原文来自我的个人网站:http://www.itrensheng.com/archives/Spark_basic_knowledge
一. Spark出现的背景
在Spark出现之前,大数据计算引擎主要是MapReduce。HDFS + MapReduce的组合几乎可以实现所有的大数据应用场景。MR框架抽象程度比较高,需要我们编写Map和Reduce两个步骤(MapReduce 框架其实包含5 个步骤:Map、Sort、Combine、Shuffle以及Reduce)
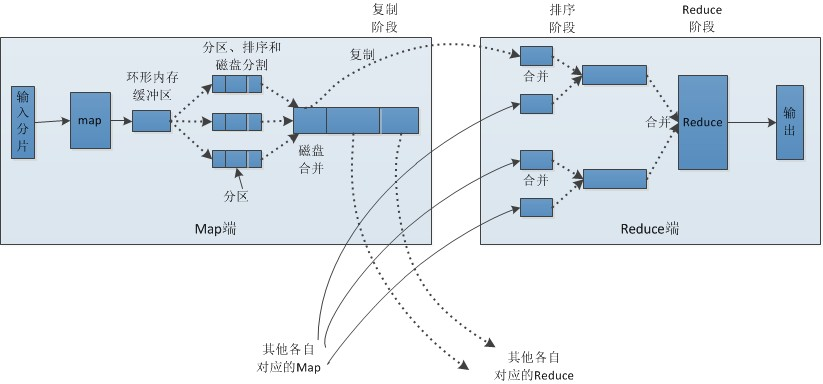
每个Map和Reduce之间需要进行Shuffle(这步操作会涉及数量巨大的网络传输,需要耗费大量的时间)。由于 MapReduce 的框架限制,一个 MapReduce 任务只能包含一次 Map 和一次 Reduce,计算完成之后,MapReduce会将运算中间结果写回到磁盘中,供下次计算使用。
二.Spark简介
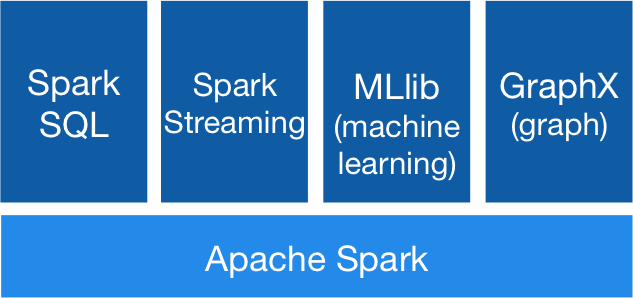
Spark是由加州大学伯克利分校AMP实验室开源的分布式大规模数据处理通用引擎,具有高吞吐、低延时、通用易扩展、高容错等特点。Spark内部提供了丰富的开发库,集成了数据分析引擎Spark SQL、图计算框架GraphX、机器学习库MLlib、流计算引擎Spark Streaming
相比于MapReduce的计算模型,Spark是将数据一直缓存在内存中,直到计算得到最后的结果,再将结果写入到磁盘,所以多次运算的情况下,Spark省略了多次磁盘IO。
| 对比 | MapReduce | Spark |
|---|---|---|
| 速度 | 处理数据需要连续的读写磁盘 | 是MapReduce的10到100倍 |
| 编码难度 | 程序员来赋值每一步 | RDD高可用,失败重试 |
| 及时性 | 不适合做OLAP,只适合批处理 | 能兼顾批处理和OLAP |
| 调度 | 使用外部的调度,如Oozie | 自带调度,也可使用外部调度 |
| 编程语言 | Java | Scala |
| SQL支持 | 本身不提供,需要外部查询引擎,如Hive | 自带Spark SQL |
