托管对象本质-第二部分-对象头布局和锁成本
杰哥很忙 人气:4目录
- 托管对象本质-第二部分-对象头布局和锁成本
- 目录
- 轻量锁、锁膨胀和对象头布局
- 结论
托管对象本质-第二部分-对象头布局和锁成本
原文地址:https:/https://img.qb5200.com/download-x/devblogs.microsoft.com/premier-developer/managed-object-internals-part-2-object-header-layout-and-the-cost-of-locking/
原文作者:Sergey
译文作者:杰哥很忙
目录
托管对象本质1-布局
托管对象本质2-对象头布局和锁成本
托管对象本质3-托管数组结构
托管对象本质4-字段布局
我从事当前项目时遇到了一个非常有趣的情况。对于给定类型的每个对象,我必须创建一个始终增长的标识符,但需要注意:
1) 该解决方案可以在多线程环境中工作
2) 对象的数量相当大,多达千万。
3) 标识应该按需创建,因为不是每个对象都需要它。
在最初的实现过程中,我还没有意识到应用程序将处理的数量,因此我提出了一个非常简单的解决方案:
public class Node
{
public const int InvalidId = -1;
private static int s_idCounter;
private int m_id;
public int Id
{
get
{
if (m_id == InvalidId)
{
lock (this)
{
if (m_id == InvalidId)
{
m_id = Interlocked.Increment(ref s_idCounter);
}
}
}
return m_id;
}
}
}代码使用双重检查的锁模式,允许在多线程环境中初始化标识字段。在其中一个分析会话中,我注意到具有有效 ID 的对象数量达到数百万个实例,主要令我惊讶的是,它并没有在性能方面引起任何问题。
之后,我创建了一个基准测试,以查看与无锁定方法相比,锁语句在性能方面的影响。
public class NoLockNode
{
public const int InvalidId = -1;
private static int s_idCounter;
private int m_id = InvalidId;
public int Id
{
get
{
if (m_id == InvalidId)
{
// Leaving double check to have the same amount of computation here
if (m_id == InvalidId)
{
m_id = Interlocked.Increment(ref s_idCounter);
}
}
return m_id;
}
}为了分析性能差异,我将使用基准DotNet
List<NodeWithLock.Node> m_nodeWithLocks =>
Enumerable.Range(1, Count).Select(n => new NodeWithLock.Node()).ToList();
List<NodeNoLock.NoLockNode> m_nodeWithNoLocks =>
Enumerable.Range(1, Count).Select(n => new NodeNoLock.NoLockNode()).ToList();
[Benchmark]
public long NodeWithLock()
{
// m_nodeWithLocks has 5 million instances
return m_nodeWithLocks
.AsParallel()
.WithDegreeOfParallelism(16)
.Select(n => (long)n.Id).Sum();
}
[Benchmark]
public long NodeWithNoLock()
{
// m_nodeWithNoLocks has 5 million instances
return m_nodeWithNoLocks
.AsParallel()
.WithDegreeOfParallelism(16)
.Select(n => (long)n.Id).Sum();
}在这种情况下,NoLockNode 不适合多线程方案,但我们的基准测试也不会尝试同时从不同的线程获取两个实例的 Id。当争用很少发生时,基准测试模拟了真实场景,在大多数情况下,应用程序只是使用已创建的标识符。
| Method | 平均值 | 标准差 |
|---|---|---|
| NodeWithLock | 152.2947 ms | 1.4895 ms |
| NodeWithNoLock | 149.5015 ms | 2.7289 ms |
我们可以看到,差别非常小。CLR 是如何做到获得 100 万个锁而几乎无开销呢?
为了阐明 CLR 行为,让我们用另一个案例来扩展我们的基准测试套件。我们添加另一个Node类,该类在构造函数中调用 GetHashCode 方法(其非重写版本),然后丢弃结果:
public class Node
{
public const int InvalidId = -1;
private static int s_idCounter;
private object syncRoot = new object();
private int m_id = InvalidId;
public Node()
{
GetHashCode();
}
public int Id
{
get
{
if (m_id == InvalidId)
{
lock(this)
{
if (m_id == InvalidId)
{
m_id = Interlocked.Increment(ref s_idCounter);
}
}
}
return m_id;
}
}
}| Method | 平均值 | 标准差 |
|---|---|---|
| NodeWithLock | 152.2947 ms | 1.4895 ms |
| NodeWithNoLock | 149.5015 ms | 2.7289 ms |
| NodeWithLockAndGetHashCode | 541.6314 ms | 4.0445 ms |
GetHashCode调用的结果被丢弃,调用本身不会影响整体的测试时间,因为基准从测量中排除了构造时间。但问题是:有在NodeWithLock这个例子中,为什么锁语句的开销几乎为0,而在NodeWithLockAndGetHashCode中对象实例调用GetHashCode方法时,开销明险不同?
