因为我要读mysql数据库,我要用JDBC或者Mybatis等,如果不用SpringBoot,有些东西可能要自己搞,不太方便。
既然SpringBoot整合Spark没有成功,那数据分配不均匀的问题怎么解决(FTP上ZIP文件5分种产生5个文件,2个数据量大,3个不是我需要的数据可以直接删了,但不管是按时间戳这个特征分配,还是按序号这个特征分配,都无法均匀分配,可能会导致一个节点数据积压,另外3个节点没有要处理的数据,即一个节点有难,3个节点围观,虽然时间尺度拉大后,数据分配是均匀的,但是数据处理延迟大了,5分钟产生一个ZIP文件,意味着,有的数据已经延迟处理了5分钟,而我这边还要延迟几分钟到几十分钟不等)?这是我准备解决的第三个重要问题。
我用Socket解决了这个问题,我把程序部署在5个节点上,一个作为master节点,4个作为worker节点,程序启动后根据机器名判断,确定master节点,master节点从FTP上下载ZIP文件,FTP上ZIP文件可能很多,先只下载一个文件进行处理,一个文件中可能有多达10万条数据,也可能就几万条数据,还可能不是我需要的数据,直接删掉该ZIP文件即可,然后解析数据,再然后把数据集合平均分成4份,通过Socket发送给4个worker节点,worker节点收到数据集合,进行筛选和处理,然后推送到Kafka,数据处理完后,给master节点发送一条消息,可以重复发送几次,再加上是局域网,以确保master节点能收到消息(这个很重要,但这里也有问题),master节点收到4个节点数据处理完成的消息后,删除FTP上的该ZIP文件。然后进行下一次处理,直到FTP上的ZIP文件全部处理完成并删除。我今天写完后,把写ES日志和发Kafka以及删除ZIP文件的代码注释掉,耗时的地方用Thread.sleep代替,部署到真实环境,看能不能稳定跑上一天。我感觉用Socket实现分布式数据处理,虽然能解决数据分配不均匀的问题,但是程序稳定性变差了,如果master节点收不到worker节点发来的数据处理完成的消息怎么办?假设其中一个worker节点的程序挂掉了呢?
虽然只是一个简单的小任务,我真的是非常努力,如果我最初的设想成功,以后的类似服务都可以这么写,意义重大,可惜没搞成功,退而求其次,用Socket写分布式处理程序,我好像迷迷糊糊明白为什么Spark要依赖Hadoop了,我自己用Socket写漏洞很多啊,没有把数据持久化,万一漰了,数据就丢了。
有没有大佬给指点一下,我努力的思路是不是有问题,有没有代码又容易写,又不容易写错,程序又稳定可靠的方案?
加载全部内容