| 可扩展性 | 最大支持14000个节点 | 最大8000节点 |
| 机器学习 | 外部依赖Mahout | 自带Spark MLlib |
| 缓存 | 能不缓存到内存中 | 可以缓存到内存中 |
| 安全性 | 安全特性比Spark广泛 | 不如MapReduce |
三. Spark系统架构
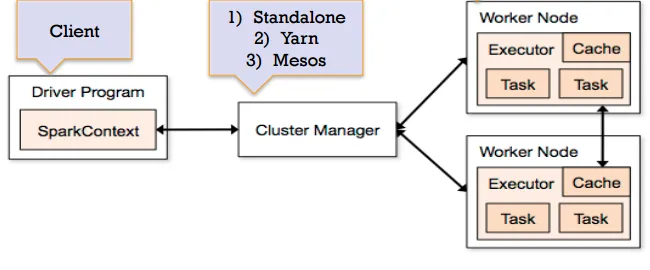
Driver:
一个Spark job运行前会启动一个Driver进程,也就是作业的主进程,负责解析和生成各个Stage,并调度Task到Executor上
SparkContext:
程序运行调度的核心,高层调度去DAGScheduler划分程序的每个阶段,底层调度器TaskScheduler划分每个阶段具体任务
Worker:
也就是WorkderNode,负责执行Master所发送的指令,来具体分配资源并执行任务
Executer:
负责执行作业。如图中所以,Executer是分步在各个Worker Node上,接收来自Driver的命令并加载Task
DAGScheduler:
负责高层调度,划分stage并生产DAG有向无环图
TaskScheduler:
负责具体stage内部的底层调度,具体task的调度和容错
Job:
每次Action都会触发一次Job,一个Job可能包含一个或多个stage
Stage:
用来计算中间结果的Tasksets。分为ShuffleMapStage和ResultStage,出了最后一个Stage是ResultStage外,其他都是ShuffleMapStage。ShuffleMapStage会产生中间结果,是以文件的方式保存在集群当中,以便能够在不同stage种重用
Task:
任务执行的工作单位,每个Task会被发送到一个节点上,每个Task对应RDD的一个partition.
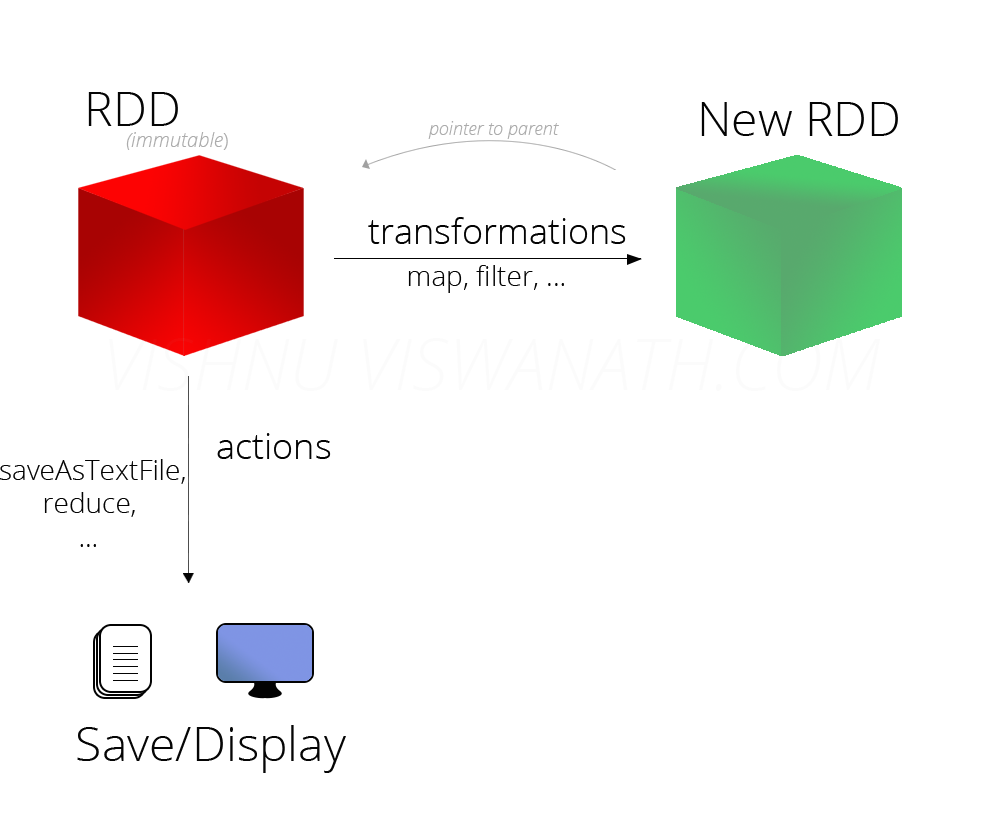
RDD:
是以partition分片的不可变,Lazy级别数据集合 算子
Transformation:
由DAGScheduler划分到pipeline中,是Lazy级别的,不会触发任务的执行
Action:
会触发Job来执行pipeline中的运算
四. Spark Job执行流程