轻量锁、锁膨胀和对象头布局
CLR 中的每个对象都可用于创建关键区域以实现互斥执行。你可能会认为,为了做到这一点,CLR为每个CLR对象创建一个内核对象。但是,这种方法没有意义,因为只有很小一部分对象用作同步的句柄。因此,CLR 按需创建同步所需的重量级的数据结构非常有意义。此外,如果 CLR 不需要冗余数据结构,就不会创建它们。
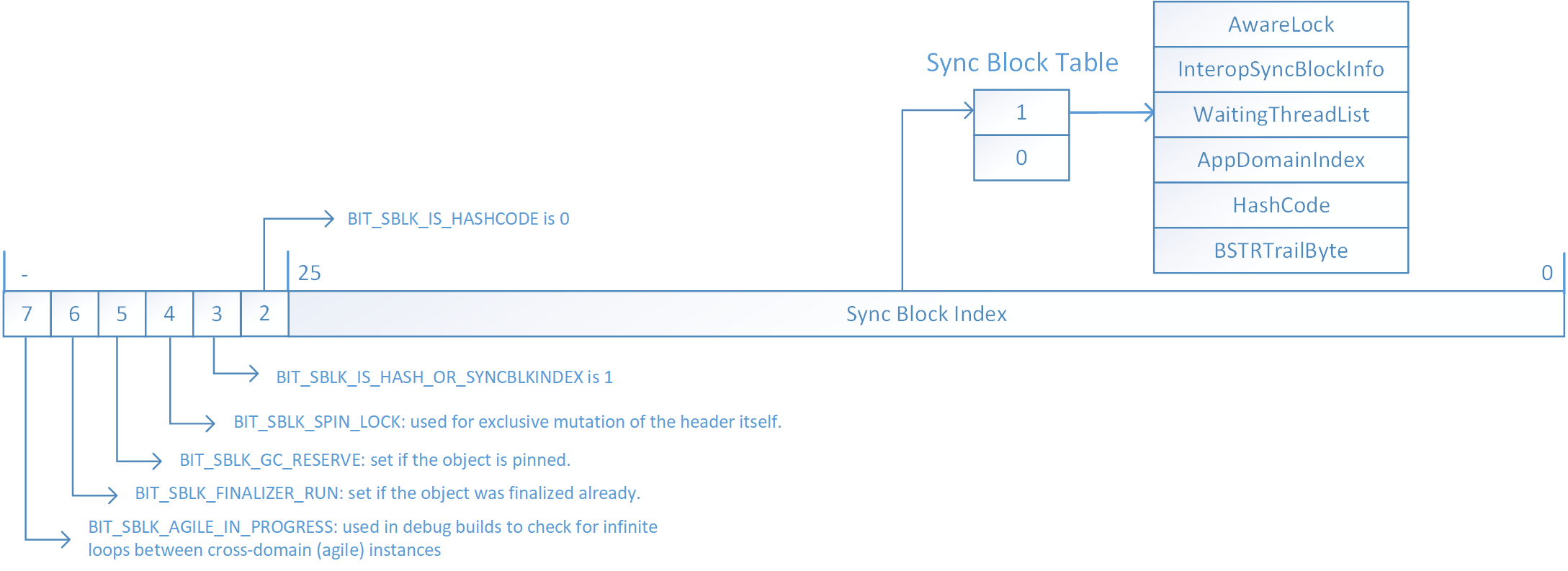
如你所知,每个托管对象都有一个称为对象头的辅助字段。对象头本身可用于不同的目的,并且可以根据当前对象的状态保留不同的信息。
CLR 可以同时存储对象的哈希代码、领域特定信息、与锁相关的数据以及和一些其他内容。显然,4 个字节的对象头根本不足以满足所有这些功能。因此,CLR 将创建一个称为同步块表的辅助数据结构,并且只在对象头本身中保留一个索引。但是 CLR 会尽量避免这种情况,并尝试在标头本身中放置尽可能多的数据。
下面是对象头最重要的字节的布局:

如果BIT_SBLK_IS_HASH_OR_SYNCBLKINDEX位为 0,则头本身保留所有与锁相关的信息,锁称为"轻量锁"。在这种情况下,对象头的总体布局如下:

如果BIT_SBLK_IS_HASH_OR_SYNCBLKINDEX位为 1,为对象创建的同步块或计算哈希代码。如果BIT_SBLK_IS_HASHCODE为 1(第26位),则双字其余部分(0 ~ 25位)是对象的哈希代码,否则,0 ~ 25位表示同步块索引:
译者补充:1字=2字节,双字即为4字节
双字的其余部分说的就是对象头4字节低于26位的部分。上一节我们说了即使64位对象头是8字节,实际也只是用了4个字节。
我们可以使用 WinDbg 和 SoS 扩展来研究轻量锁。首先,我们对一个简单对象的锁语句中停止执行,这不会调用 GetHashCode 方法:
object o = new object();
lock (o)
{
Debugger.Break();
}在 WinDbg 中,我们将运行 .loadby sos clr 来加载 SOS 调试扩展,然后运行两个命令:DumpHeap -thinlock 查看所有轻量锁, DumpObj obj 查看我们在锁语句中使用实例的状态:
0:000> !DumpHeap -thinlock
Address MT Size
02d223e0 725c2104 12 ThinLock owner 1 (00ea5498) Recursive 0
Found 1 objects.
