Spark Streaming运行流程及源码解析(一)
upupfeng 人气:2本系列主要描述Spark Streaming的运行流程,然后对每个流程的源码分别进行解析
之前总听同事说Spark源码有多么棒,咱也不知道,就是疯狂点头。今天也来撸一下Spark源码。
对Spark的使用也就是Spark Streaming使用的多一点,所以就拿Spark Streaming开涮。

源码中的一些类
这里先列举一些源码中的类,大家先预热一下。
StreamingContext:这是Spark Streaming程序的入口,提供了运行时上下文环境
DStream:是RDD在Spark Streaming中的实现,是连续的RDD(相同类型)序列,表示连续的数据流
JobScheduler:生成和调度job
DStreamGraph:保存DStream之间的依赖关系
JobGenerator:根据DStream依赖生成job
ReceiverTracker:Driver端用于管理ReceiverInputDStreams执行的管家
EventLoop:一个事件循环,用于接收来自调用方的事件并处理事件线程中的所有事件。它将启动一个专用事件线程来处理所有事件。内部使用LinkedBlockingDeque实现。
RecurringTimer:相当于一个定时器,定时执行某个函数
ReceiverSupervisor:Executor端管理Receiver的管家
Receiver:在Executor节点上运行以接收外部数据。
InputDStream:接收外部数据
ReceiverInputDStream:用于定义必须在工作节点上启动接收器以接收外部数据的类,可以通过它获得Receiver
BlockGenerator:根据时间间隔将接收到的数据生成块
RpcEndpoint:RPC终端点,Spark Streaming中使用Netty进行RPC通信
ReceiverTrackerEndpoint:Driver端的ReceiverTracker终端,用于和Receiver通信
运行流程
Spark Streaming运行时由Driver和Executor相互协调完成。
Driver端创建StreamingContext,其中包含了DStreamGraph和JobScheduler(它又包括了ReceiverTracker和JobGenerator),Driver主要负责生成调度job、与execuor进行交互、指导工作。
Eexcutor主要有ReceiverSupervisor、Receiver、BlockManager、BlockGenerator,Executor负责数据的接收和存储、任务的执行。
以下是Spark Streaming运行架构图,可以先大致看一下,等待会看完运行流程再回来看一遍。
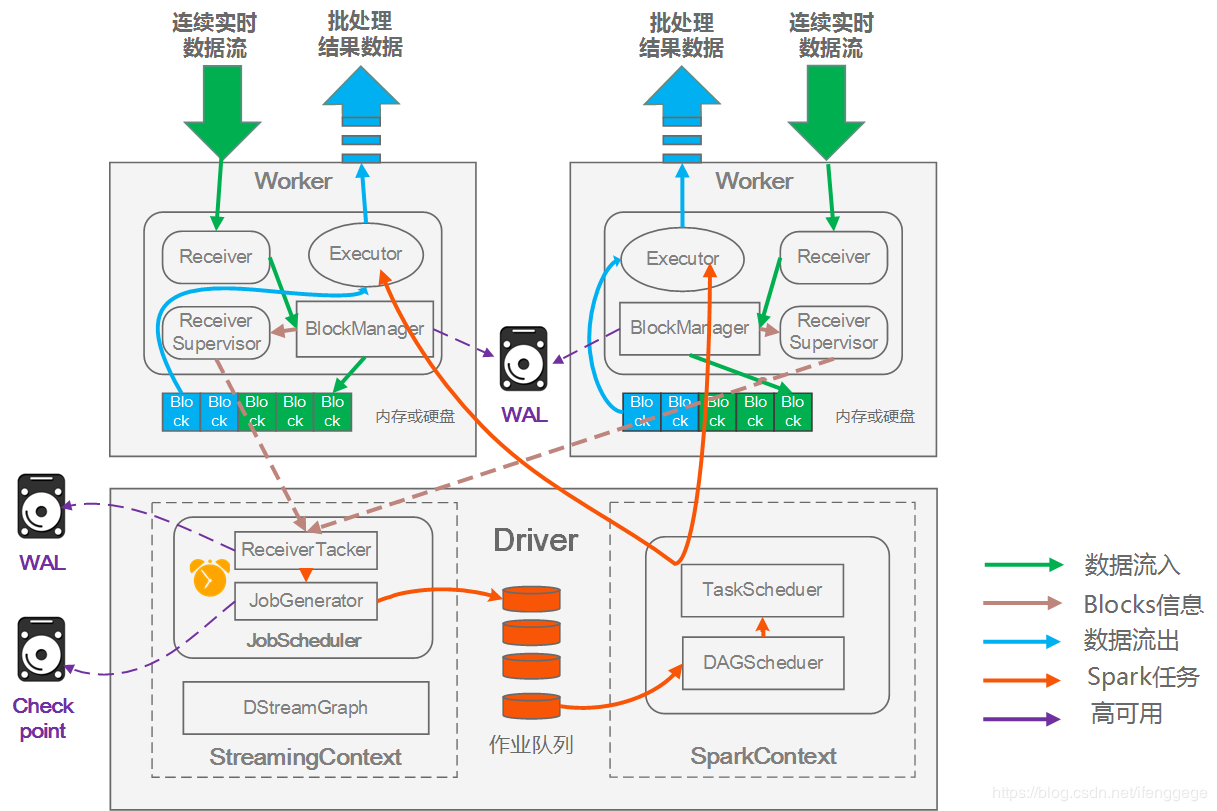
从接收数据到处理完成具体可划分为以下四步:
启动流处理引擎
创建并启动StreamingContext对象,其中维护了DStreamGraph和JobScheduler实例。