spark = SparkSession\
.builder\
.appName("PythonWordCount")\
.getOrCreate()
lines = spark.read.text(sys.argv[1]).rdd.map(lambda r: r[0])
counts = lines.flatMap(lambda x: x.split(' ')) \
.map(lambda x: (x, 1)) \
.reduceByKey(add)
output = counts.collect()
for (word, count) in output:
print("%s: %i" % (word, count))
spark.stop()
- 使用spark-submit向集群提交一个job之后,就会启动一个Driver进程。Driver进程会根据deploy-mode不同而不同,可能是本地启动,也可能是集群中的节点
- Driver进程向资源管理器Resource Manager(可以是Standalone、Mesos或YARN)注册并申请运行Executor资源,如YARN会根据spark-submit中申请的参数来为Spark作业设置对应的资源参数,并在集群中的各个节点上分配对应数量的Executor进程
- Driver进程会将整个Job拆分为多个Stage,一个Stage可能包含多个Task,并将这些Task分配到第二步中申请到的Executor进程中执行。Task是执行的最小Unit。当一个Stage所属的所有Task都执行完成之后,会在各个节点的磁盘文件中记录中间结果并继续执行后续的Stage。
四. RDD
定义:
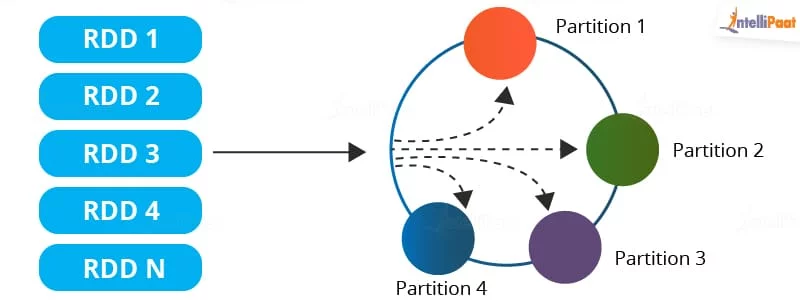
RDD 是 Spark 的计算模型。RDD(Resilient Distributed Dataset)叫做弹性的分布式数据集合,是 Spark中最基本的数据抽象,它代表一个不可变、只读的,被分区的数据集。
可以将 RDD 理解为一个分布式对象集合,本质上是一个只读的分区记录集合。每个 RDD可以分成多个分区,每个分区就是一个数据集片段。一个 RDD 的不同分区可以保存到集群中的不同结点上,从而可以在集群中的不同结点上进行并行计算。