0:000> !DumpObj https://img.qb5200.com/download-x/d 02d223e0
Name: System.Object
MethodTable: 725c2104
ThinLock owner 1 (00ea5498), Recursive 0 至少有两种情况可以将轻量锁升级为"重量锁":
(1) 另一个线程的同步根上的争用,需要创建内核对象;
(2) CLR 无法将所有信息保留在对象标头中,例如,对 GetHashCode 方法的调用。
CLR 监视器实现了一种"混合锁",在创建真正的 Win32 内核对象之前尝试先自旋。以下是来自 Joe Duffy 的《Windows并发编程》中的监视器的简短描述:"在单 CPU 计算机上,监视器实现将执行缩减的旋转等待:当前线程的时间片通过在等待之前调用 SwitchToThread 切换到调度器。在多 CPU 计算机上,监视器每隔一段时间就会产生一个线程,但是在返回到某个线程之前,繁忙的线程会旋转一段时间,使用指数后退方案来控制它重新读取锁状态的频率。所有这一切都是为了在英特尔超线程计算机上正常工作。如果在固定旋转等待期用完后锁仍然不可用,就会尝试将回退到使用基础 Win32 事件的真实等待。我们讨论一下它是如何工作的。
译者补充: CLR使用的是混合锁,先尝试使用轻量锁,若锁长时间被占用,自旋带来的开销会大于用户态到内核态转换带来的开销,此时就会尝试使用重量锁。
译者补充: 换句直白的话来说,单线程下在未获取待锁等待之前,会尝试切换到其他线程,而在多线程下使用锁时,首先会尝试用自旋锁,而自旋的时间以指数变化上升,若最终仍然没有获取到,则会调用实际的win32 内核模式的真实等待时间。
我们可以检查,在这两种情况下,锁膨胀确实发生,一个轻量锁被升级为重量锁:
object o = new object();
// Just need to call GetHashCode and discard the result
o.GetHashCode();
lock (o)
{
Debugger.Break();
}0:000> !dumpheap -thinlock
Address MT Size
Found 0 objects.
0:000> !syncblk
Index SyncBlock MonitorHeld Recursion Owning Thread Info SyncBlock Owner
1 011790a4 1 1 01155498 4ea8 0 02db23e0 System.Object 正如您所看到的,只需在同步对象上调用 GetHashCode,我们将获得不同的结果。现在没有轻量锁,同步根具有与其关联的同步块。
如果其他线程长时间占用锁,我们可以得到相同的结果:
object o = new object();
lock (o)
{
Task.Run(() =>
{
// 线程征用轻量级锁
lock (o) { }
});
// 10 ms 不够,CLR 自旋会超过10ms.
Thread.Sleep(100);
Debugger.Break();
}在这种情况下,会有一样的结果:轻量锁会升级同时会创建同步块。
0:000> !dumpheap -thinlock
Address MT Size
Found 0 objects.
0:000> !syncblk
Index SyncBlock MonitorHeld Recursion Owning Thread Info SyncBlock Owner
6 00d9b378 3 1 00d75498 1884 0 02b323ec System.Object 结论
现在,基准输出应该更容易理解。如果 CLR 可以使用轻量锁,则可以获取数百万个锁,而开销几乎为0。轻量锁非常高效。要获取锁,CLR 将更改对象头中的几个位用来存储线程 ID,等待线程将旋转,直到这些位变为非零。另一方面,如果轻量锁被升级为"重量锁",开销会变得更加明显。特别是当获得重量锁的对象数量相当大时。
微信扫一扫二维码关注订阅号杰哥技术分享
出处:https://www.cnblogs.com/Jack-Blog/p/12259258.html
作者:杰哥很忙
本文使用「CC BY 4.0」创作共享协议。欢迎转载,请在明显位置给出出处及链接。

加载全部内容