DStreamGraph用来定义DStream,并管理他们的依赖关系。
JobScheduler用来生成和调度job,其中维护了ReceiverTracker和JobGenerator实例。
ReceiverTracker是Driver端的Receiver管理者,负责在Executor中启动ReceiverSupervisor并与之通信,ReceiverSupervisor会启动Receiver进行接收消息。
JobGenerator用来生成Job。
每个实例都各司其职,在启动时都会调用其start方法,开始运转。
接收并存储数据
Executor端的Receiver启动后不断的接收消息,并调用其store()方法将数据存储。
store方法最终会调用ReceiverSupervisorImpl.pushAndReportBlock()将数据进行存储,并汇报给Driver端的ReceiverTrackerEndpoint。
这里有一个重要的类:BlockGenerator,其使用ArrayBuffer对接收到的单条数据进行暂存。
BlockGenerator还有一个定时器,按批处理间隔定时将ArrayBuffer中的数据封装为Block,并将Block存到一个ArrayBlockingQueue队列中。
BlockGenerator中还启动了一个线程从ArrayBlockingQueue中取出Block,调用ReceiverSupervisorImpl.pushAndReportBlock()进行存储,并与Driver端汇报。
处理数据
处理数据就是生成job、执行job。
首先在JobGenerator中维护了一个定时器,每当批处理间隔到达时,发起GenerateJobs指令,调用generateJobs生成&执行job。
generateJobs方法中会让ReceiverTracker分配本批次对应的数据,然后让DStreamGraph根据DStream的依赖生成job;job生成成功的话会调用submitJobSet提交执行job,然后执行job。
我们编写的业务处理代理代码,会在生成job时作为参数参进去。
输出数据
job执行后会根据我们写的代码执行输出。
end...
至此,就大致梳理了一下整体流程。
接下来再详细的撸一下每一步的源码。
Spark Streaming源码运行流程解析
reference
《图解Spark核心技术与案例实战》,首先推荐一下这本书,对于理解Spark有很大帮助。
https://www.cppentry.com/bencandy.php?fid=116&id=209107,这个是Spark Streaming源码解析的系列文章,讲的也很清晰
http:/https://img.qb5200.com/download-x/ddrv.cn/a/250847 Spark Streaming运行架构图来源

个人公众号:码农峰,定时推送行业资讯,持续发布原创技术文章,欢迎大家关注。
加载全部内容