五大特性:
-
分区列表:RDD是分区的,且每一个分区都会被一个Task所处理,所以Job的并行执行能力取决于分区多少。默认情况下,RDD的分区数是集成自父RDD,这个值也可以在创建RDD的时候在代码中指定
-
计算函数:每个分区都有一个计算函数,这个计算函数是以分片为基本单位的。如在RDD的宽依赖场景下,将宽依赖划分为Stage,而Stage使用BlockManager获取分区数据并根据计算函数来split对应的Block
-
存在依赖关系:RDD经过计算任务每次都会转化为一个不可变的新的RDD。因为有依赖关系,所以当前一个RDD失败的时候,Spark会根据依赖关系重新计算前一个失败的RDD,而不是所有的RDD。
-
KV数据类型分区器:控制分区策略和分区数,每个KV形式的RDD都有Partitioner属性,来控制RDD如何分区。
5.优先位置列表:每个分区都有优先位置列表,用于存储Partition的优先位置。如果是读取HDFS,那就是每个Block的优先位置。
RDD的依赖关系
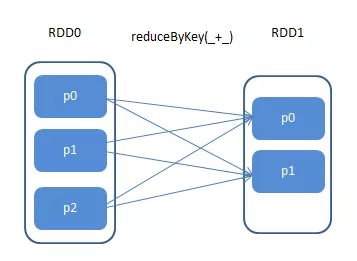
依赖关系分为宽依赖(Wide Dependency)和窄依赖(Narraw Dependency)。
-
宽依赖:子RDD分区依赖父RDD的所有分区。如果子RDD部分分区甚至全部分区数据损坏或丢失,需要从所有父RDD重新计算,相对窄依赖而言付出的代价更高,所以应尽量避免宽依赖的使用
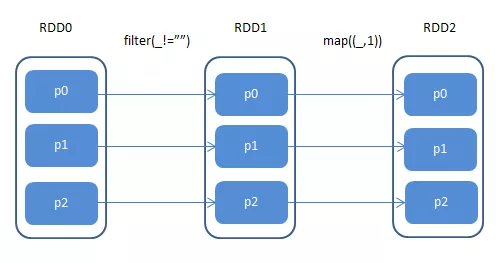
-
窄依赖:父RDD的分区只对应一个子RDD的分区。如果子RDD只有部分分区数据损坏或者丢失,只需要从对应的父RDD重新计算恢复如果子RDD只有部分分区数据损坏或者丢失,只需要从对应的父RDD重新计算恢复
类型
RDD可以分为2中类型:Transformation 和 Action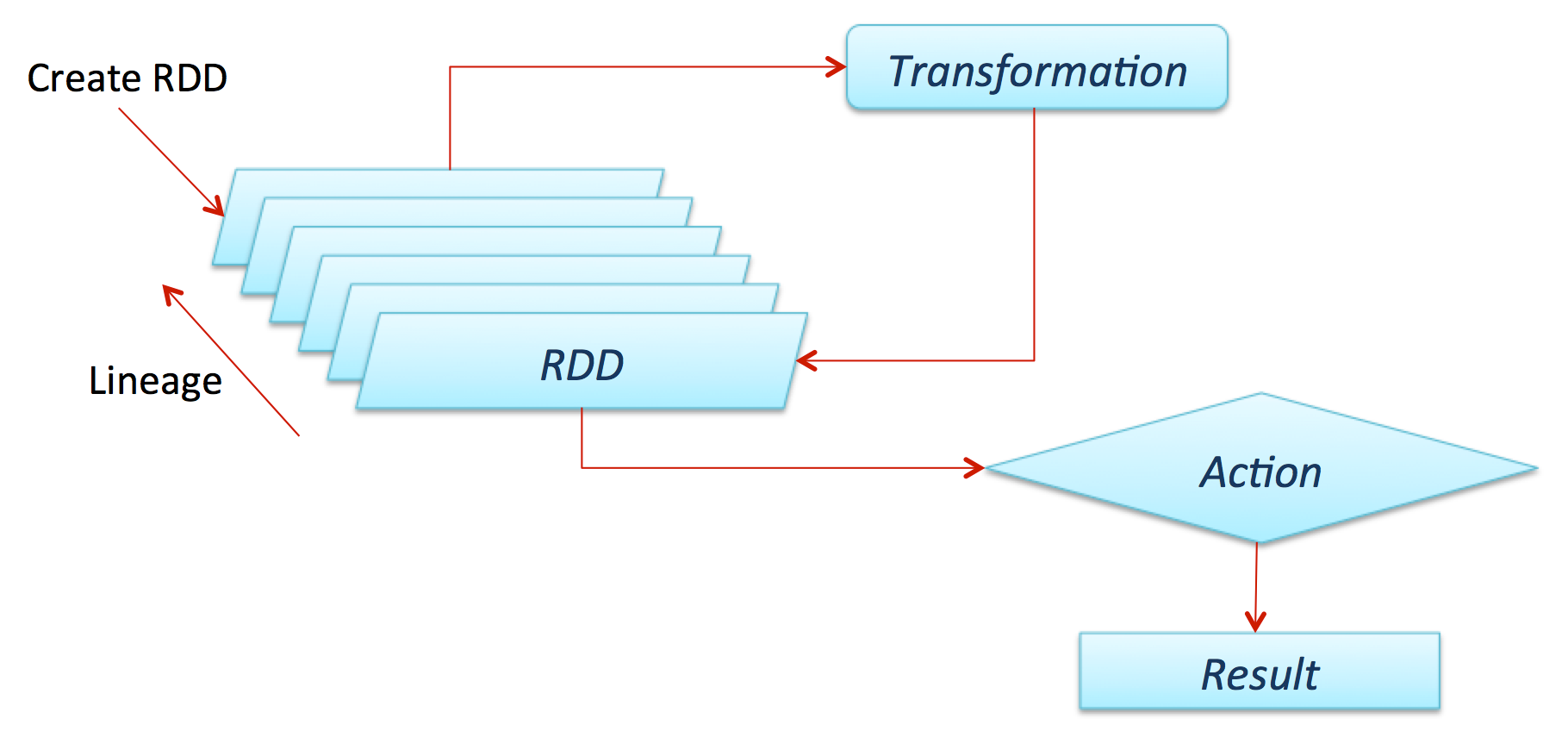
Transformation 操作不是马上提交 Spark 集群执行的,Spark 在遇到 Transformation操作时只会记录需要这样的操作,并不会去执行,需要等到有 Action 操作的时候才会真正启动计算过程进行计算.
