关于模型加速的总结
哪些年那些事 人气:0概述
● 模型加速的目标:
a. Increase inference speed:加快推理速度(应用层面)。
b. Reduce model size:压缩模型。
● 关于模型的加速大致可以分为三个方面的加速:
1)平台(支持层面):数学运算(底层)
2)训练前:网络结构的设计
3)训练后:在训练好的模型上进行加速
因为模型加速包含的内容非常广泛,下面只对这三个方面进行简单介绍。
1. 平台(支持):数学运算
(1) Winograd [2015]
● 原理:
用大量低成本操作代替少量高成本操作(乘法操作转为加法操作),虽然运算数量上看起来更多了,但是总的花费是减少的。(Winograd 算法通过减少乘法次数来 实现提速,但是加法的数量会相应增加,同时需要额外的 transform 计算以及存储 transform 矩阵)。
注:在二维卷积上,只适用于小kernel(如2×2、3×3、4×4)。
● 计算过程如下:
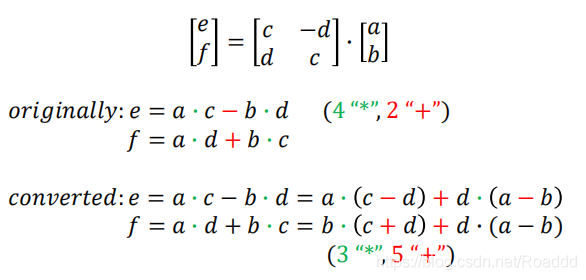
(2)奇异值分解(Singular Value Decomposition,SVD)
较为复杂,有兴趣的可以查阅相关资料。
2. 训练前:网络结构的设计
使用轻量级网络加速模型(如果是检测或者分割等复杂任务,就使用轻量级网络作为Backbone)。可以更好的部署在移动端。
● 常用的轻量级网络:
1)压缩再扩展:SqueezeNet
2)深度可分离卷积:MobileNet系列:
a. MobileNet V1 MobileNet V1详解
b. MobileNet V2 MobileNet V2详解
c. MobileNet V3
3)通道混洗:ShuffleNet系列:
a. ShuffleNet V1
b. ShuffleNet V2
4)网络结构搜索(NAS):Efficient Net
3. 训练后:在训练好的模型上进行加速
(1)Model/Parameter prune(模型剪枝)
剪枝是对已训练好的模型进行裁剪的方法,是目前模型压缩中使用最多的方法,通常是 寻找一种有效的评判手段,来判断参数的重要性,将不重要的 connection 或者 filter 进行裁 剪来减少模型的冗余。剪枝通常能大幅减少参数数量,压缩空间,从而降低计算量。一个典 型的剪枝算法通常有三个阶段,即训练(大型模型),剪枝和微调。在剪枝过程中,根据一 定的标准,对冗余权重进行修剪并保留重要权重,以最大限度地保持精确性。
● 基本步骤:
1)实现原始网络,并将其训练到收敛,保存权重。
2)观察对每一层的权重,判断其对模型的贡献大小,删除贡献较小的 kernel,评判标准可 以是 std,sum(abs),mean 等。
3)当删除部分 kernel 后,会导致输出层的 channel 数变化,需要删除输出层对应 kernel 的 对应 channel。
4)构建剪枝后的网络,加载剪枝后的权重,与原模型对比精准度。
5)使用较小的学习率,rebirth 剪枝后的模型。
6)重复第 1 步
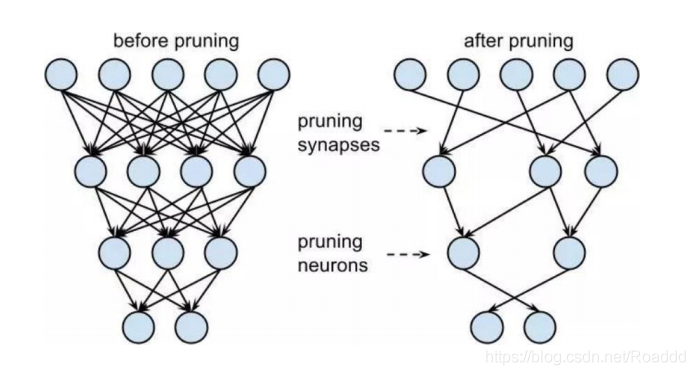
● 方法:Network Slimming
(2)Model Quantization(模型量化)
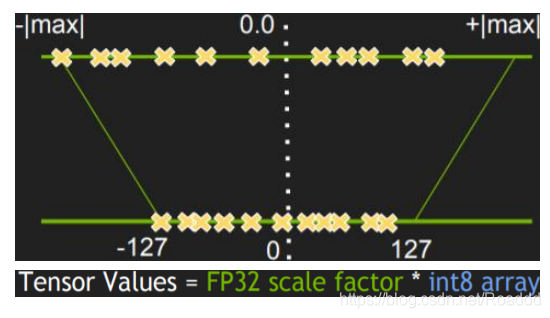
● 什么是模型量化?
模型量化即以较低的推理精度损失将连续取值(或者大量可能的离散值)的浮点型模型 权重或流经模型的张量数据定点近似(通常为 int8)为有限多个(或较少的)离散值的过程。 它是以更少位数的数据类型用于近似表示 32 位有限范围浮点型数据的过程,而模型的输入 输出依然是浮点型。从而达到减少模型尺寸大小、减少模型内存消耗及加快模型推理速度等 目标。
● 为什么要进行模型量化?
Resnet-152 神经网络的提出证明了越宽越深越大的模型往往比越窄越浅越小的模型精度 要高,但是越宽越深越大的模型对计算资源要求更高,而现在模型应用越来越倾向于从云端 部署到边缘侧,受限于边缘侧设备的计算资源,我们不得不考虑设备存储空间(storage)、 设备内存大小(memory)、设备运行功耗(power)及时延性(latency)等等问题,特别是 在移动终端和嵌入式设备等资源受限的边缘侧应用场景中更加需要我们进行优化。模型量化 就是为了解决这类问题。
● 模型量化的好处
1) 减小模型尺寸:如 8 位整型量化可减小 75%的模型大小
2) 减少存储空间:在边缘侧存储空间不足时更具有意义。
3) 易于在线升级:模型更小意味着更加容易传输。
4) 减少内存耗用:更小的模型大小意味着不需要更多的内存。
5) 加快推理速度:访问一次 32位浮点型可以访问四次 int8 整型,整型运算比浮点型运 算更快。
6) 减少设备功耗:内存耗用少了,推理速度快了,自然减少了设备功耗。
7) 支持微处理器:有些微处理器属于 8 位的,低功耗运行浮点运算速度慢,需要进行 8bit 量化。
● 模型量化的缺点
1) 模型量化会损失一定的精度:虽然微调后可以减少精度损失,但推理精度确实下降。
2) 模型量化增加了操作复杂度:在量化时需要做一些特殊的处理,否则精度损失更严 重。
● 量化方法:TensorRT
TensorRT 是一个高性能的深度学习推理(Inference)优化器,可以为深度学习应用提供 低延迟、高吞吐率的部署推理。TensorRT 可用于对超大规模数据中心、嵌入式平台或自动 驾驶平台进行推理加速。TensorRT 现已能支持 TensorFlow、Caffe、Mxnet、Pytorch 等几乎 所有的深度学习框架,将 TensorRT 和 NVIDIA 的 GPU 结合起来,能在几乎所有的框架中进 行快速和高效的部署推理。
在推理过程中,基于 TensorRT 的应用程序的执行速度可比 CPU 平台的速度快 40 倍。 借助 TensorRT,您可以优化在所有主要框架中训练的神经网络模型,精确校正低精度,并 最终将模型部署到超大规模数据中心、嵌入式或汽车产品平台中。
TensorRT 针对多种深度学习推理应用的生产部署提供 INT8 和 FP16 优化,例如视频 流式传输、语音识别、推荐和自然语言处理。推理精度降低后可显著减少应用延迟,这恰巧 满足了许多实时服务、自动和嵌入式应用的要求。
TensorRT 是对训练好的模型进行优化。 TensorRT 就只是 推理优化器。当你的网络训 练完之后,可以将训练模型文件直接丢进 TensorRT 中,而不再需要依赖深度学习框架(Caffe, TensorFlow 等)。
可以认为 tensorRT 是一个只有前向传播的深度学习框架,这个框架可以将 Caffe,
TensorFlow 的网络模型解析,然后与 tensorRT 中对应的层进行一一映射,把其他框架的模 型统一全部 转换到 tensorRT 中,然后在 tensorRT 中可以针对 NVIDIA 自家 GPU 实施优化 策略,并进行部署加速。
目前 TensorRT4.0 几乎可以支持所有常用的深度学习框架,对于 caffe 和 TensorFlow 来 说,tensorRT 可以直接解析他们的网络模型;对于 caffe2,pytorch,mxnet,chainer,CNTK 等框架则是首先要将模型转为 ONNX 的通用深度学习模型,然后对 ONNX 模型做解析。 而 tensorflow 和 MATLAB 已经将 TensorRT 集成到框架中去了。
关于TensorRT的更详细介绍以及安装过程可以参考我的另外两篇文章:TensorRT详解 、TensorRT安装、测试
● ONNX介绍:
ONNX(Open Neural Network Exchange )是微软和 Facebook 携手开发的开放式神经网 络交换工具,也就是说不管用什么框架训练,只要转换为 ONNX 模型,就可以放在其他框 架上面去 inference。这是一种统一的神经网络模型定义和保存方式,上面提到的除了 tensorflow 之外的其他框架官方应该都对 onnx 做了支持,而 ONNX 自己开发了对 tensorflow 的支持。从深度学习框架方面来说,这是各大厂商对抗谷歌 tensorflow 垄断地位的一种有效 方式;从研究人员和开发者方面来说,这可以使开发者轻易地在不同机器学习工具之间进行 转换,并为项目选择最好的组合方式,加快从研究到生产的速度。
加载全部内容