针对每个 Action,Spark 会生成一个 Job,从数据的创建开始,经过 Transformation, 结尾是 Action 操作.这些操作对应形成一个有向无环图(DAG),形成 DAG 的先决条件是最后的函数操作是一个Action
五. 缓存
Spark 本身就是一个基于内存的迭代式计算,当某个RDD的计算结果会被多次重复使用的时候,缓存就很有必要(尤其是对于整个血统很长的计算任务)。如果程序从头到尾只有一个 Action 操作且子RDD只依赖于一个父RDD 的话,就不需要使用 cache 这个机制。
Spark 可以使用 persist 和 cache 方法将任意 RDD 缓存到内存、磁盘文件系统中。缓存是容错的,如果一个 RDD 分片丢失,则可以通过构建它的转换来自动重构。被缓存的 RDD 被使用时,存取速度会被大大加速。一般情况下,Executor 内存的 60% 会分配给 cache,剩下的 40% 用来执行任务
-
MEMORY_ONLY: 使用未序列化的Java对象格式,将数据保存在内存中。如果内存不够存放所有的数据,则某些分区的数据就不会进行持久化。那么下次对这个RDD执行算子操作时,那些没有被持久化的数据,需要从源头处重新计算一遍。这是默认的持久化策略,使用cache()方法时,实际就是使用的这种持久化策略。
-
MEMORY_ONLY_SER: 基本含义同MEMORY_ONLY。唯一的区别是,会将RDD中的数据进行序列化,RDD的每个partition会被序列化成一个字节数组。这种方式更加节省内存,从而可以避免持久化的数据占用过多内存导致频繁GC。
-
MYMORY_AND_DISK: 使用未序列化的Java对象格式,优先尝试将数据保存在内存中。如果内存不够存放所有的数据,会将数据写入磁盘文件中,下次对这个RDD执行算子时,持久化在磁盘文件中的数据会被读取出来使用。
-
MEMORY_AND_DISK_SER: 基本含义同MEMORY_AND_DISK。唯一的区别是,会将RDD中的数据进行序列化,RDD的每个partition会被序列化成一个字节数组。这种方式更加节省内存,从而可以避免持久化的数据占用过多内存导致频繁GC。
-
DISK_ONLY: 使用未序列化的Java对象格式,将数据全部写入磁盘文件中。
-
MEMORY_ONLY_2/MEMORY_AND_DISK_2: 对于上述任意一种持久化策略,如果加上后缀_2,代表的是将每个持久化的数据,都复制一份副本,并将副本保存到其他节点上。这种基于副本的持久化机制主要用于进行容错。假如某个节点挂掉,节点的内存或磁盘中的持久化数据丢失了,那么后续对RDD计算时还可以使用该数据在其他节点上的副本。如果没有副本的话,就只能将这些数据从源头处重新计算一遍了。
-
OFF_HEAP(experimental) : RDD的数据序例化之后存储至Tachyon。相比于MEMORY_ONLY_SER,OFF_HEAP能够减少垃圾回收开销、使得Spark Executor更“小”更“轻”的同时可以共享内存;而且数据存储于Tachyon中,Spark集群节点故障并不会造成数据丢失,因此这种方式在“大”内存或多并发应用的场景下是很有吸引力的。需要注意的是,Tachyon并不直接包含于Spark的体系之内,需要选择合适的版本进行部署;它的数据是以“块”为单位进行管理的,这些块可以根据一定的算法被丢弃,且不会被重建。
